 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic World Models
Oct 22, 2025Planning with world models offers a powerful paradigm for robotic control. Conventional approaches train a model to predict future frames conditioned on current frames and actions, which can then be used for planning. However, the objective of predicting future pixels is often at odds with the actual planning objective; strong pixel reconstruction does not always correlate with good planning decisions. This paper posits that instead of reconstructing future frames as pixels, world models only need to predict task-relevant semantic information about the future. For such prediction the paper poses world modeling as a visual question answering problem about semantic information in future frames. This perspective allows world modeling to be approached with the same tools underlying vision language models. Thus vision language models can be trained as "semantic" world models through a supervised finetuning process on image-action-text data, enabling planning for decision-making while inheriting many of the generalization and robustness properties from the pretrained vision-language models. The paper demonstrates how such a semantic world model can be used for policy improvement on open-ended robotics tasks, leading to significant generalization improvements over typical paradigms of reconstruction-based action-conditional world modeling. Website available at https://weirdlabuw.github.io/swm.
N-Agent Ad Hoc Teamwork
Apr 16, 2024Current approaches to learning cooperative behaviors in multi-agent settings assume relatively restrictive settings. In standard fully cooperative multi-agent reinforcement learning, the learning algorithm controls \textit{all} agents in the scenario, while in ad hoc teamwork, the learning algorithm usually assumes control over only a $\textit{single}$ agent in the scenario. However, many cooperative settings in the real world are much less restrictive. For example, in an autonomous driving scenario, a company might train its cars with the same learning algorithm, yet once on the road, these cars must cooperate with cars from another company. Towards generalizing the class of scenarios that cooperative learning methods can address, we introduce $N$-agent ad hoc teamwork, in which a set of autonomous agents must interact and cooperate with dynamically varying numbers and types of teammates at evaluation time. This paper formalizes the problem, and proposes the $\textit{Policy Optimization with Agent Modelling}$ (POAM) algorithm. POAM is a policy gradient, multi-agent reinforcement learning approach to the NAHT problem, that enables adaptation to diverse teammate behaviors by learning representations of teammate behaviors. Empirical evaluation on StarCraft II tasks shows that POAM improves cooperative task returns compared to baseline approaches, and enables out-of-distribution generalization to unseen teammates.
$f$-Policy Gradients: A General Framework for Goal Conditioned RL using $f$-Divergences
Oct 10, 2023



Goal-Conditioned Reinforcement Learning (RL) problems often have access to sparse rewards where the agent receives a reward signal only when it has achieved the goal, making policy optimization a difficult problem. Several works augment this sparse reward with a learned dense reward function, but this can lead to sub-optimal policies if the reward is misaligned. Moreover, recent works have demonstrated that effective shaping rewards for a particular problem can depend on the underlying learning algorithm. This paper introduces a novel way to encourage exploration called $f$-Policy Gradients, or $f$-PG. $f$-PG minimizes the f-divergence between the agent's state visitation distribution and the goal, which we show can lead to an optimal policy. We derive gradients for various f-divergences to optimize this objective. Our learning paradigm provides dense learning signals for exploration in sparse reward settings. We further introduce an entropy-regularized policy optimization objective, that we call $state$-MaxEnt RL (or $s$-MaxEnt RL) as a special case of our objective. We show that several metric-based shaping rewards like L2 can be used with $s$-MaxEnt RL, providing a common ground to study such metric-based shaping rewards with efficient exploration. We find that $f$-PG has better performance compared to standard policy gradient methods on a challenging gridworld as well as the Point Maze and FetchReach environments. More information on our website https://agarwalsiddhant10.github.io/projects/fpg.html.
ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning
Nov 08, 2022Given a dataset of expert agent interactions with an environment of interest, a viable method to extract an effective agent policy is to estimate the maximum likelihood policy indicated by this data. This approach is commonly referred to as behavioral cloning (BC). In this work, we describe a key disadvantage of BC that arises due to the maximum likelihood objective function; namely that BC is mean-seeking with respect to the state-conditional expert action distribution when the learner's policy is represented with a Gaussian. To address this issue, we introduce a modified version of BC, Adversarial Behavioral Cloning (ABC), that exhibits mode-seeking behavior by incorporating elements of GAN (generative adversarial network) training. We evaluate ABC on toy domains and a domain based on Hopper from the DeepMind Control suite, and show that it outperforms standard BC by being mode-seeking in nature.
