 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does LLM Refinement Actually Improve? A Systematic Study on Document-Level Literary Translation
May 13, 2026Iterative self-refinement is a simple inference-time strategy for machine translation: an LLM revises its own translation over multiple inference-time passes. Yet document-scale refinement remains poorly understood: 1) which pipelines work best, 2) what quality dimensions improve, and 3) how refiners behave. In this paper, we present a systematic study of document-level literary translation, covering nine LLMs and seven language pairs. Across nine translation-refinement granularity combinations and five refinement strategies, we find a robust recipe: document-level MT followed by segment-level refinement yields strong and stable improvements. In contrast, document-level refinement often makes fewer edits and leads to smaller or less reliable gains. Beyond granularity, A simple general refinement prompt consistently outperforms error-specific prompting and evaluate-then-refine schemes. Our large-scale human evaluation shows that refinement gains come primarily from fluency, style, and terminology, with limited and less consistent improvements in adequacy. Experiments varying model strength reveal refinement projects outputs toward the refiner's distribution rather than performing targeted error repair. These findings clarify the mechanisms and limitations of current refinement approaches.
Metaphoric Paraphrase Generation
Feb 28, 2020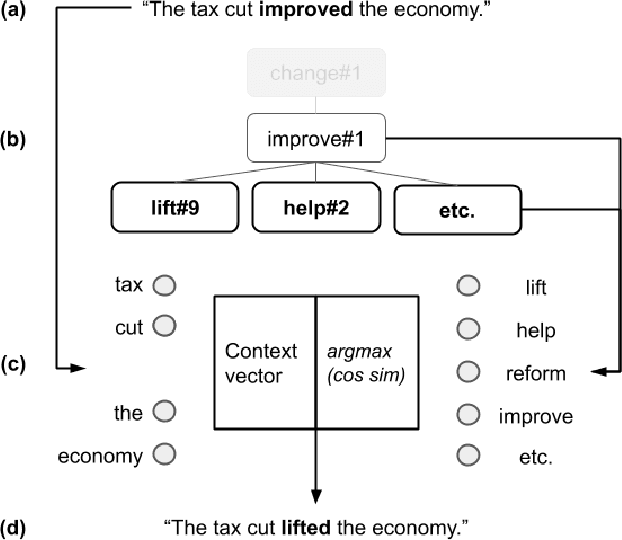
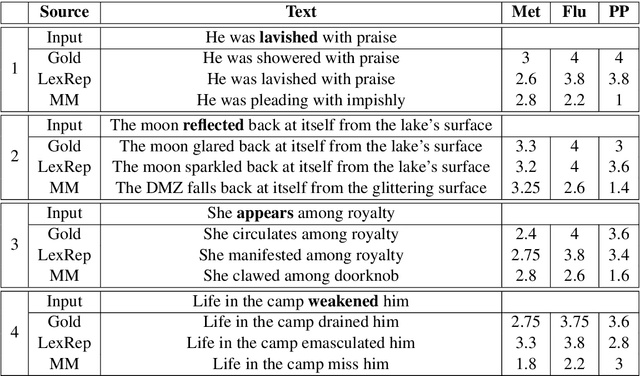
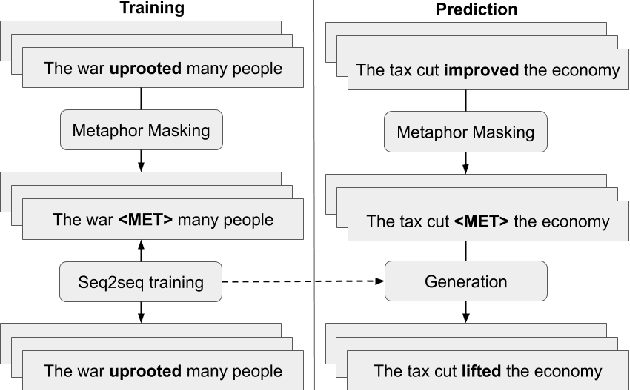
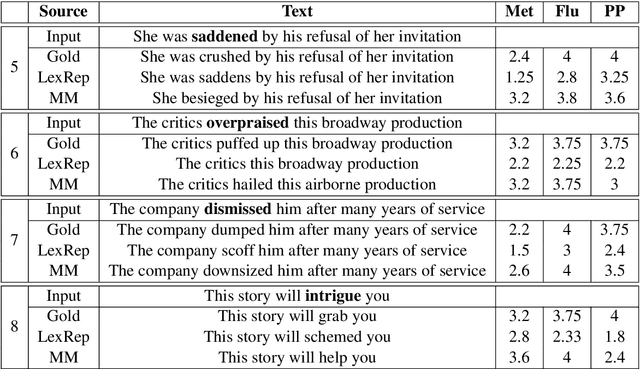
This work describes the task of metaphoric paraphrase generation, in which we are given a literal sentence and are charged with generating a metaphoric paraphrase. We propose two different models for this task: a lexical replacement baseline and a novel sequence to sequence model, 'metaphor masking', that generates free metaphoric paraphrases. We use crowdsourcing to evaluate our results, as well as developing an automatic metric for evaluating metaphoric paraphrases. We show that while the lexical replacement baseline is capable of producing accurate paraphrases, they often lack metaphoricity, while our metaphor masking model excels in generating metaphoric sentences while performing nearly as well with regard to fluency and paraphrase quality.
