 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving from 2D to 3D: volumetric medical image classification for rectal cancer staging
Sep 13, 2022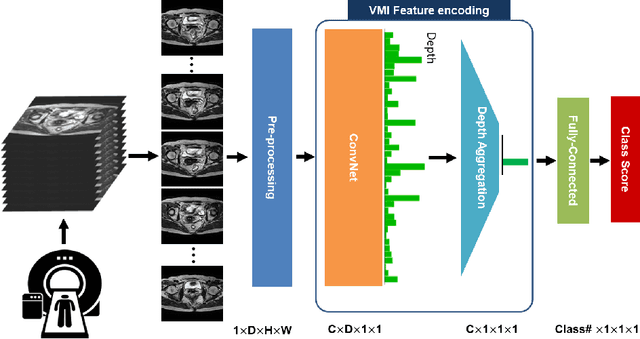
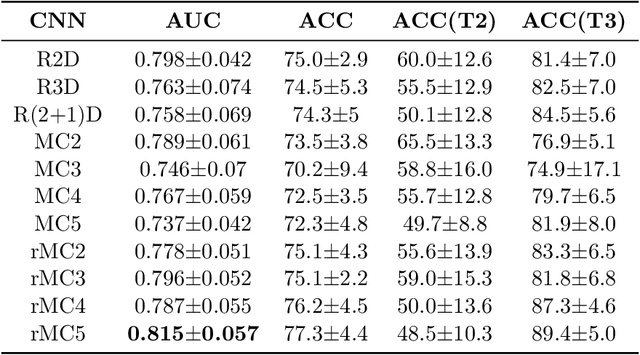
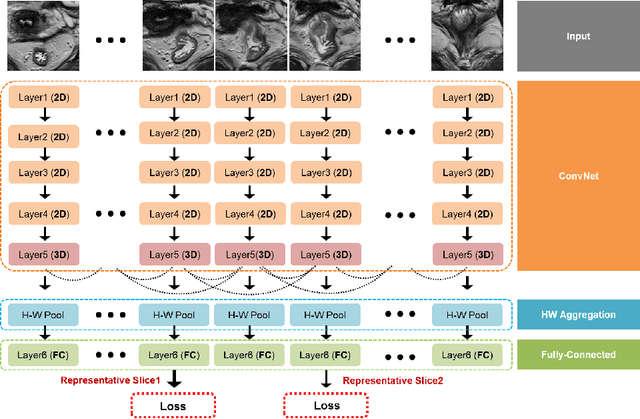

Volumetric images from Magnetic Resonance Imaging (MRI) provide invaluable information in preoperative staging of rectal cancer. Above all, accurate preoperative discrimination between T2 and T3 stages is arguably both the most challenging and clinically significant task for rectal cancer treatment, as chemo-radiotherapy is usually recommended to patients with T3 (or greater) stage cancer. In this study, we present a volumetric convolutional neural network to accurately discriminate T2 from T3 stage rectal cancer with rectal MR volumes. Specifically, we propose 1) a custom ResNet-based volume encoder that models the inter-slice relationship with late fusion (i.e., 3D convolution at the last layer), 2) a bilinear computation that aggregates the resulting features from the encoder to create a volume-wise feature, and 3) a joint minimization of triplet loss and focal loss. With MR volumes of pathologically confirmed T2/T3 rectal cancer, we perform extensive experiments to compare various designs within the framework of residual learning. As a result, our network achieves an AUC of 0.831, which is higher than the reported accuracy of the professional radiologist groups. We believe this method can be extended to other volume analysis tasks
MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation
Apr 27, 2022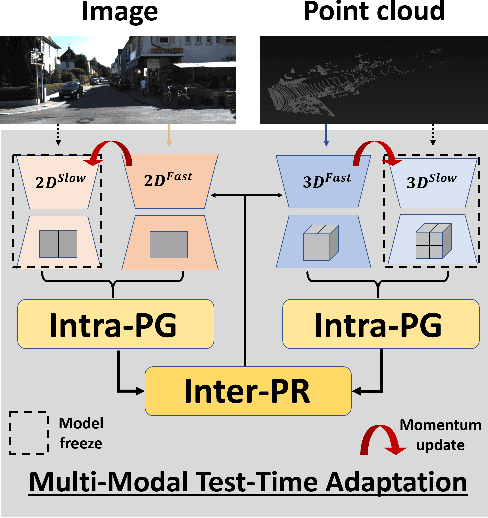
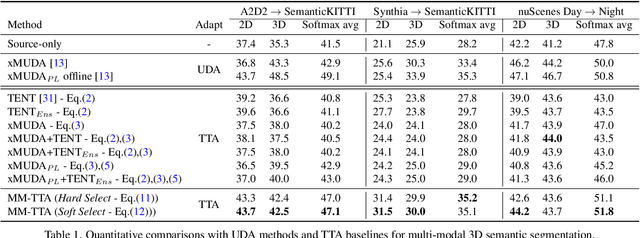
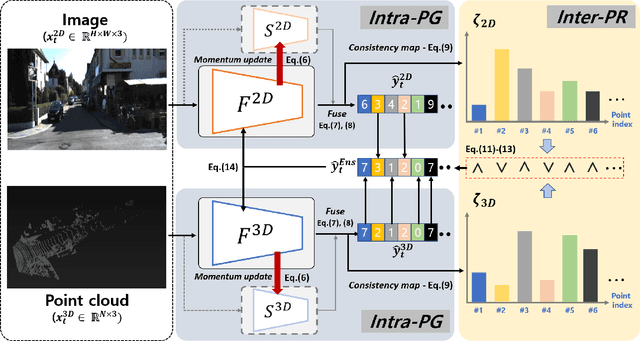
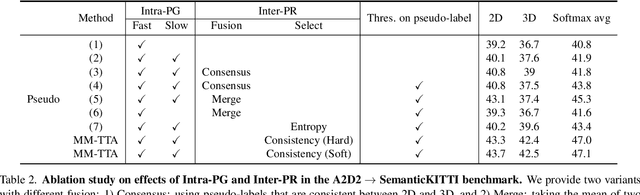
Test-time adaptation approaches have recently emerged as a practical solution for handling domain shift without access to the source domain data. In this paper, we propose and explore a new multi-modal extension of test-time adaptation for 3D semantic segmentation. We find that directly applying existing methods usually results in performance instability at test time because multi-modal input is not considered jointly. To