 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021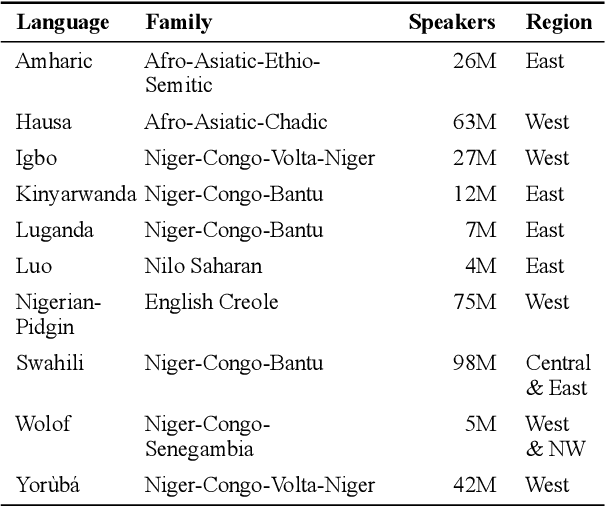

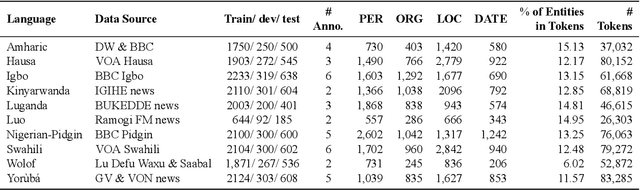
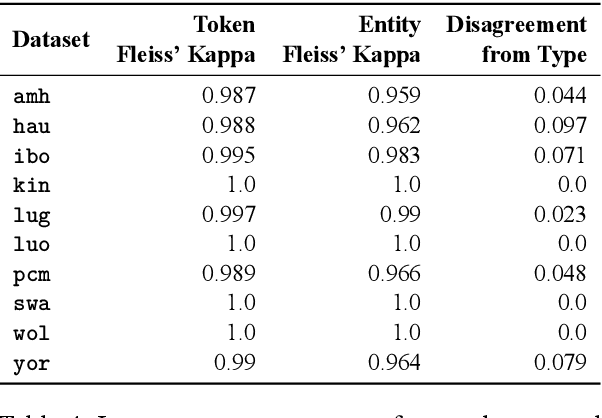
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020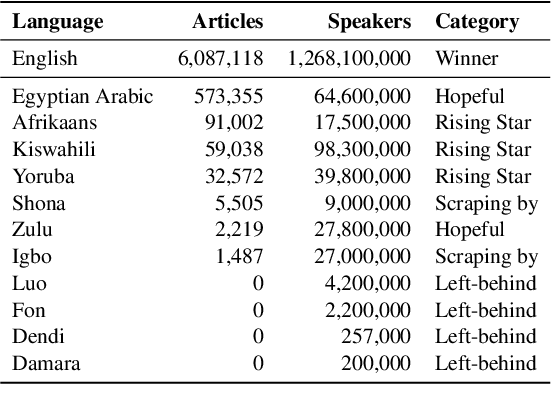
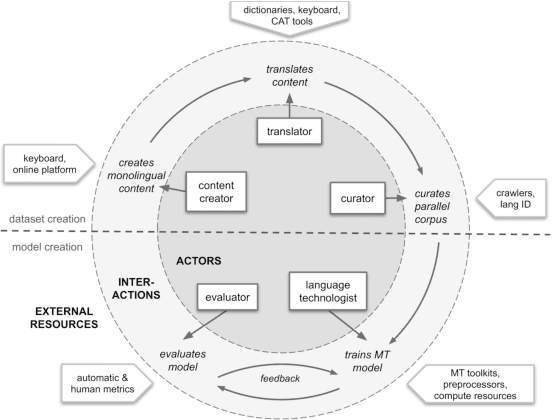
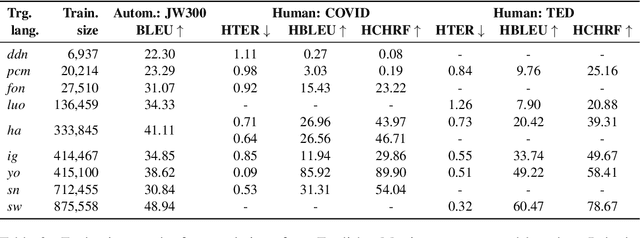
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
Towards Neural Machine Translation for Edoid Languages
Mar 24, 2020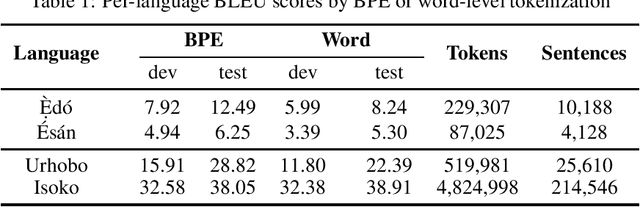
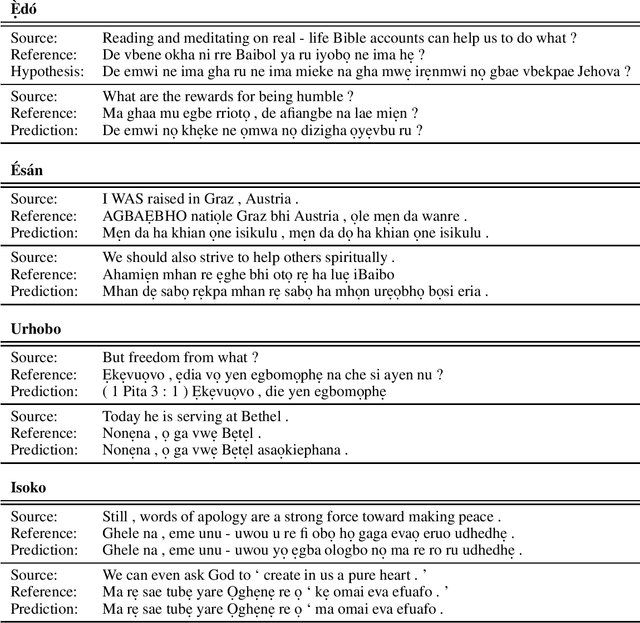
Many Nigerian languages have relinquished their previous prestige and purpose in modern society to English and Nigerian Pidgin. For the millions of L1 speakers of indigenous languages, there are inequalities that manifest themselves as unequal access to information, communications, health care, security as well as attenuated participation in political and civic life. To minimize exclusion and promote socio-linguistic and economic empowerment, this work explores the feasibility of Neural Machine Translation (NMT) for the Edoid language family of Southern Nigeria. Using the new JW300 public dataset, we trained and evaluated baseline translation models for four widely spoken languages in this group: \`Ed\'o, \'Es\'an, Urhobo and Isoko. Trained models, code and datasets have been open-sourced to advance future research efforts on Edoid language technology.
