 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization without Trees using Multiset Tagging and Latent Permutations
May 26, 2023Seq2seq models have been shown to struggle with compositional generalization in semantic parsing, i.e. generalizing to unseen compositions of phenomena that the model handles correctly in isolation. We phrase semantic parsing as a two-step process: we first tag each input token with a multiset of output tokens. Then we arrange the tokens into an output sequence using a new way of parameterizing and predicting permutations. We formulate predicting a permutation as solving a regularized linear program and we backpropagate through the solver. In contrast to prior work, our approach does not place a priori restrictions on possible permutations, making it very expressive. Our model outperforms pretrained seq2seq models and prior work on realistic semantic parsing tasks that require generalization to longer examples. We also outperform non-tree-based models on structural generalization on the COGS benchmark. For the first time, we show that a model without an inductive bias provided by trees achieves high accuracy on generalization to deeper recursion.
Recursive Neural Networks with Bottlenecks Diagnose (Non-)Compositionality
Jan 31, 2023A recent line of work in NLP focuses on the (dis)ability of models to generalise compositionally for artificial languages. However, when considering natural language tasks, the data involved is not strictly, or locally, compositional. Quantifying the compositionality of data is a challenging task, which has been investigated primarily for short utterances. We use recursive neural models (Tree-LSTMs) with bottlenecks that limit the transfer of information between nodes. We illustrate that comparing data's representations in models with and without the bottleneck can be used to produce a compositionality metric. The procedure is applied to the evaluation of arithmetic expressions using synthetic data, and sentiment classification using natural language data. We demonstrate that compression through a bottleneck impacts non-compositional examples disproportionately and then use the bottleneck compositionality metric (BCM) to distinguish compositional from non-compositional samples, yielding a compositionality ranking over a dataset.
Hierarchical Phrase-based Sequence-to-Sequence Learning
Nov 16, 2022We describe a neural transducer that maintains the flexibility of standard sequence-to-sequence (seq2seq) models while incorporating hierarchical phrases as a source of inductive bias during training and as explicit constraints during inference. Our approach trains two models: a discriminative parser based on a bracketing transduction grammar whose derivation tree hierarchically aligns source and target phrases, and a neural seq2seq model that learns to translate the aligned phrases one-by-one. We use the same seq2seq model to translate at all phrase scales, which results in two inference modes: one