design a framework that can take full advantage of multi-modality, where each modality provides regularized self-supervisory signals to other modalities, we propose two complementary modules within and across the modalities. First, Intra-modal Pseudolabel Generation (Intra-PG) is introduced to obtain reliable pseudo labels within each modality by aggregating information from two models that are both pre-trained on source data but updated with target data at different paces. Second, Inter-modal Pseudo-label Refinement (Inter-PR) adaptively selects more reliable pseudo labels from different modalities based on a proposed consistency scheme. Experiments demonstrate that our regularized pseudo labels produce stable self-learning signals in numerous multi-modal test-time adaptation scenarios for 3D semantic segmentation. Visit our project website at https://www.nec-labs.com/~mas/MM-TTA.
UDA-COPE: Unsupervised Domain Adaptation for Category-level Object Pose Estimation
Nov 24, 2021
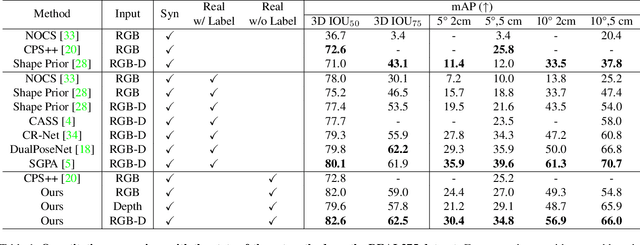
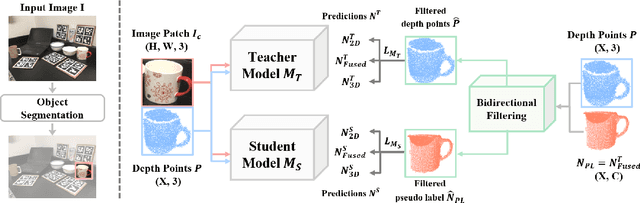

Learning to estimate object pose often requires ground-truth (GT) labels, such as CAD model and absolute-scale object pose, which is expensive and laborious to obtain in the real world. To tackle this problem, we propose an unsupervised domain adaptation (UDA) for category-level object pose estimation, called \textbf{UDA-COPE}. Inspired by the recent multi-modal UDA techniques, the proposed method exploits a teacher-student self-supervised learning scheme to train a pose estimation network without using target domain labels. We also introduce a bidirectional filtering method between predicted normalized object coordinate space (NOCS) map and observed point cloud, to not only make our teacher network more robust to the target domain but also to provide more reliable pseudo labels for the student network training. Extensive experimental results demonstrate the effectiveness of our proposed method both quantitatively and qualitatively. Notably, without leveraging target-domain GT labels, our proposed method achieves comparable or sometimes superior performance to existing methods that depend on the GT labels.
Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021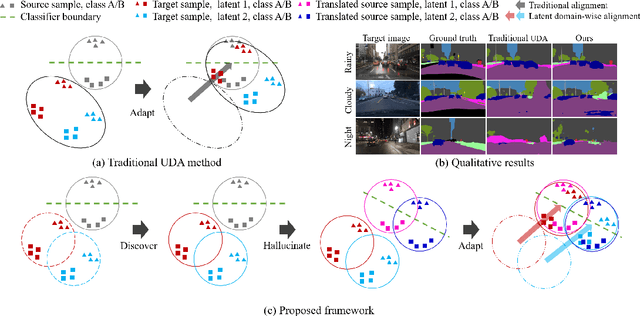
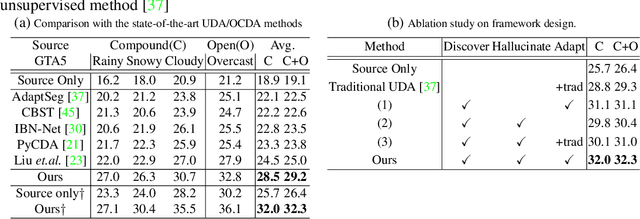
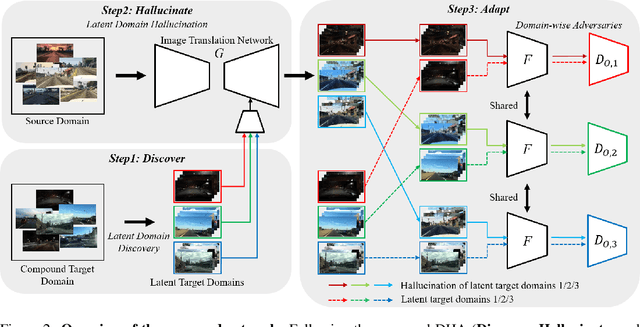
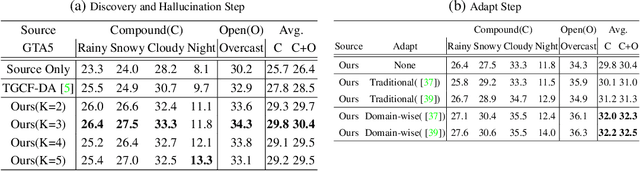
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
LabOR: Labeling Only if Required for Domain Adaptive Semantic Segmentation
Aug 12, 2021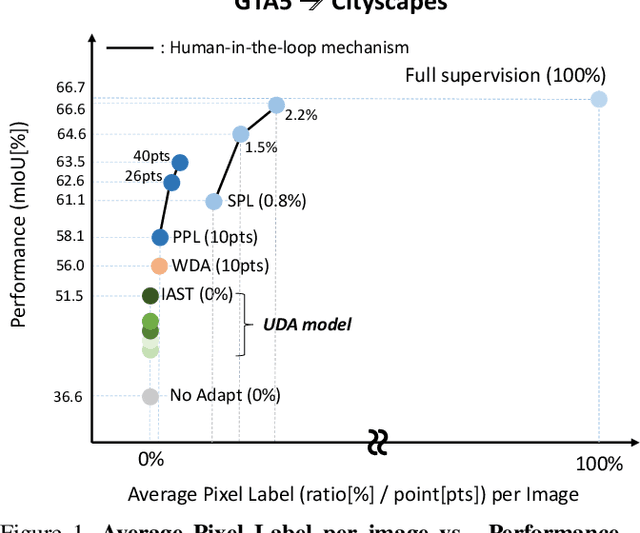
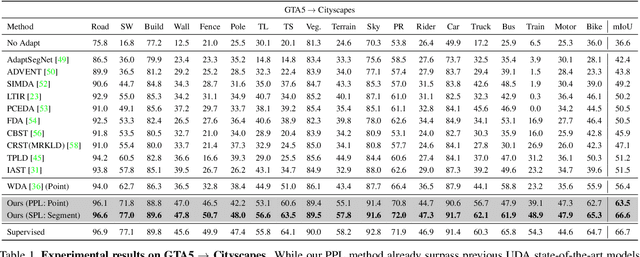
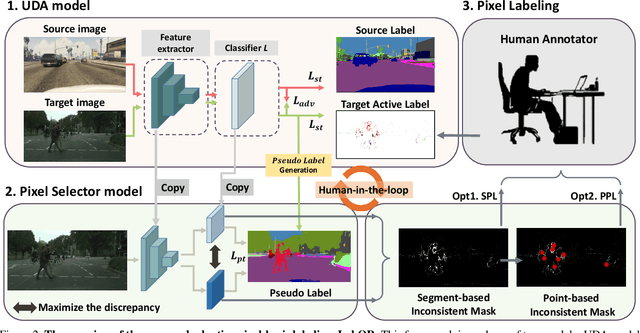
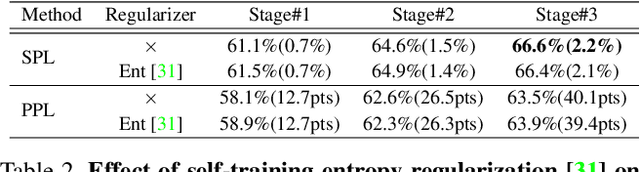
Unsupervised Domain Adaptation (UDA) for semantic segmentation has been actively studied to mitigate the domain gap between label-rich source data and unlabeled target data. Despite these efforts, UDA still has a long way to go to reach the fully supervised performance. To this end, we propose a Labeling Only if Required strategy, LabOR, where we introduce a human-in-the-loop approach to adaptively give scarce labels to points that a UDA model is uncertain about. In order to find the uncertain points, we generate an inconsistency mask using the proposed adaptive pixel selector and we label these segment-based regions to achieve near supervised performance with only a small fraction (about 2.2%) ground truth points, which we call "Segment based Pixel-Labeling (SPL)". To further reduce the efforts of the human annotator, we also propose "Point-based Pixel-Labeling (PPL)", which finds the most representative points for labeling within the generated inconsistency mask. This reduces efforts from 2.2% segment label to 40 points label while minimizing performance degradation. Through extensive experimentation, we show the advantages of this new framework for domain adaptive semantic segmentation while minimizing human labor costs.
