 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiteBench: A benchmark for Scientific Citation Text Generation
Dec 19, 2022



The publication rates are skyrocketing across many fields of science, and it is difficult to stay up to date with the latest research. This makes automatically summarizing the latest findings and helping scholars to synthesize related work in a given area an attractive research objective. In this paper we study the problem of citation text generation, where given a set of cited papers and citing context the model should generate a citation text. While citation text generation has been tackled in prior work, existing studies use different datasets and task definitions, which makes it hard to study citation text generation systematically. To address this, we propose CiteBench: a benchmark for citation text generation that unifies the previous datasets and enables standardized evaluation of citation text generation models across task settings and domains. Using the new benchmark, we investigate the performance of multiple strong baselines, test their transferability between the datasets, and deliver new insights into task definition and evaluation to guide the future research in citation text generation. We make CiteBench publicly available at https://github.com/UKPLab/citebench.
GDPR Compliant Collection of Therapist-Patient-Dialogues
Nov 22, 2022According to the Global Burden of Disease list provided by the World Health Organization (WHO), mental disorders are among the most debilitating disorders.To improve the diagnosis and the therapy effectiveness in recent years, researchers have tried to identify individual biomarkers. Gathering neurobiological data however, is costly and time-consuming. Another potential source of information, which is already part of the clinical routine, are therapist-patient dialogues. While there are some pioneering works investigating the role of language as predictors for various therapeutic parameters, for example patient-therapist alliance, there are no large-scale studies. A major obstacle to conduct these studies is the availability of sizeable datasets, which are needed to train machine learning models. While these conversations are part of the daily routine of clinicians, gathering them is usually hindered by various ethical (purpose of data usage), legal (data privacy) and technical (data formatting) limitations. Some of these limitations are particular to the domain of therapy dialogues, like the increased difficulty in anonymisation, or the transcription of the recordings. In this paper, we elaborate on the challenges we faced in starting our collection of therapist-patient dialogues in a psychiatry clinic under the General Data Privacy Regulation of the European Union with the goal to use the data for Natural Language Processing (NLP) research. We give an overview of each step in our procedure and point out the potential pitfalls to motivate further research in this field.
NLP meets psychotherapy: Using predicted client emotions and self-reported client emotions to measure emotional coherence
Nov 22, 2022
Emotions are experienced and expressed through various response systems. Coherence between emotional experience and emotional expression is considered important to clients' well being. To date, emotional coherence (EC) has been studied at a single time point using lab-based tasks with relatively small datasets. No study has examined EC between the subjective experience of emotions and emotion expression in therapy or whether this coherence is associated with clients' well being. Natural language Processing (NLP) approaches have been applied to identify emotions from psychotherapy dialogue, which can be implemented to study emotional processes on a larger scale. However, these methods have yet to be used to study coherence between emotional experience and emotional expression over the course of therapy and whether it relates to clients' well-being. This work presents an end-to-end approach where we use emotion predictions from our transformer based emotion recognition model to study emotional coherence and its diagnostic potential in psychotherapy research. We first employ our transformer based approach on a Hebrew psychotherapy dataset to automatically label clients' emotions at utterance level in psychotherapy dialogues. We subsequently investigate the emotional coherence between clients' self-reported emotional states and our model-based emotion predictions. We also examine the association between emotional coherence and clients' well being. Our findings indicate a significant correlation between clients' self-reported emotions and positive and negative emotions expressed verbally during psychotherapy sessions. Coherence in positive emotions was also highly correlated with clients well-being. These results illustrate how NLP can be applied to identify important emotional processes in psychotherapy to improve diagnosis and treatment for clients suffering from mental-health problems.
Semantic Similarity Models for Depression Severity Estimation
Nov 14, 2022Depressive disorders constitute a severe public health issue worldwide. However, public health systems have limited capacity for case detection and diagnosis. In this regard, the widespread use of social media has opened up a way to access public information on a large scale. Computational methods can serve as support tools for rapid screening by exploiting this user-generated social media content. This paper presents an efficient semantic pipeline to study depression severity in individuals based on their social media writings. We select test user sentences for producing semantic rankings over an index of representative training sentences corresponding to depressive symptoms and severity levels. Then, we use the sentences from those results as evidence for predicting users' symptom severity. For that, we explore different aggregation methods to answer one of four Beck Depression Inventory (BDI) options per symptom. We evaluate our methods on two Reddit-based benchmarks, achieving 30\% improvement over state of the art in terms of measuring depression severity.
