 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Pool or Not To Pool: Analyzing the Regularizing Effects of Group-Fair Training on Shared Models
Feb 29, 2024In fair machine learning, one source of performance disparities between groups is over-fitting to groups with relatively few training samples. We derive group-specific bounds on the generalization error of welfare-centric fair machine learning that benefit from the larger sample size of the majority group. We do this by considering group-specific Rademacher averages over a restricted hypothesis class, which contains the family of models likely to perform well with respect to a fair learning objective (e.g., a power-mean). Our simulations demonstrate these bounds improve over a naive method, as expected by theory, with particularly significant improvement for smaller group sizes.
Equalizing Credit Opportunity in Algorithms: Aligning Algorithmic Fairness Research with U.S. Fair Lending Regulation
Oct 05, 2022Credit is an essential component of financial wellbeing in America, and unequal access to it is a large factor in the economic disparities between demographic groups that exist today. Today, machine learning algorithms, sometimes trained on alternative data, are increasingly being used to determine access to credit, yet research has shown that machine learning can encode many different versions of "unfairness," thus raising the concern that banks and other financial institutions could -- potentially unwittingly -- engage in illegal discrimination through the use of this technology. In the US, there are laws in place to make sure discrimination does not happen in lending and agencies charged with enforcing them. However, conversations around fair credit models in computer science and in policy are often misaligned: fair machine learning research often lacks legal and practical considerations specific to existing fair lending policy, and regulators have yet to issue new guidance on how, if at all, credit risk models should be utilizing practices and techniques from the research community. This paper aims to better align these sides of the conversation. We describe the current state of credit discrimination regulation in the United States, contextualize results from fair ML research to identify the specific fairness concerns raised by the use of machine learning in lending, and discuss regulatory opportunities to address these concerns.
The Fallacy of AI Functionality
Jun 20, 2022
Deployed AI systems often do not work. They can be constructed haphazardly, deployed indiscriminately, and promoted deceptively. However, despite this reality, scholars, the press, and policymakers pay too little attention to functionality. This leads to technical and policy solutions focused on "ethical" or value-aligned deployments, often skipping over the prior question of whether a given system functions, or provides any benefits at all.To describe the harms of various types of functionality failures, we analyze a set of case studies to create a taxonomy of known AI functionality issues. We then point to policy and organizational responses that are often overlooked and become more readily available once functionality is drawn into focus. We argue that functionality is a meaningful AI policy challenge, operating as a necessary first step towards protecting affected communities from algorithmic harm.
Problems with Shapley-value-based explanations as feature importance measures
Feb 25, 2020
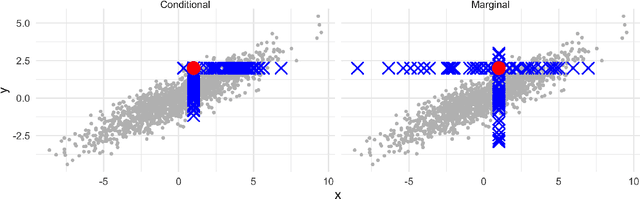
Game-theoretic formulations of feature importance have become popular as a way to "explain" machine learning models. These methods define a cooperative game between the features of a model and distribute influence among these input elements using some form of the game's unique Shapley values. Justification for these methods rests on two pillars: their desirable mathematical properties, and their applicability to specific motivations for explanations. We show that mathematical problems arise when Shapley values are used for feature importance and that the solutions to mitigate these necessarily induce further complexity, such as the need for causal reasoning. We also draw on additional literature to argue that Shapley values do not provide explanations which suit human-centric goals of explainability.