Unsupervised Domain Adaptation for Video Semantic Segmentation
Jul 23, 2021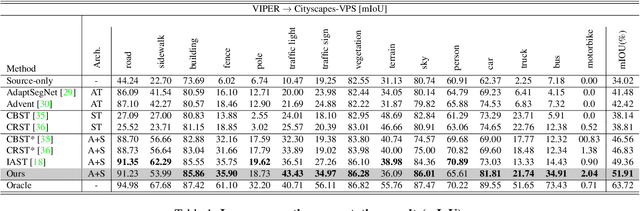
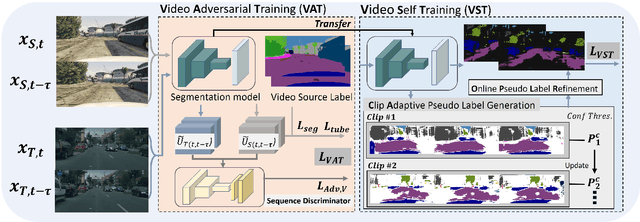
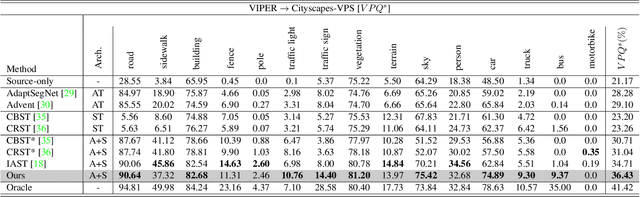
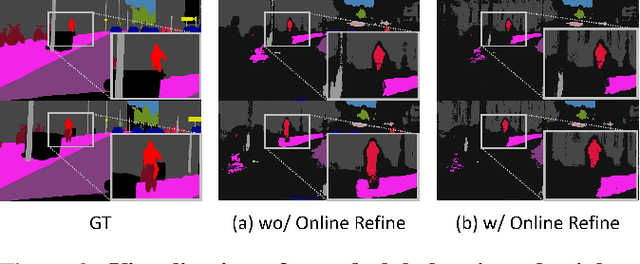
Unsupervised Domain Adaptation for semantic segmentation has gained immense popularity since it can transfer knowledge from simulation to real (Sim2Real) by largely cutting out the laborious per pixel labeling efforts at real. In this work, we present a new video extension of this task, namely Unsupervised Domain Adaptation for Video Semantic Segmentation. As it became easy to obtain large-scale video labels through simulation, we believe attempting to maximize Sim2Real knowledge transferability is one of the promising directions for resolving the fundamental data-hungry issue in the video. To tackle this new problem, we present a novel two-phase adaptation scheme. In the first step, we exhaustively distill source domain knowledge using supervised loss functions. Simultaneously, video adversarial training (VAT) is employed to align the features from source to target utilizing video context. In the second step, we apply video self-training (VST), focusing only on the target data. To construct robust pseudo labels, we exploit the temporal information in the video, which has been rarely explored in the previous image-based self-training approaches. We set strong baseline scores on 'VIPER to CityscapeVPS' adaptation scenario. We show that our proposals significantly outperform previous image-based UDA methods both on image-level (mIoU) and video-level (VPQ) evaluation metrics.
Two-phase Pseudo Label Densification for Self-training based Domain Adaptation
Dec 09, 2020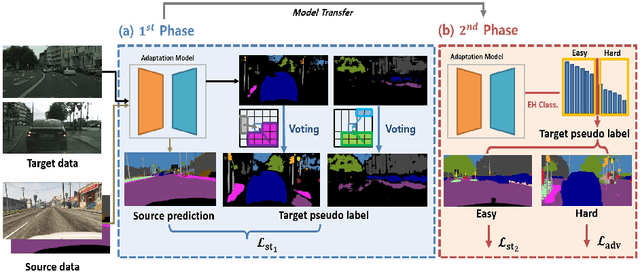
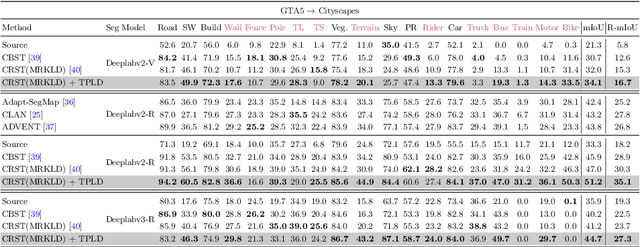
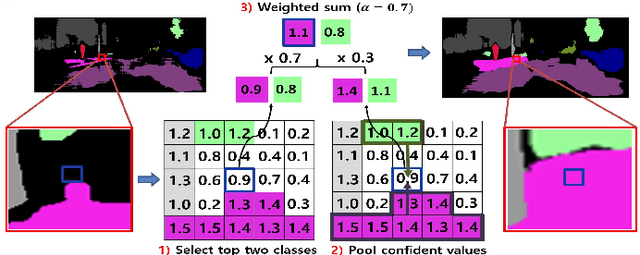
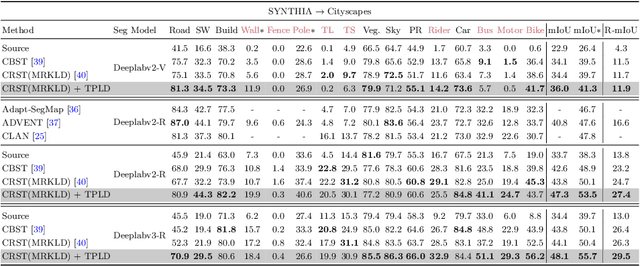
Recently, deep self-training approaches emerged as a powerful solution to the unsupervised domain adaptation. The self-training scheme involves iterative processing of target data; it generates target pseudo labels and retrains the network. However, since only the confident predictions are taken as pseudo labels, existing self-training approaches inevitably produce sparse pseudo labels in practice. We see this is critical because the resulting insufficient training-signals lead to a suboptimal, error-prone model. In order to tackle this problem, we