 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Text-To-Image Diffusion Models for Class-Wise Spurious Feature Generation
Feb 13, 2024We propose a method for generating spurious features by leveraging large-scale text-to-image diffusion models. Although the previous work detects spurious features in a large-scale dataset like ImageNet and introduces Spurious ImageNet, we found that not all spurious images are spurious across different classifiers. Although spurious images help measure the reliance of a classifier, filtering many images from the Internet to find more spurious features is time-consuming. To this end, we utilize an existing approach of personalizing large-scale text-to-image diffusion models with available discovered spurious images and propose a new spurious feature similarity loss based on neural features of an adversarially robust model. Precisely, we fine-tune Stable Diffusion with several reference images from Spurious ImageNet with a modified objective incorporating the proposed spurious-feature similarity loss. Experiment results show that our method can generate spurious images that are consistently spurious across different classifiers. Moreover, the generated spurious images are visually similar to reference images from Spurious ImageNet.
Enhancing Robustness of LLM-Synthetic Text Detectors for Academic Writing: A Comprehensive Analysis
Jan 16, 2024The emergence of large language models (LLMs), such as Generative Pre-trained Transformer 4 (GPT-4) used by ChatGPT, has profoundly impacted the academic and broader community. While these models offer numerous advantages in terms of revolutionizing work and study methods, they have also garnered significant attention due to their potential negative consequences. One example is generating academic reports or papers with little to no human contribution. Consequently, researchers have focused on developing detectors to address the misuse of LLMs. However, most existing methods prioritize achieving higher accuracy on restricted datasets, neglecting the crucial aspect of generalizability. This limitation hinders their practical application in real-life scenarios where reliability is paramount. In this paper, we present a comprehensive analysis of the impact of prompts on the text generated by LLMs and highlight the potential lack of robustness in one of the current state-of-the-art GPT detectors. To mitigate these issues concerning the misuse of LLMs in academic writing, we propose a reference-based Siamese detector named Synthetic-Siamese which takes a pair of texts, one as the inquiry and the other as the reference. Our method effectively addresses the lack of robustness of previous detectors (OpenAI detector and DetectGPT) and significantly improves the baseline performances in realistic academic writing scenarios by approximately 67% to 95%.
Stability Analysis of ChatGPT-based Sentiment Analysis in AI Quality Assurance
Jan 15, 2024In the era of large AI models, the complex architecture and vast parameters present substantial challenges for effective AI quality management (AIQM), e.g. large language model (LLM). This paper focuses on investigating the quality assurance of a specific LLM-based AI product--a ChatGPT-based sentiment analysis system. The study delves into stability issues related to both the operation and robustness of the expansive AI model on which ChatGPT is based. Experimental analysis is conducted using benchmark datasets for sentiment analysis. The results reveal that the constructed ChatGPT-based sentiment analysis system exhibits uncertainty, which is attributed to various operational factors. It demonstrated that the system also exhibits stability issues in handling conventional small text attacks involving robustness.
Cross-Attention Watermarking of Large Language Models
Jan 12, 2024



A new approach to linguistic watermarking of language models is presented in which information is imperceptibly inserted into the output text while preserving its readability and original meaning. A cross-attention mechanism is used to embed watermarks in the text during inference. Two methods using cross-attention are presented that minimize the effect of watermarking on the performance of a pretrained model. Exploration of different training strategies for optimizing the watermarking and of the challenges and implications of applying this approach in real-world scenarios clarified the tradeoff between watermark robustness and text quality. Watermark selection substantially affects the generated output for high entropy sentences. This proactive watermarking approach has potential application in future model development.
Surface Normal Estimation with Transformers
Jan 11, 2024We propose the use of a Transformer to accurately predict normals from point clouds with noise and density variations. Previous learning-based methods utilize PointNet variants to explicitly extract multi-scale features at different input scales, then focus on a surface fitting method by which local point cloud neighborhoods are fitted to a geometric surface approximated by either a polynomial function or a multi-layer perceptron (MLP). However, fitting surfaces to fixed-order polynomial functions can suffer from overfitting or underfitting, and learning MLP-represented hyper-surfaces requires pre-generated per-point weights. To avoid these limitations, we first unify the design choices in previous works and then propose a simplified Transformer-based model to extract richer and more robust geometric features for the surface normal estimation task. Through extensive experiments, we demonstrate that our Transformer-based method achieves state-of-the-art performance on both the synthetic shape dataset PCPNet, and the real-world indoor scene dataset SceneNN, exhibiting more noise-resilient behavior and significantly faster inference. Most importantly, we demonstrate that the sophisticated hand-designed modules in existing works are not necessary to excel at the task of surface normal estimation.
Generalized Deepfakes Detection with Reconstructed-Blended Images and Multi-scale Feature Reconstruction Network
Dec 13, 2023
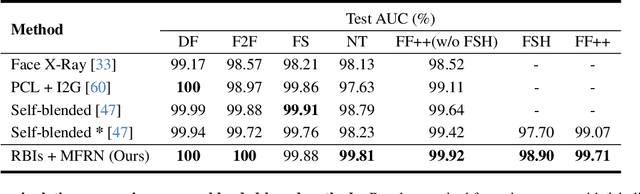
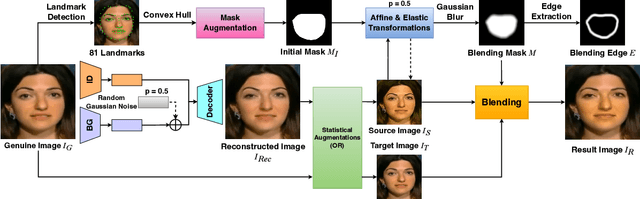
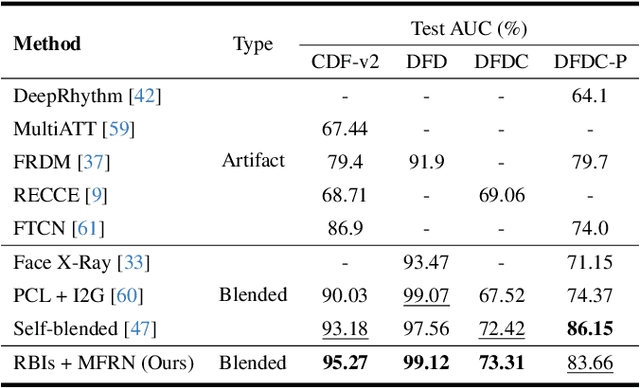
The growing diversity of digital face manipulation techniques has led to an urgent need for a universal and robust detection technology to mitigate the risks posed by malicious forgeries. We present a blended-based detection approach that has robust applicability to unseen datasets. It combines a method for generating synthetic training samples, i.e., reconstructed blended images, that incorporate potential deepfake generator artifacts and a detection model, a multi-scale feature reconstruction network, for capturing the generic boundary artifacts and noise distribution anomalies brought about by digital face manipulations. Experiments demonstrated that this approach results in better performance in both cross-manipulation detection and cross-dataset detection on unseen data.
Efficient Key-Based Adversarial Defense for ImageNet by Using Pre-trained Model
Nov 28, 2023