mode in which the parser is discarded and only the seq2seq component is used at the sequence-level, and another in which the parser is combined with the seq2seq model. Decoding in the latter mode is done with the cube-pruned CKY algorithm, which is more involved but can make use of new translation rules during inference. We formalize our model as a source-conditioned synchronous grammar and develop an efficient variational inference algorithm for training. When applied on top of both randomly initialized and pretrained seq2seq models, we find that both inference modes performs well compared to baselines on small scale machine translation benchmarks.
Compositional Generalisation with Structured Reordering and Fertility Layers
Oct 06, 2022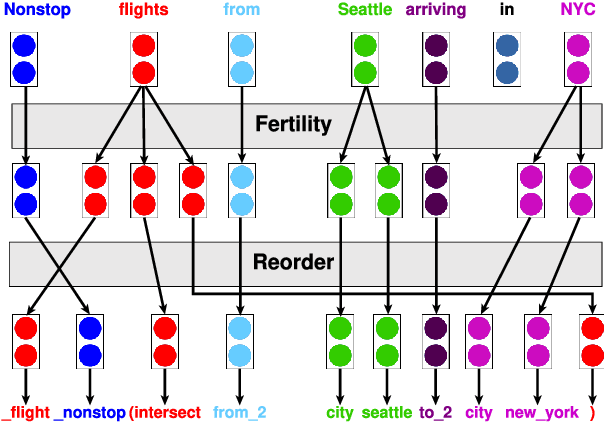
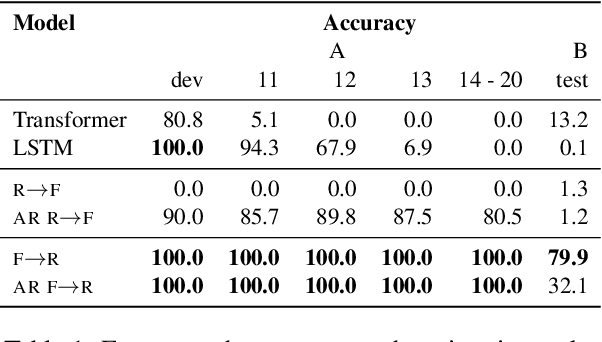
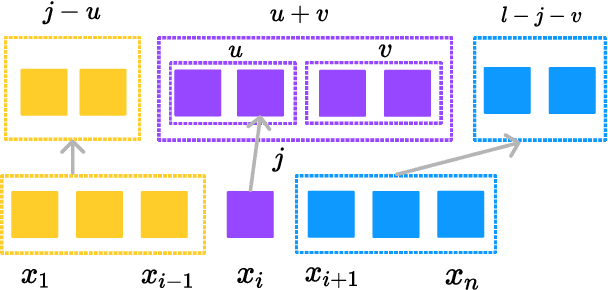
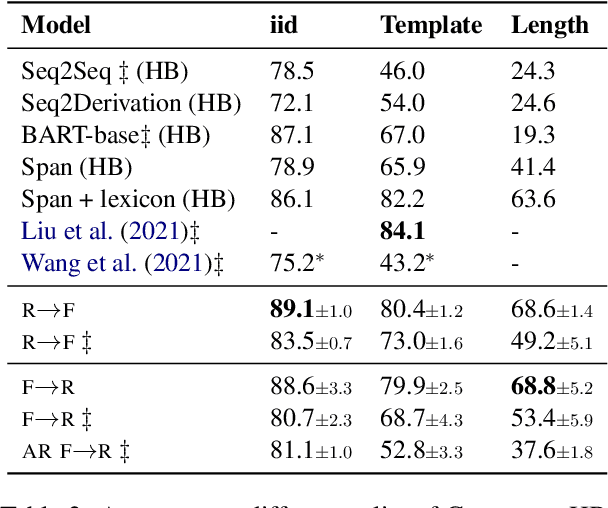
Seq2seq models have been shown to struggle with compositional generalisation, i.e. generalising to new and potentially more complex structures than seen during training. Taking inspiration from grammar-based models that excel at compositional generalisation, we present a flexible end-to-end differentiable neural model that composes two structural operations: a fertility step, which we introduce in this work, and a reordering step based on previous work (Wang et al., 2021). Our model outperforms seq2seq models by a wide margin on challenging compositional splits of realistic semantic parsing tasks that require generalisation to longer examples. It also compares favourably to other models targeting compositional generalisation.
Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation
May 30, 2022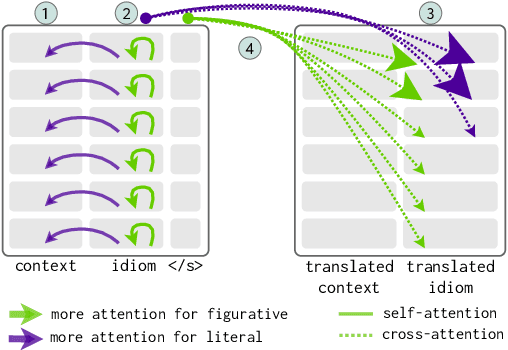
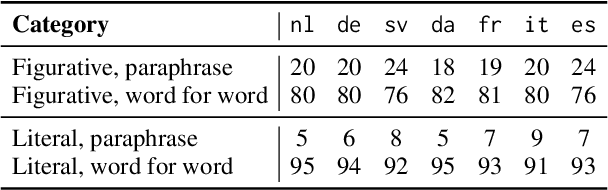
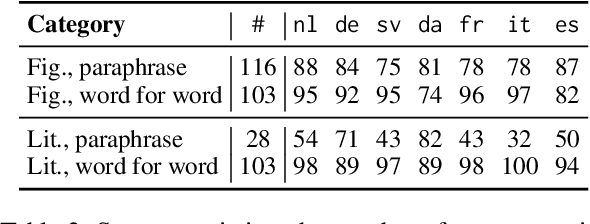
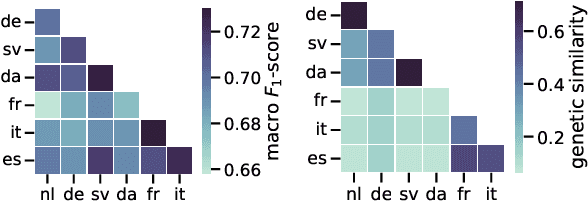
Unlike literal expressions, idioms' meanings do not directly follow from their parts, posing a challenge for neural machine translation (NMT). NMT models are often unable to translate idioms accurately and over-generate compositional, literal translations. In this work, we investigate whether the non-compositionality of idioms is reflected in the mechanics of the dominant NMT model, Transformer, by analysing the hidden states and attention patterns for models with English as source language and one of seven European languages as target language. When Transformer emits a non-literal translation - i.e. identifies the expression as idiomatic - the encoder processes idioms more strongly as single lexical units compared to literal expressions. This manifests in idioms' parts being grouped through attention and in reduced interaction between idioms and their context. In the decoder's cross-attention, figurative inputs result in reduced attention on source-side tokens. These results suggest that Transformer's tendency to process idioms as compositional expressions contributes to literal translations of idioms.