NLPeer: A Unified Resource for the Computational Study of Peer Review
Nov 12, 2022Peer review is a core component of scholarly publishing, yet it is time-consuming, requires considerable expertise, and is prone to error. The applications of NLP for peer reviewing assistance aim to mitigate those issues, but the lack of clearly licensed datasets and multi-domain corpora prevent the systematic study of NLP for peer review. To remedy this, we introduce NLPeer -- the first ethically sourced multidomain corpus of more than 5k papers and 11k review reports from five different venues. In addition to the new datasets of paper drafts, camera-ready versions and peer reviews from the NLP community, we establish a unified data representation, and augment previous peer review datasets to include parsed, structured paper representations, rich metadata and versioning information. Our work paves the path towards systematic, multi-faceted, evidence-based study of peer review in NLP and beyond. We make NLPeer publicly available.
An Inclusive Notion of Text
Nov 10, 2022Natural language processing researchers develop models of grammar, meaning and human communication based on written text. Due to task and data differences, what is considered text can vary substantially across studies. A conceptual framework for systematically capturing these differences is lacking. We argue that clarity on the notion of text is crucial for reproducible and generalizable NLP. Towards that goal, we propose common terminology to discuss the production and transformation of textual data, and introduce a two-tier taxonomy of linguistic and non-linguistic elements that are available in textual sources and can be used in NLP modeling. We apply this taxonomy to survey existing work that extends the notion of text beyond the conservative language-centered view. We outline key desiderata and challenges of the emerging inclusive approach to text in NLP, and suggest systematic community-level reporting as a crucial next step to consolidate the discussion.
Contextual information integration for stance detection via cross-attention
Nov 03, 2022Stance detection deals with the identification of an author's stance towards a target and is applied on various text domains like social media and news. In many cases, inferring the stance is challenging due to insufficient access to contextual information. Complementary context can be found in knowledge bases but integrating the context into pretrained language models is non-trivial due to their graph structure. In contrast, we explore an approach to integrate contextual information as text which aligns better with transformer architectures. Specifically, we train a model consisting of dual encoders which exchange information via cross-attention. This architecture allows for integrating contextual information from heterogeneous sources. We evaluate context extracted from structured knowledge sources and from prompting large language models. Our approach is able to outperform competitive baselines (1.9pp on average) on a large and diverse stance detection benchmark, both (1) in-domain, i.e. for seen targets, and (2) out-of-domain, i.e. for targets unseen during training. Our analysis shows that it is able to regularize for spurious label correlations with target-specific cue words.
Effective Cross-Task Transfer Learning for Explainable Natural Language Inference with T5
Oct 31, 2022We compare sequential fine-tuning with a model for multi-task learning in the context where we are interested in boosting performance on two tasks, one of which depends on the other. We test these models on the FigLang2022 shared task which requires participants to predict language inference labels on figurative language along with corresponding textual explanations of the inference predictions. Our results show that while sequential multi-task learning can be tuned to be good at the first of two target tasks, it performs less well on the second and additionally struggles with overfitting. Our findings show that simple sequential fine-tuning of text-to-text models is an extraordinarily powerful method for cross-task knowledge transfer while simultaneously predicting multiple interdependent targets. So much so, that our best model achieved the (tied) highest score on the task.
Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation
Oct 25, 2022



Misinformation emerges in times of uncertainty when credible information is limited. This is challenging for NLP-based fact-checking as it relies on counter-evidence, which may not yet be available. Despite increasing interest in automatic fact-checking, it is still unclear if automated approaches can realistically refute harmful real-world misinformation. Here, we contrast and compare NLP fact-checking with how professional fact-checkers combat misinformation in the absence of counter-evidence. In our analysis, we show that, by design, existing NLP task definitions for fact-checking cannot refute misinformation as professional fact-checkers do for the majority of claims. We then define two requirements that the evidence in datasets must fulfill for realistic fact-checking: It must be (1) sufficient to refute the claim and (2) not leaked from existing fact-checking articles. We survey existing fact-checking datasets and find that all of them fail to satisfy both criteria. Finally, we perform experiments to demonstrate that models trained on a large-scale fact-checking dataset rely on leaked evidence, which makes them unsuitable in real-world scenarios. Taken together, we show that current NLP fact-checking cannot realistically combat real-world misinformation because it depends on unrealistic assumptions about counter-evidence in the data.