propose a novel Two-phase Pseudo Label Densification framework, referred to as TPLD. In the first phase, we use sliding window voting to propagate the confident predictions, utilizing intrinsic spatial-correlations in the images. In the second phase, we perform a confidence-based easy-hard classification. For the easy samples, we now employ their full pseudo labels. For the hard ones, we instead adopt adversarial learning to enforce hard-to-easy feature alignment. To ease the training process and avoid noisy predictions, we introduce the bootstrapping mechanism to the original self-training loss. We show the proposed TPLD can be easily integrated into existing self-training based approaches and improves the performance significantly. Combined with the recently proposed CRST self-training framework, we achieve new state-of-the-art results on two standard UDA benchmarks.
Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision
Apr 20, 2020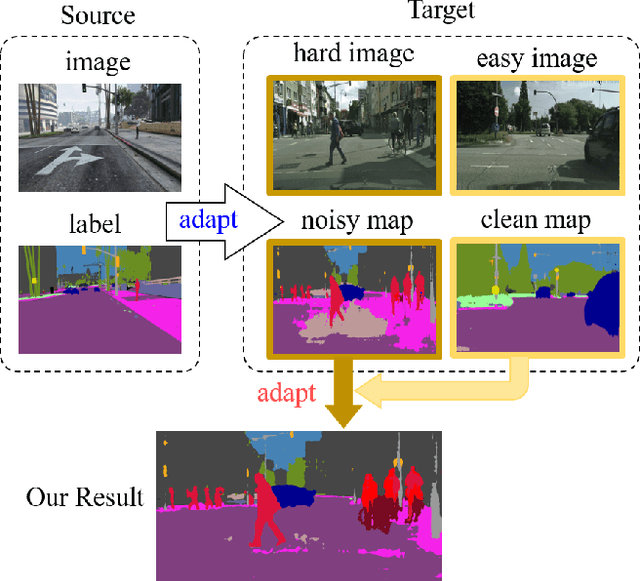
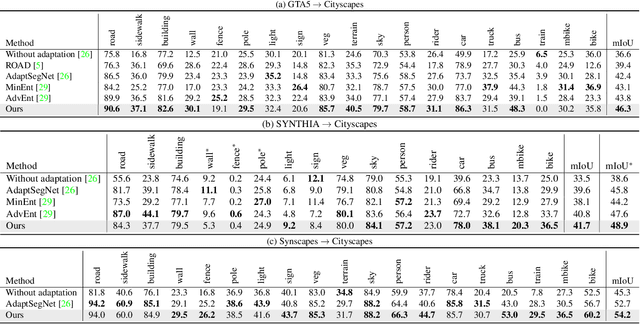
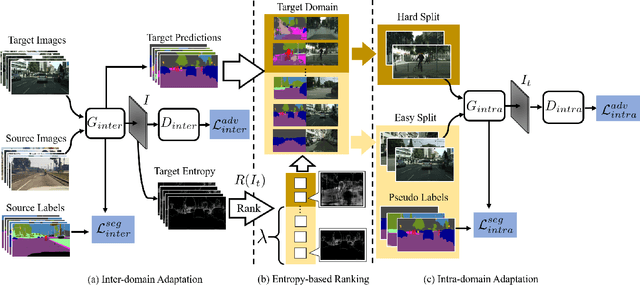

Convolutional neural network-based approaches have achieved remarkable progress in semantic segmentation. However, these approaches heavily rely on annotated data which are labor intensive. To cope with this limitation, automatically annotated data generated from graphic engines are used to train segmentation models. However, the models trained from synthetic data are difficult to transfer to real images. To tackle this issue, previous works have considered directly adapting models from the source data to the unlabeled target data (to reduce the inter-domain gap). Nonetheless, these techniques do not consider the large distribution gap among the target data itself (intra-domain gap). In this work, we propose a two-step self-supervised domain adaptation approach to minimize the inter-domain and intra-domain gap together. First, we conduct the inter-domain adaptation of the model; from this adaptation, we separate the target domain into an easy and hard split using an entropy-based ranking function. Finally, to decrease the intra-domain gap, we propose to employ a self-supervised adaptation technique from the easy to the hard split. Experimental results on numerous benchmark datasets highlight the effectiveness of our method against existing state-of-the-art approaches. The source code is available at https://github.com/feipan664/IntraDA.git.
