 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Persona-Consistent Dialogue Responses Using Deep Reinforcement Learning
Paper and Code

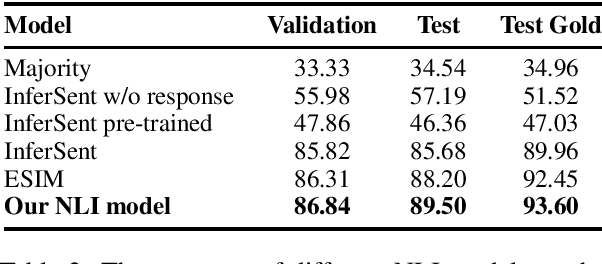

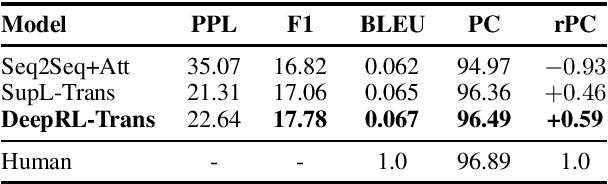
Recent transformer-based open-domain dialogue agents are trained by reference responses in a fully supervised scenario. Such agents often display inconsistent personalities as training data potentially contain contradictory responses to identical input utterances and no persona-relevant criteria are used in their training losses. We propose a novel approach to train transformer-based dialogue agents using actor-critic reinforcement learning. We define a new reward function to assess generated responses in terms of persona consistency, topic consistency, and fluency. Our reference-agnostic reward relies only on a dialogue history and a persona defined by a list of facts. Automatic and human evaluations on the PERSONACHAT dataset show that our proposed approach increases the rate of persona-consistent responses compared with its peers that are trained in a fully supervised scenario using reference responses.