DM$^2$: Distributed Multi-Agent Reinforcement Learning for Distribution Matching
Jun 01, 2022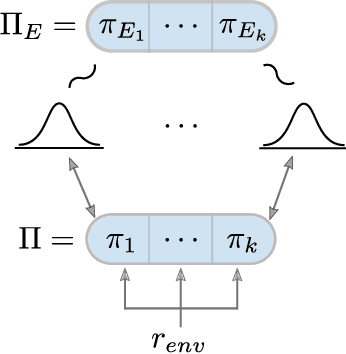

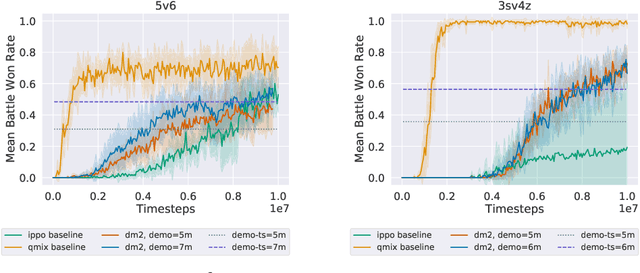
Current approaches to multi-agent cooperation rely heavily on centralized mechanisms or explicit communication protocols to ensure convergence. This paper studies the problem of distributed multi-agent learning without resorting to explicit coordination schemes. The proposed algorithm (DM$^2$) leverages distribution matching to facilitate independent agents' coordination. Each individual agent matches a target distribution of concurrently sampled trajectories from a joint expert policy. The theoretical analysis shows that under some conditions, if each agent optimizes their individual distribution matching objective, the agents increase a lower bound on the objective of matching the joint expert policy, allowing convergence to the joint expert policy. Further, if the distribution matching objective is aligned with a joint task, a combination of environment reward and distribution matching reward leads to the same equilibrium. Experimental validation on the StarCraft domain shows that combining the reward for distribution matching with the environment reward allows agents to outperform a fully distributed baseline. Additional experiments probe the conditions under which expert demonstrations need to be sampled in order to outperform the fully distributed baseline.
Wasserstein Distance Maximizing Intrinsic Control
Oct 28, 2021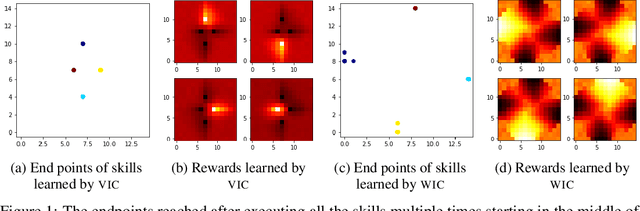
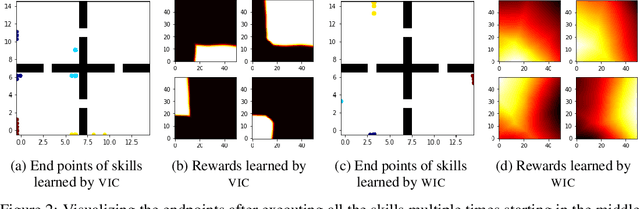
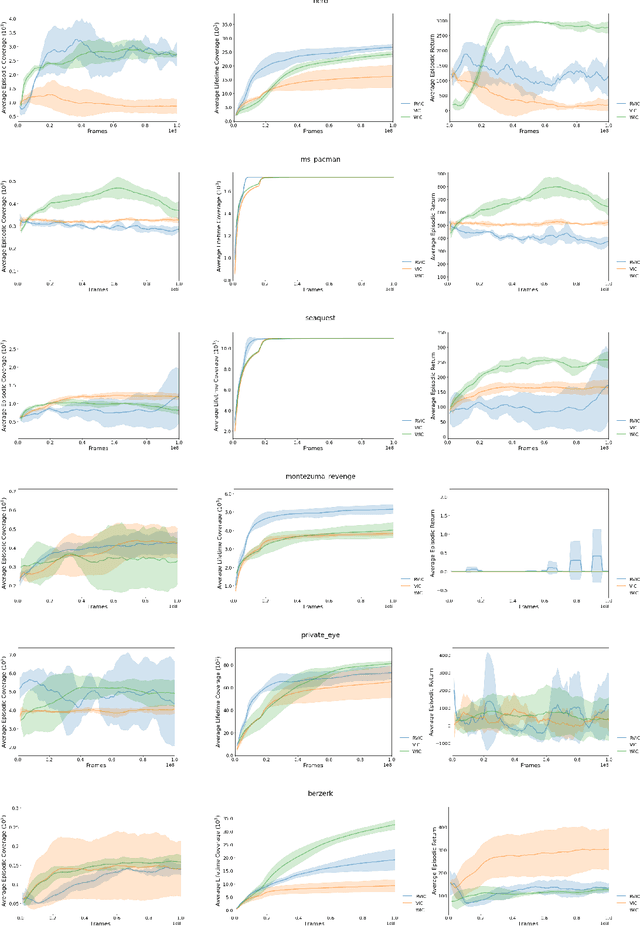
This paper deals with the problem of learning a skill-conditioned policy that acts meaningfully in the absence of a reward signal. Mutual information based objectives have shown some success in learning skills that reach a diverse set of states in this setting. These objectives include a KL-divergence term, which is maximized by visiting distinct states even if those states are not far apart in the MDP. This paper presents an approach that rewards the agent for learning skills that maximize the Wasserstein distance of their state visitation from the start state of the skill. It shows that such an objective leads to a policy that covers more distance in the MDP than diversity based objectives, and validates the results on a variety of Atari environments.