Incorporating Relevance Feedback for Information-Seeking Retrieval using Few-Shot Document Re-Ranking
Oct 19, 2022
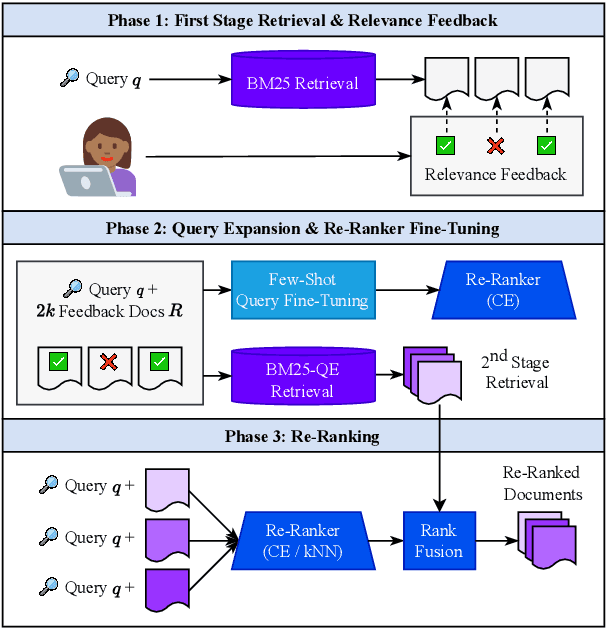
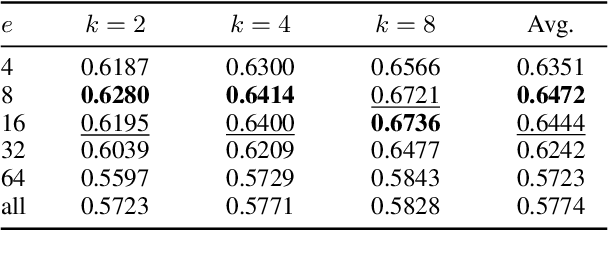
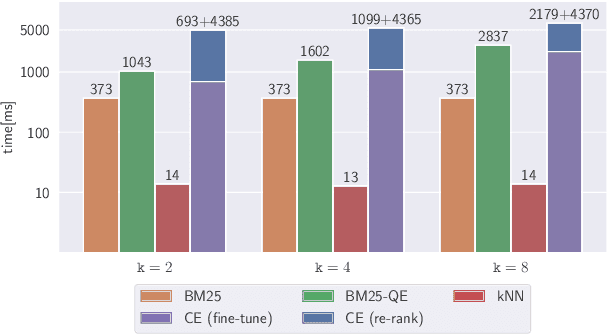
Pairing a lexical retriever with a neural re-ranking model has set state-of-the-art performance on large-scale information retrieval datasets. This pipeline covers scenarios like question answering or navigational queries, however, for information-seeking scenarios, users often provide information on whether a document is relevant to their query in form of clicks or explicit feedback. Therefore, in this work, we explore how relevance feedback can be directly integrated into neural re-ranking models by adopting few-shot and parameter-efficient learning techniques. Specifically, we introduce a kNN approach that re-ranks documents based on their similarity with the query and the documents the user considers relevant. Further, we explore Cross-Encoder models that we pre-train using meta-learning and subsequently fine-tune for each query, training only on the feedback documents. To evaluate our different integration strategies, we transform four existing information retrieval datasets into the relevance feedback scenario. Extensive experiments demonstrate that integrating relevance feedback directly in neural re-ranking models improves their performance, and fusing lexical ranking with our best performing neural re-ranker outperforms all other methods by 5.2 nDCG@20.