Improving Yorùbá Diacritic Restoration
Mar 23, 2020
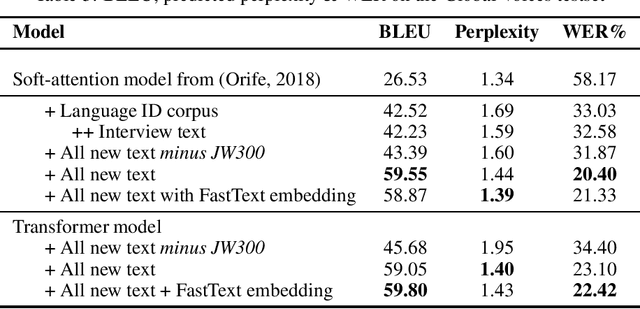
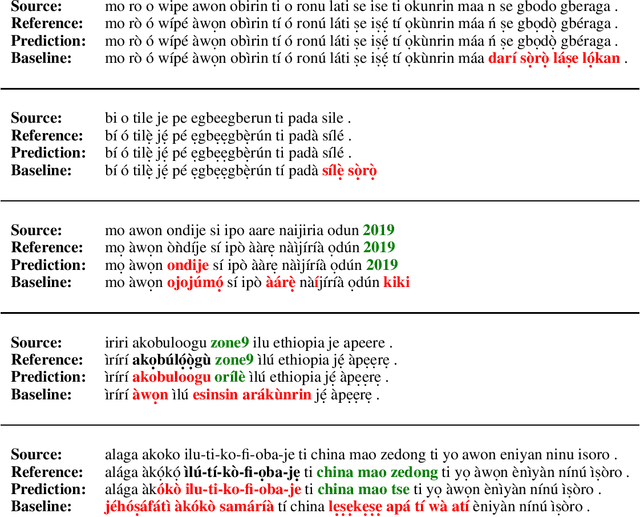
Yor\`ub\'a is a widely spoken West African language with a writing system rich in orthographic and tonal diacritics. They provide morphological information, are crucial for lexical disambiguation, pronunciation and are vital for any computational Speech or Natural Language Processing tasks. However diacritic marks are commonly excluded from electronic texts due to limited device and application support as well as general education on proper usage. We report on recent efforts at dataset cultivation. By aggregating and improving disparate texts from the web and various personal libraries, we were able to significantly grow our clean Yor\`ub\'a dataset from a majority Bibilical text corpora with three sources to millions of tokens from over a dozen sources. We evaluate updated diacritic restoration models on a new, general purpose, public-domain Yor\`ub\'a evaluation dataset of modern journalistic news text, selected to be multi-purpose and reflecting contemporary usage. All pre-trained models, datasets and source-code have been released as an open-source project to advance efforts on Yor\`ub\'a language technology.