Adversarial Intrinsic Motivation for Reinforcement Learning
May 30, 2021
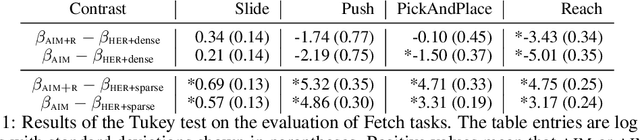
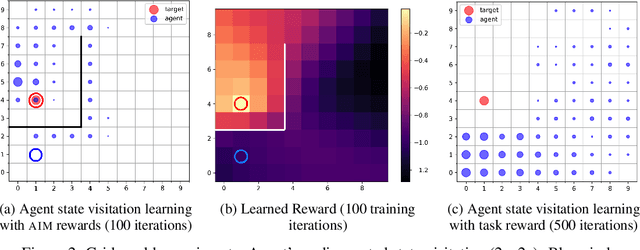
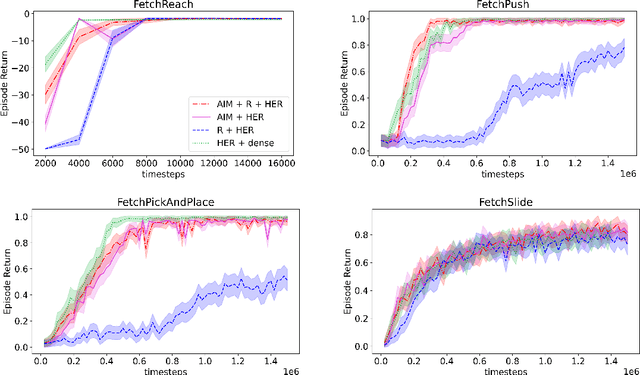
Learning with an objective to minimize the mismatch with a reference distribution has been shown to be useful for generative modeling and imitation learning. In this paper, we investigate whether one such objective, the Wasserstein-1 distance between a policy's state visitation distribution and a target distribution, can be utilized effectively for reinforcement learning (RL) tasks. Specifically, this paper focuses on goal-conditioned reinforcement learning where the idealized (unachievable) target distribution has full measure at the goal. We introduce a quasimetric specific to Markov Decision Processes (MDPs), and show that the policy that minimizes the Wasserstein-1 distance of its state visitation distribution to this target distribution under this quasimetric is the policy that reaches the goal in as few steps as possible. Our approach, termed Adversarial Intrinsic Motivation (AIM), estimates this Wasserstein-1 distance through its dual objective and uses it to compute a supplemental reward function. Our experiments show that this reward function changes smoothly with respect to transitions in the MDP and assists the agent in learning. Additionally, we combine AIM with Hindsight Experience Replay (HER) and show that the resulting algorithm accelerates learning significantly on several simulated robotics tasks when compared to HER with a sparse positive reward at the goal state.
Reducing Sampling Error in Batch Temporal Difference Learning
Aug 15, 2020Temporal difference (TD) learning is one of the main foundations of modern reinforcement learning. This paper studies the use of TD(0), a canonical TD algorithm, to estimate the value function of a given policy from a batch of data. In this batch setting, we show that TD(0) may converge to an inaccurate value function because the update following an action is weighted according to the number of times that action occurred in the batch -- not the true probability of the action under the given policy. To address this limitation, we introduce \textit{policy sampling error corrected}-TD(0) (PSEC-TD(0)). PSEC-TD(0) first estimates the empirical distribution of actions in each state in the batch and then uses importance sampling to correct for the mismatch between the empirical weighting and the correct weighting for updates following each action. We refine the concept of a certainty-equivalence estimate and argue that PSEC-TD(0) is a more data efficient estimator than TD(0) for a fixed batch of data. Finally, we conduct an empirical evaluation of PSEC-TD(0) on three batch value function learning tasks, with a hyperparameter sensitivity analysis, and show that PSEC-TD(0) produces value function estimates with lower mean squared error than TD(0).