Generalisation and Sharing in Triplet Convnets for Sketch based Visual Search
Nov 16, 2016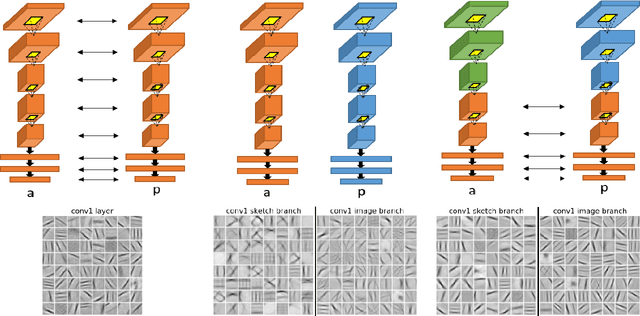

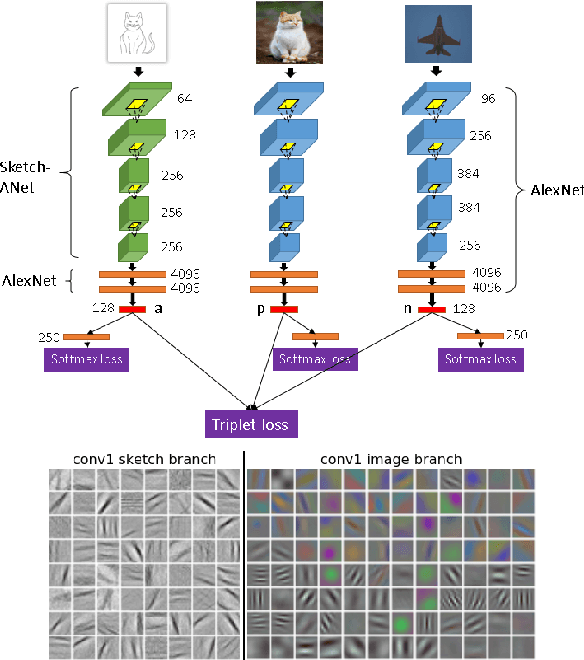
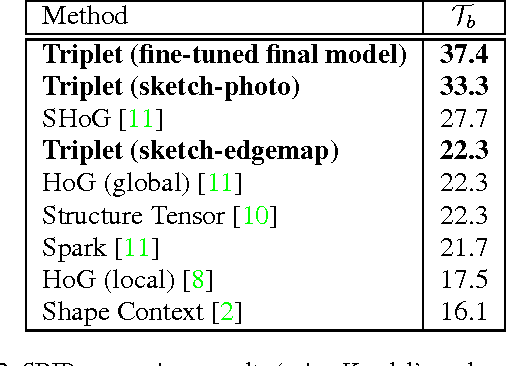
We propose and evaluate several triplet CNN architectures for measuring the similarity between sketches and photographs, within the context of the sketch based image retrieval (SBIR) task. In contrast to recent fine-grained SBIR work, we study the ability of our networks to generalise across diverse object categories from limited training data, and explore in detail strategies for weight sharing, pre-processing, data augmentation and dimensionality reduction. We exceed the performance of pre-existing techniques on both the Flickr15k category level SBIR benchmark by $18\%$, and the TU-Berlin SBIR benchmark by $\sim10 \mathcal{T}_b$, when trained on the 250 category TU-Berlin classification dataset augmented with 25k corresponding photographs harvested from the Internet.