Sparse Interventions in Language Models with Differentiable Masking
Dec 13, 2021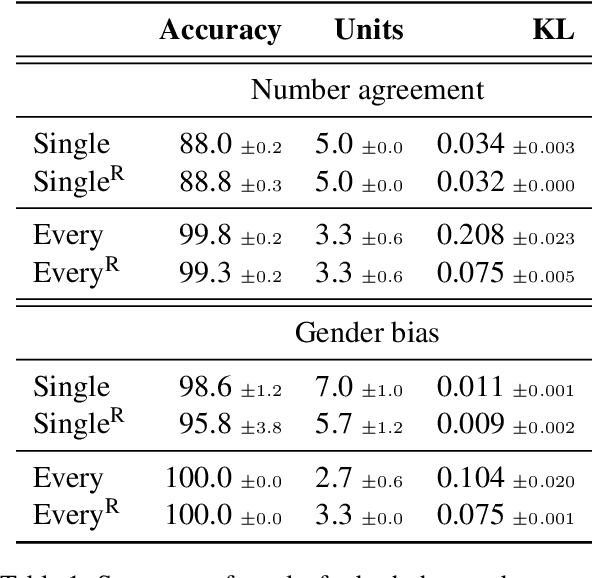
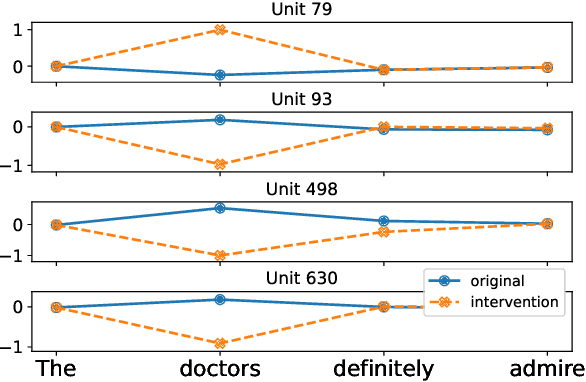
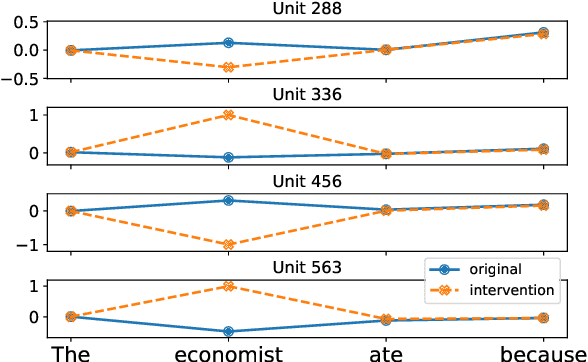
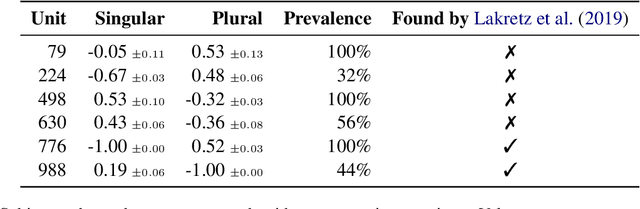
There has been a lot of interest in understanding what information is captured by hidden representations of language models (LMs). Typically, interpretation methods i) do not guarantee that the model actually uses the encoded information, and ii) do not discover small subsets of neurons responsible for a considered phenomenon. Inspired by causal mediation analysis, we propose a method that discovers within a neural LM a small subset of neurons responsible for a particular linguistic phenomenon, i.e., subsets causing a change in the corresponding token emission probabilities. We use a differentiable relaxation to approximately search through the combinatorial space. An $L_0$ regularization term ensures that the search converges to discrete and sparse solutions. We apply our method to analyze subject-verb number agreement and gender bias detection in LSTMs. We observe that it is fast and finds better solutions than the alternative (REINFORCE). Our experiments confirm that each of these phenomenons is mediated through a small subset of neurons that do not play any other discernible role.