Masakhane -- Machine Translation For Africa
Mar 13, 2020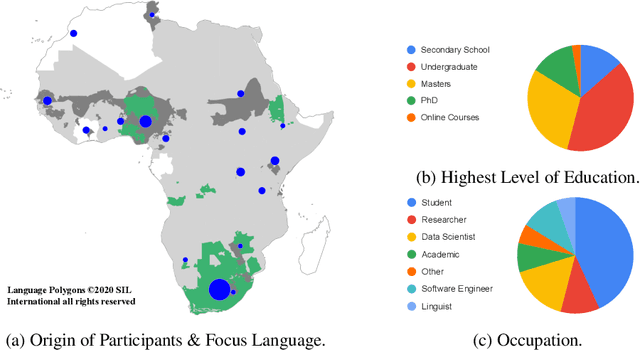
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
The Marchex 2018 English Conversational Telephone Speech Recognition System
Nov 05, 2018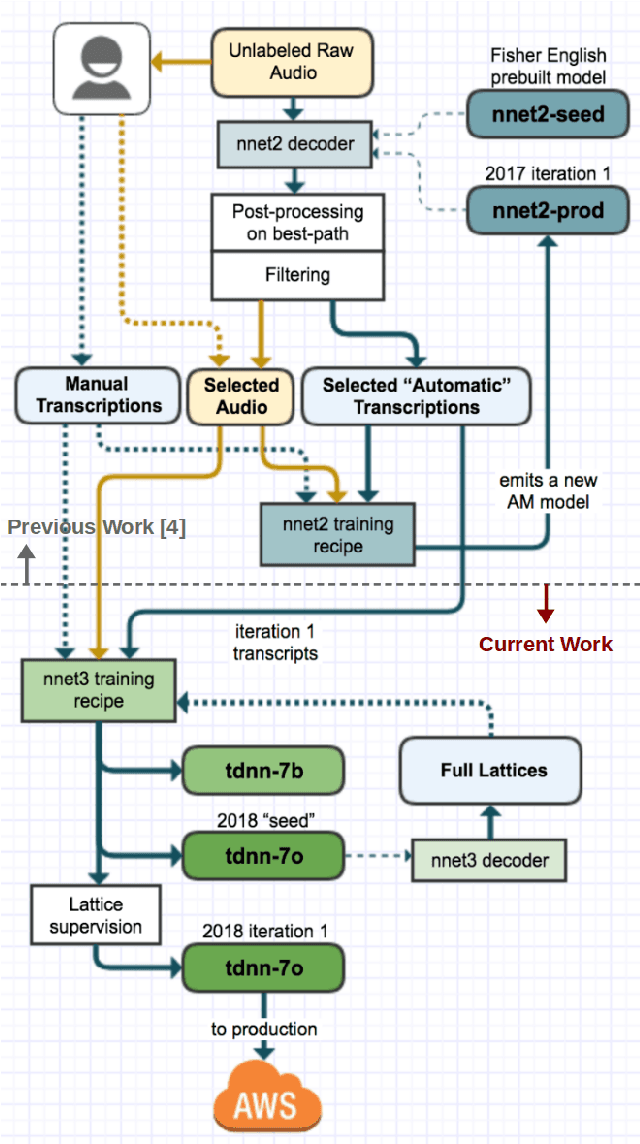
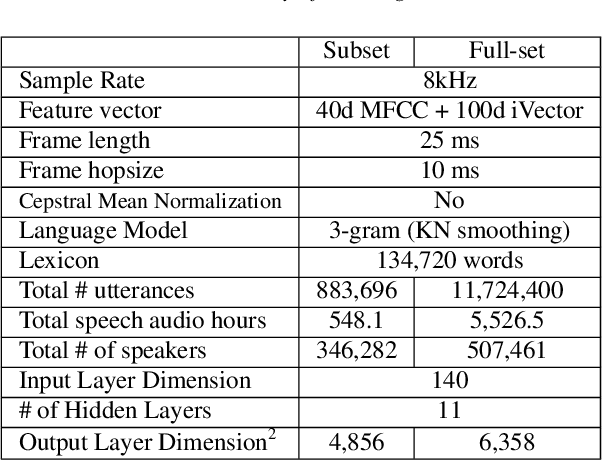
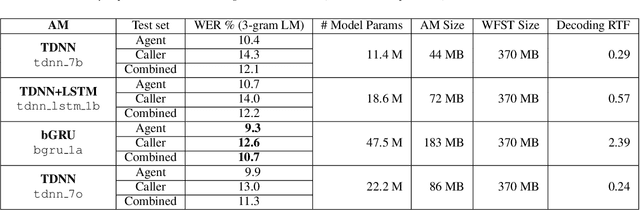

In this paper, we describe recent improvements to the production Marchex speech recognition system for our spontaneous customer-to-business telephone conversations. We outline our semi-supervised lattice-free maximum mutual information (LF-MMI) training process which can supervise over full lattices from unlabeled audio. We also elaborate on production-scale text selection techniques for constructing very large conversational language models (LMs). On Marchex English (ME), a modern evaluation set of conversational North American English, for acoustic modeling we report a 3.3% ({agent, caller}:{3.2%, 3.6%}) reduction in absolute word error rate (WER). For language modeling, we observe a separate {1.3%, 1.2%} point reduction on {agent, caller} utterances respectively over the performance of the 2017 production system.