An Imitation from Observation Approach to Sim-to-Real Transfer
Aug 04, 2020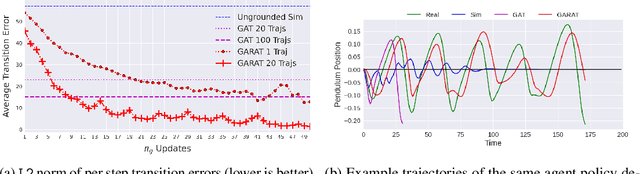


The sim to real transfer problem deals with leveraging large amounts of inexpensive simulation experience to help artificial agents learn behaviors intended for the real world more efficiently. One approach to sim-to-real transfer is using interactions with the real world to make the simulator more realistic, called grounded sim to-real transfer. In this paper, we show that a particular grounded sim-to-real approach, grounded action transformation, is closely related to the problem of imitation from observation IfO, learning behaviors that mimic the observations of behavior demonstrations. After establishing this relationship, we hypothesize that recent state-of-the-art approaches from the IfO literature can be effectively repurposed for such grounded sim-to-real transfer. To validate our hypothesis we derive a new sim-to-real transfer algorithm - generative adversarial reinforced action transformation (GARAT) - based on adversarial imitation from observation techniques. We run experiments in several simulation domains with mismatched dynamics, and find that agents trained with GARAT achieve higher returns in the real world compared to existing black-box sim-to-real methods
Multi-Preference Actor Critic
Apr 05, 2019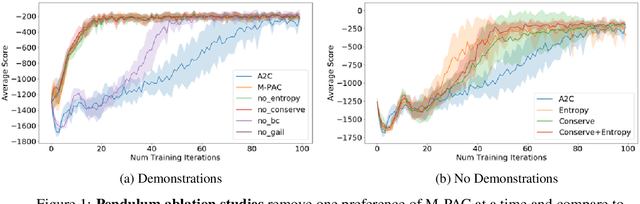
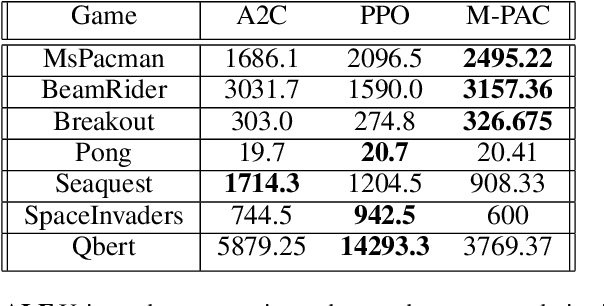
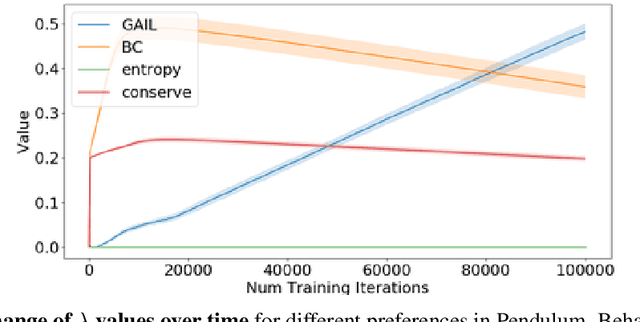
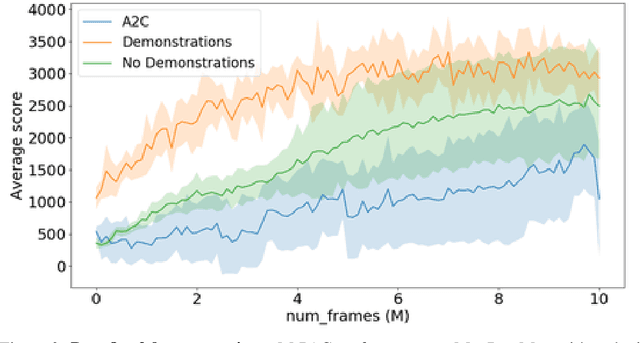
Policy gradient algorithms typically combine discounted future rewards with an estimated value function, to compute the direction and magnitude of parameter updates. However, for most Reinforcement Learning tasks, humans can provide additional insight to constrain the policy learning. We introduce a general method to incorporate multiple different feedback channels into a single policy gradient loss. In our formulation, the Multi-Preference Actor Critic (M-PAC), these different types of feedback are implemented as constraints on the policy. We use a Lagrangian relaxation to satisfy these constraints using gradient descent while learning a policy that maximizes rewards. Experiments in Atari and Pendulum verify that constraints are being respected and can accelerate the learning process.