Learning Opinion Summarizers by Selecting Informative Reviews
Sep 09, 2021
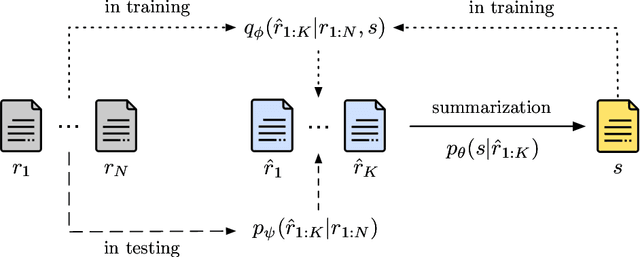
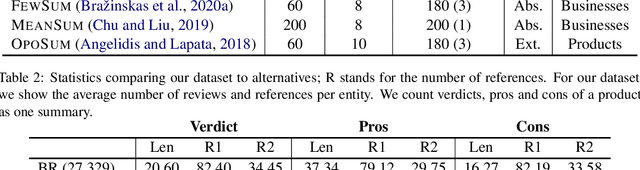
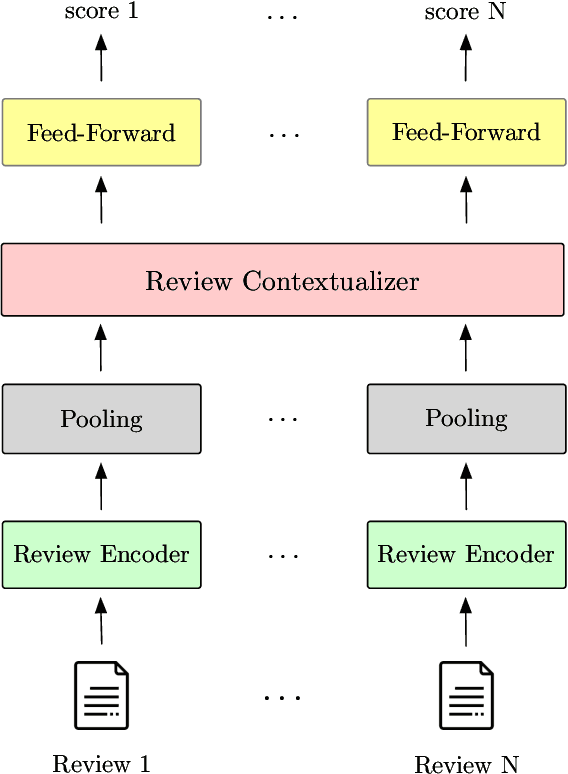
Opinion summarization has been traditionally approached with unsupervised, weakly-supervised and few-shot learning techniques. In this work, we collect a large dataset of summaries paired with user reviews for over 31,000 products, enabling supervised training. However, the number of reviews per product is large (320 on average), making summarization - and especially training a summarizer - impractical. Moreover, the content of many reviews is not reflected in the human-written summaries, and, thus, the summarizer trained on random review subsets hallucinates. In order to deal with both of these challenges, we formulate the task as jointly learning to select informative subsets of reviews and summarizing the opinions expressed in these subsets. The choice of the review subset is treated as a latent variable, predicted by a small and simple selector. The subset is then fed into a more powerful summarizer. For joint training, we use amortized variational inference and policy gradient methods. Our experiments demonstrate the importance of selecting informative reviews resulting in improved quality of summaries and reduced hallucinations.