Attentive Sequence-to-Sequence Learning for Diacritic Restoration of Yorùbá Language Text
Oct 30, 2018
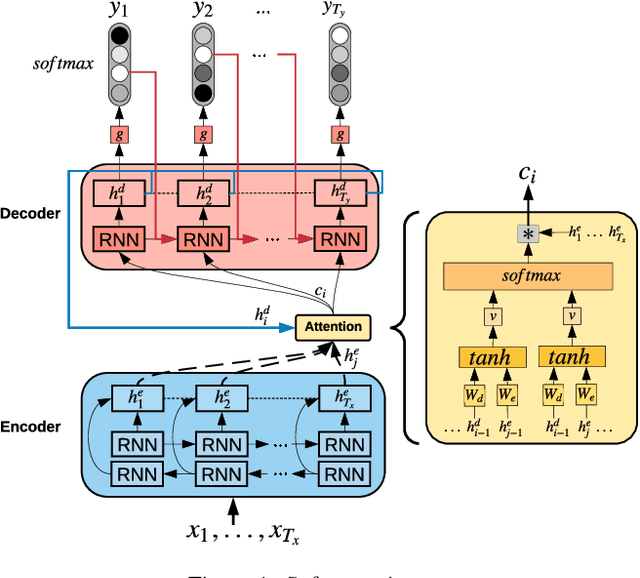

Yor\`ub\'a is a widely spoken West African language with a writing system rich in tonal and orthographic diacritics. With very few exceptions, diacritics are omitted from electronic texts, due to limited device and application support. Diacritics provide morphological information, are crucial for lexical disambiguation, pronunciation and are vital for any Yor\`ub\'a text-to-speech (TTS), automatic speech recognition (ASR) and natural language processing (NLP) tasks. Reframing Automatic Diacritic Restoration (ADR) as a machine translation task, we experiment with two different attentive Sequence-to-Sequence neural models to process undiacritized text. On our evaluation dataset, this approach produces diacritization error rates of less than 5%. We have released pre-trained models, datasets and source-code as an open-source project to advance efforts on Yor\`ub\'a language technology.