In this paper, we propose key-based defense model proliferation by leveraging pre-trained models and utilizing recent efficient fine-tuning techniques on ImageNet-1k classification. First, we stress that deploying key-based models on edge devices is feasible with the latest model deployment advancements, such as Apple CoreML, although the mainstream enterprise edge artificial intelligence (Edge AI) has been focused on the Cloud. Then, we point out that the previous key-based defense on on-device image classification is impractical for two reasons: (1) training many classifiers from scratch is not feasible, and (2) key-based defenses still need to be thoroughly tested on large datasets like ImageNet. To this end, we propose to leverage pre-trained models and utilize efficient fine-tuning techniques to proliferate key-based models even on limited computing resources. Experiments were carried out on the ImageNet-1k dataset using adaptive and non-adaptive attacks. The results show that our proposed fine-tuned key-based models achieve a superior classification accuracy (more than 10% increase) compared to the previous key-based models on classifying clean and adversarial examples.
A Novel Statistical Measure for Out-of-Distribution Detection in Data Quality Assurance
Oct 12, 2023Data outside the problem domain poses significant threats to the security of AI-based intelligent systems. Aiming to investigate the data domain and out-of-distribution (OOD) data in AI quality management (AIQM) study, this paper proposes to use deep learning techniques for feature representation and develop a novel statistical measure for OOD detection. First, to extract low-dimensional representative features distinguishing normal and OOD data, the proposed research combines the deep auto-encoder (AE) architecture and neuron activation status for feature engineering. Then, using local conditional probability (LCP) in data reconstruction, a novel and superior statistical measure is developed to calculate the score of OOD detection. Experiments and evaluations are conducted on image benchmark datasets and an industrial dataset. Through comparative analysis with other common statistical measures in OOD detection, the proposed research is validated as feasible and effective in OOD and AIQM studies.
How Close are Other Computer Vision Tasks to Deepfake Detection?
Oct 02, 2023In this paper, we challenge the conventional belief that supervised ImageNet-trained models have strong generalizability and are suitable for use as feature extractors in deepfake detection. We present a new measurement, "model separability," for visually and quantitatively assessing a model's raw capacity to separate data in an unsupervised manner. We also present a systematic benchmark for determining the correlation between deepfake detection and other computer vision tasks using pre-trained models. Our analysis shows that pre-trained face recognition models are more closely related to deepfake detection than other models. Additionally, models trained using self-supervised methods are more effective in separation than those trained using supervised methods. After fine-tuning all models on a small deepfake dataset, we found that self-supervised models deliver the best results, but there is a risk of overfitting. Our results provide valuable insights that should help researchers and practitioners develop more effective deepfake detection models.
Defending Against Physical Adversarial Patch Attacks on Infrared Human Detection
Sep 27, 2023



Infrared detection is an emerging technique for safety-critical tasks owing to its remarkable anti-interference capability. However, recent studies have revealed that it is vulnerable to physically-realizable adversarial patches, posing risks in its real-world applications. To address this problem, we are the first to investigate defense strategies against adversarial patch attacks on infrared detection, especially human detection. We have devised a straightforward defense strategy, patch-based occlusion-aware detection (POD), which efficiently augments training samples with random patches and subsequently detects them. POD not only robustly detects people but also identifies adversarial patch locations. Surprisingly, while being extremely computationally efficient, POD easily generalizes to state-of-the-art adversarial patch attacks that are unseen during training. Furthermore, POD improves detection precision even in a clean (i.e., no-patch) situation due to the data augmentation effect. Evaluation demonstrated that POD is robust to adversarial patches of various shapes and sizes. The effectiveness of our baseline approach is shown to be a viable defense mechanism for real-world infrared human detection systems, paving the way for exploring future research directions.