Image-to-Image Translation via Group-wise Deep Whitening and Coloring Transformation
Dec 24, 2018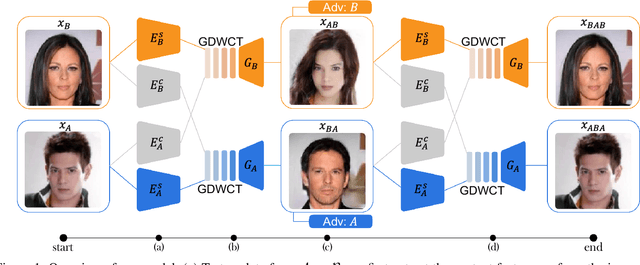
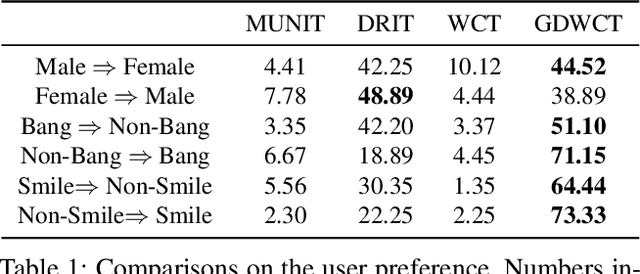
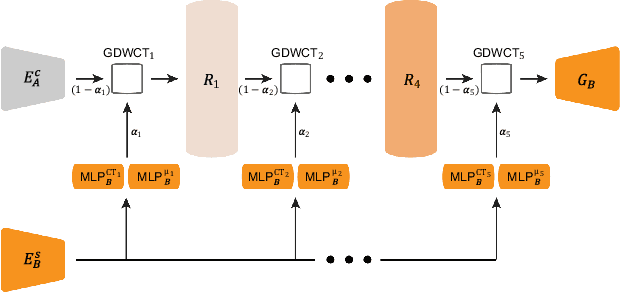
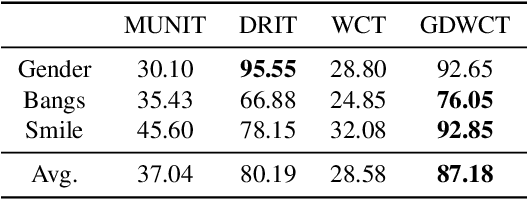
Unsupervised image translation is an active area powered by the advanced generative adversarial networks. Recently introduced models, such as DRIT or MUNIT, utilize a separate encoder in extracting the content and the style of image to successfully incorporate the multimodal nature of image translation. The existing methods, however, overlooks the role that the correlation between feature pairs plays in the overall style. The correlation between feature pairs on top of the mean and the variance of features, are important statistics that define the style of an image. In this regard, we propose an end-to-end framework tailored for image translation that leverages the covariance statistics by whitening the content of an input image followed by coloring to match the covariance statistics with an exemplar. The proposed group-wise deep whitening and coloring (GDWTC) algorithm is motivated by an earlier work of whitening and coloring transformation (WTC), but is augmented to be trained in an end-to-end manner, and with largely reduced computation costs. Our extensive qualitative and quantitative experiments demonstrate that the proposed GDWTC is fast, both in training and inference, and highly effective in reflecting the style of an exemplar.