Semi-Supervised Model Training for Unbounded Conversational Speech Recognition
May 26, 2017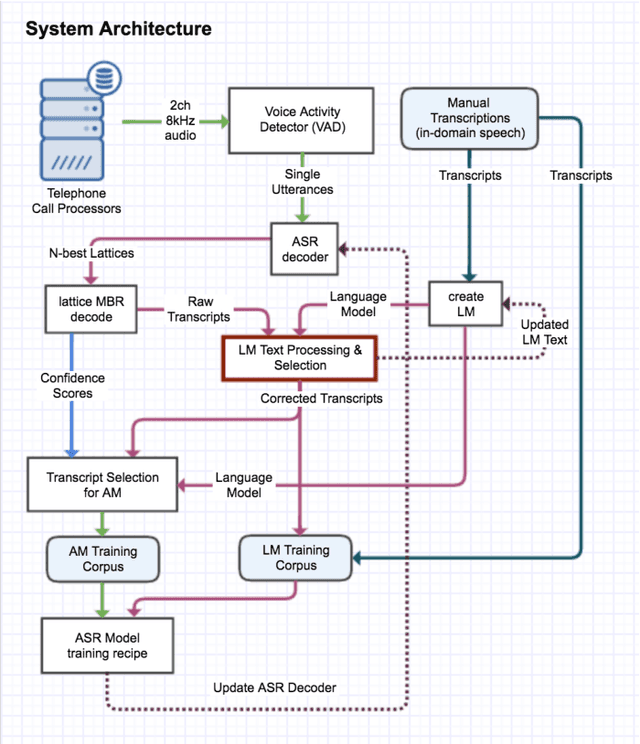
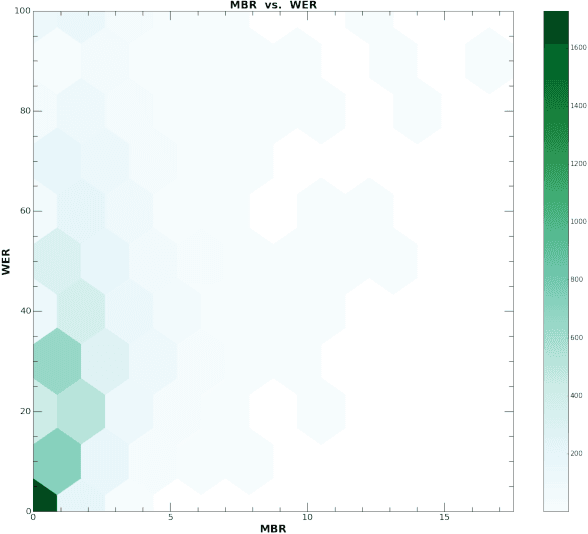
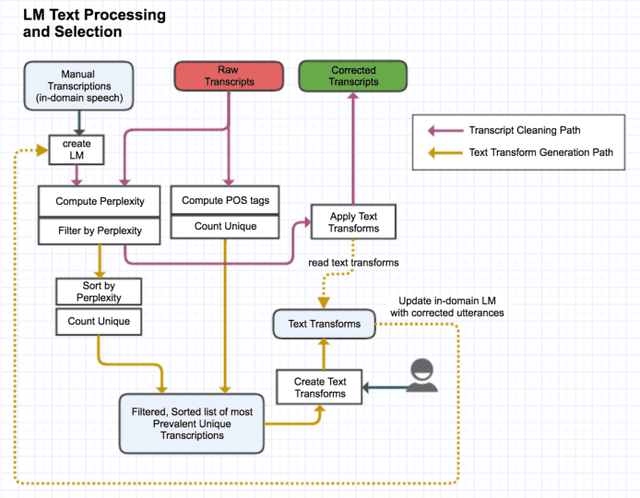
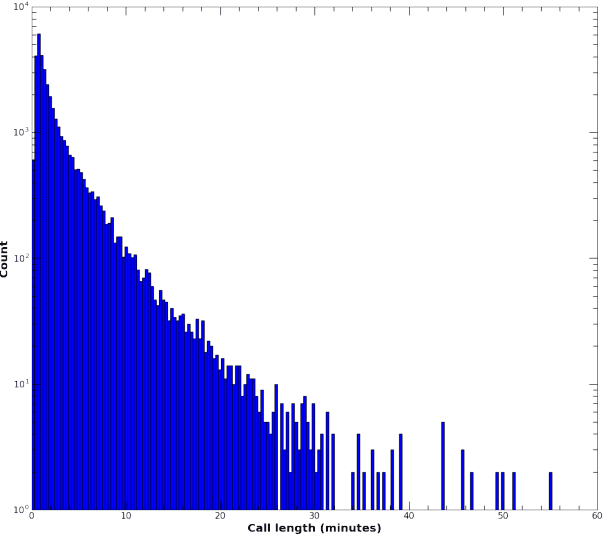
For conversational large-vocabulary continuous speech recognition (LVCSR) tasks, up to about two thousand hours of audio is commonly used to train state of the art models. Collection of labeled conversational audio however, is prohibitively expensive, laborious and error-prone. Furthermore, academic corpora like Fisher English (2004) or Switchboard (1992) are inadequate to train models with sufficient accuracy in the unbounded space of conversational speech. These corpora are also timeworn due to dated acoustic telephony features and the rapid advancement of colloquial vocabulary and idiomatic speech over the last decades. Utilizing the colossal scale of our unlabeled telephony dataset, we propose a technique to construct a modern, high quality conversational speech training corpus on the order of hundreds of millions of utterances (or tens of thousands of hours) for both acoustic and language model training. We describe the data collection, selection and training, evaluating the results of our updated speech recognition system on a test corpus of 7K manually transcribed utterances. We show relative word error rate (WER) reductions of {35%, 19%} on {agent, caller} utterances over our seed model and 5% absolute WER improvements over IBM Watson STT on this conversational speech task.