 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Marchex 2018 English Conversational Telephone Speech Recognition System
Nov 05, 2018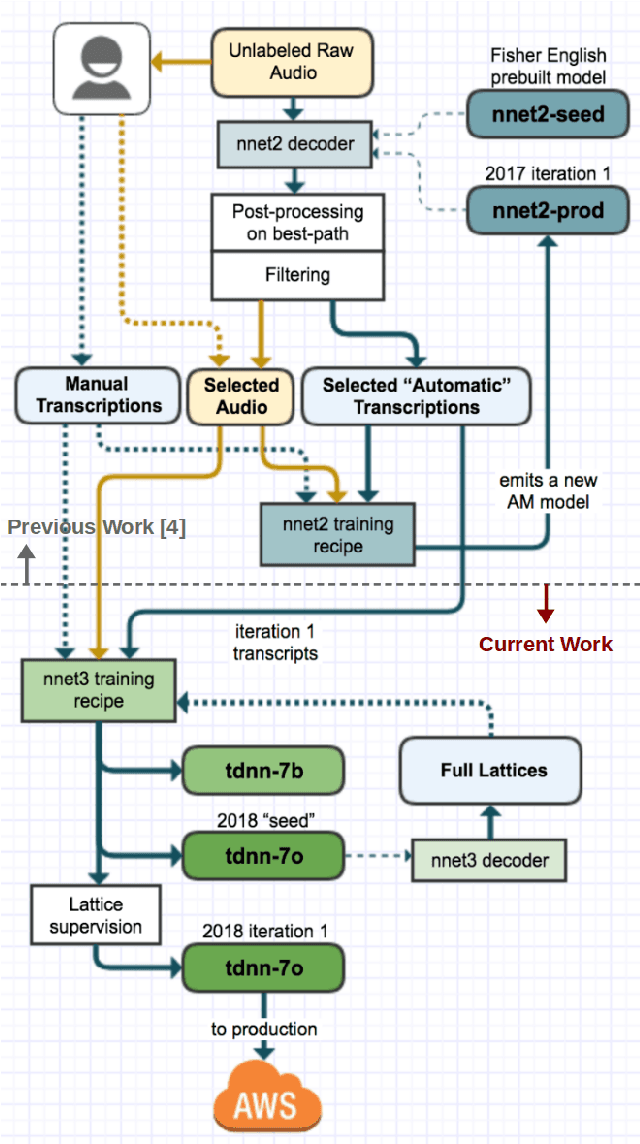
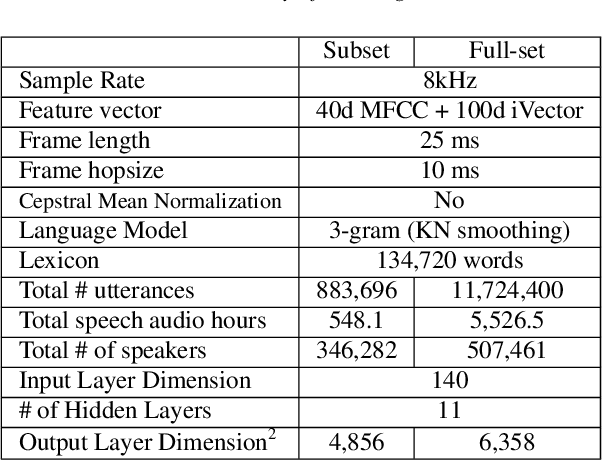
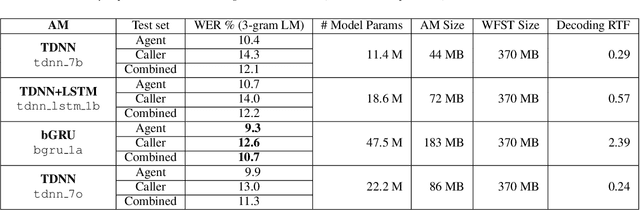

In this paper, we describe recent improvements to the production Marchex speech recognition system for our spontaneous customer-to-business telephone conversations. We outline our semi-supervised lattice-free maximum mutual information (LF-MMI) training process which can supervise over full lattices from unlabeled audio. We also elaborate on production-scale text selection techniques for constructing very large conversational language models (LMs). On Marchex English (ME), a modern evaluation set of conversational North American English, for acoustic modeling we report a 3.3% ({agent, caller}:{3.2%, 3.6%}) reduction in absolute word error rate (WER). For language modeling, we observe a separate {1.3%, 1.2%} point reduction on {agent, caller} utterances respectively over the performance of the 2017 production system.