Highly Parallel Autoregressive Entity Linking with Discriminative Correction
Sep 08, 2021
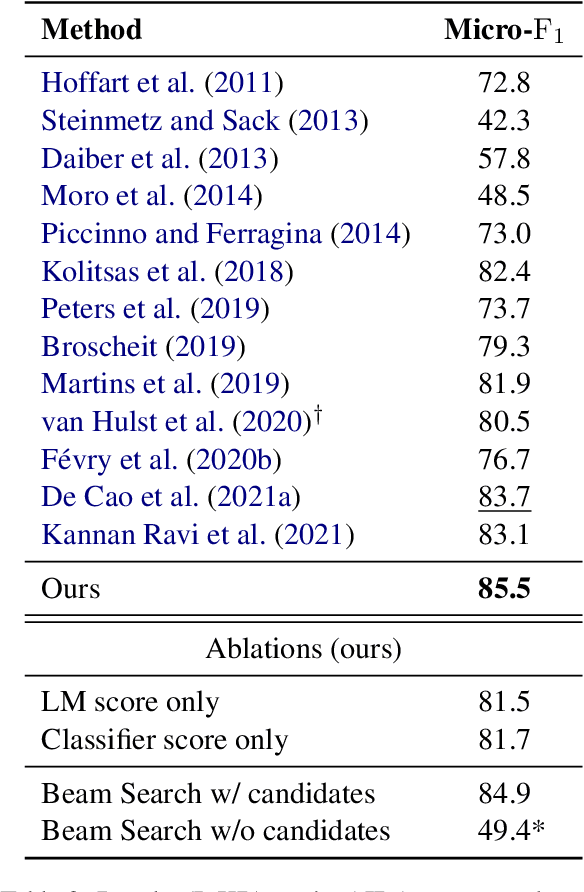

Generative approaches have been recently shown to be effective for both Entity Disambiguation and Entity Linking (i.e., joint mention detection and disambiguation). However, the previously proposed autoregressive formulation for EL suffers from i) high computational cost due to a complex (deep) decoder, ii) non-parallelizable decoding that scales with the source sequence length, and iii) the need for training on a large amount of data. In this work, we propose a very efficient approach that parallelizes autoregressive linking across all potential mentions and relies on a shallow and efficient decoder. Moreover, we augment the generative objective with an extra discriminative component, i.e., a correction term which lets us directly optimize the generator's ranking. When taken together, these techniques tackle all the above issues: our model is >70 times faster and more accurate than the previous generative method, outperforming state-of-the-art approaches on the standard English dataset AIDA-CoNLL. Source code available at https://github.com/nicola-decao/efficient-autoregressive-EL
Language Modeling, Lexical Translation, Reordering: The Training Process of NMT through the Lens of Classical SMT
Sep 03, 2021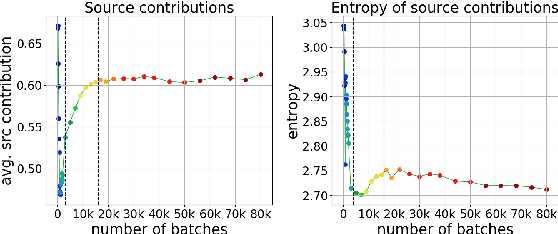
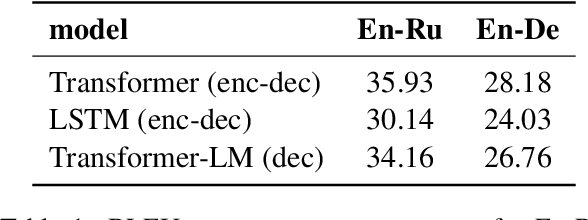
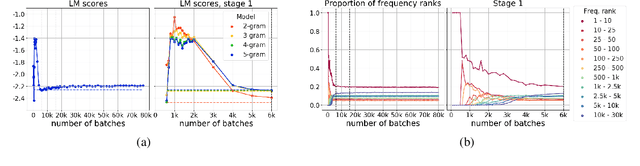

Differently from the traditional statistical MT that decomposes the translation task into distinct separately learned components, neural machine translation uses a single neural network to model the entire translation process. Despite neural machine translation being de-facto standard, it is still not clear how NMT models acquire different competences over the course of training, and how this mirrors the different models in traditional SMT. In this work, we look at the competences related to three core SMT components and find that during training, NMT first focuses on learning target-side language modeling, then improves translation quality approaching word-by-word translation, and finally learns more complicated reordering patterns. We show that this behavior holds for several models and language pairs. Additionally, we explain how such an understanding of the training process can be useful in practice and, as an example, show how it can be used to improve vanilla non-autoregressive neural machine translation by guiding teacher model selection.
