 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability Analysis of ChatGPT-based Sentiment Analysis in AI Quality Assurance
Jan 15, 2024



In the era of large AI models, the complex architecture and vast parameters present substantial challenges for effective AI quality management (AIQM), e.g. large language model (LLM). This paper focuses on investigating the quality assurance of a specific LLM-based AI product--a ChatGPT-based sentiment analysis system. The study delves into stability issues related to both the operation and robustness of the expansive AI model on which ChatGPT is based. Experimental analysis is conducted using benchmark datasets for sentiment analysis. The results reveal that the constructed ChatGPT-based sentiment analysis system exhibits uncertainty, which is attributed to various operational factors. It demonstrated that the system also exhibits stability issues in handling conventional small text attacks involving robustness.
A Novel Statistical Measure for Out-of-Distribution Detection in Data Quality Assurance
Oct 12, 2023Data outside the problem domain poses significant threats to the security of AI-based intelligent systems. Aiming to investigate the data domain and out-of-distribution (OOD) data in AI quality management (AIQM) study, this paper proposes to use deep learning techniques for feature representation and develop a novel statistical measure for OOD detection. First, to extract low-dimensional representative features distinguishing normal and OOD data, the proposed research combines the deep auto-encoder (AE) architecture and neuron activation status for feature engineering. Then, using local conditional probability (LCP) in data reconstruction, a novel and superior statistical measure is developed to calculate the score of OOD detection. Experiments and evaluations are conducted on image benchmark datasets and an industrial dataset. Through comparative analysis with other common statistical measures in OOD detection, the proposed research is validated as feasible and effective in OOD and AIQM studies.
Corner case data description and detection
Jan 07, 2021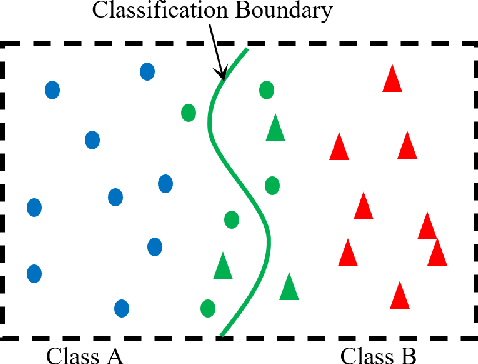
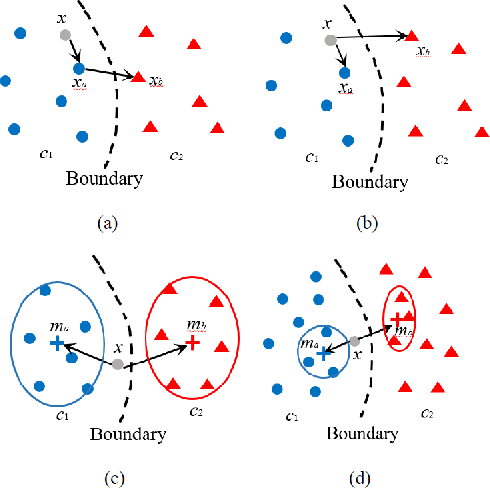
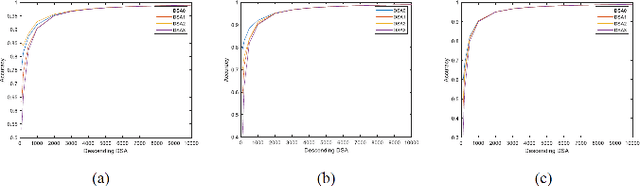

As the major factors affecting the safety of deep learning models, corner cases and related detection are crucial in AI quality assurance for constructing safety- and security-critical systems. The generic corner case researches involve two interesting topics. One is to enhance DL models robustness to corner case data via the adjustment on parameters/structure. The other is to generate new corner cases for model retraining and improvement. However, the complex architecture and the huge amount of parameters make the robust adjustment of DL models not easy, meanwhile it is not possible to generate all real-world corner cases for DL training. Therefore, this paper proposes to a simple and novel study aiming at corner case data detection via a specific metric. This metric is developed on surprise adequacy (SA) which has advantages on capture data behaviors. Furthermore, targeting at characteristics of corner case data, three modifications on distanced-based SA are developed for classification applications in this paper. Consequently, through the experiment analysis on MNIST data and industrial data, the feasibility and usefulness of the proposed method on corner case data detection are verified.