Meta-Learning to Compositionally Generalize
Jun 29, 2021
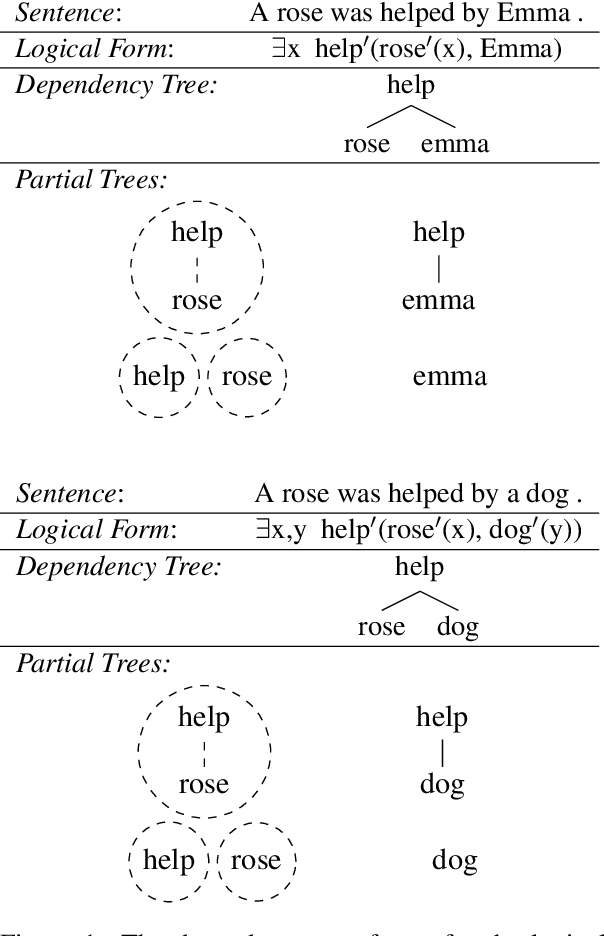
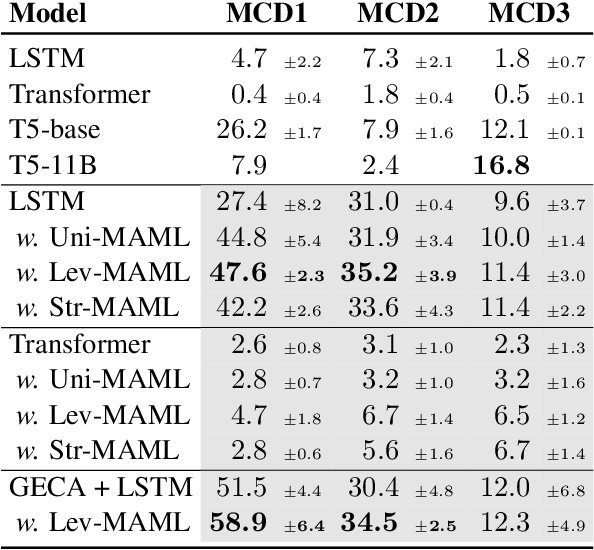
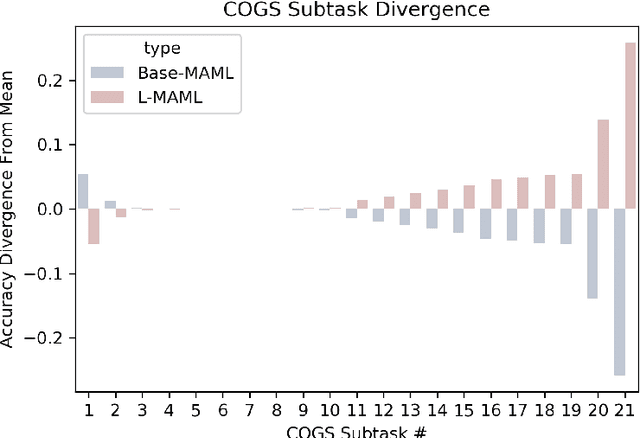
Natural language is compositional; the meaning of a sentence is a function of the meaning of its parts. This property allows humans to create and interpret novel sentences, generalizing robustly outside their prior experience. Neural networks have been shown to struggle with this kind of generalization, in particular performing poorly on tasks designed to assess compositional generalization (i.e. where training and testing distributions differ in ways that would be trivial for a compositional strategy to resolve). Their poor performance on these tasks may in part be due to the nature of supervised learning which assumes training and testing data to be drawn from the same distribution. We implement a meta-learning augmented version of supervised learning whose objective directly optimizes for out-of-distribution generalization. We construct pairs of tasks for meta-learning by sub-sampling existing training data. Each pair of tasks is constructed to contain relevant examples, as determined by a similarity metric, in an effort to inhibit models from memorizing their input. Experimental results on the COGS and SCAN datasets show that our similarity-driven meta-learning can improve generalization performance.