 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Stochastic Variational Inference: Distributed and Asynchronous
Aug 03, 2018
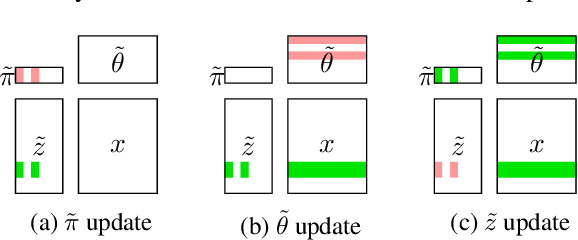
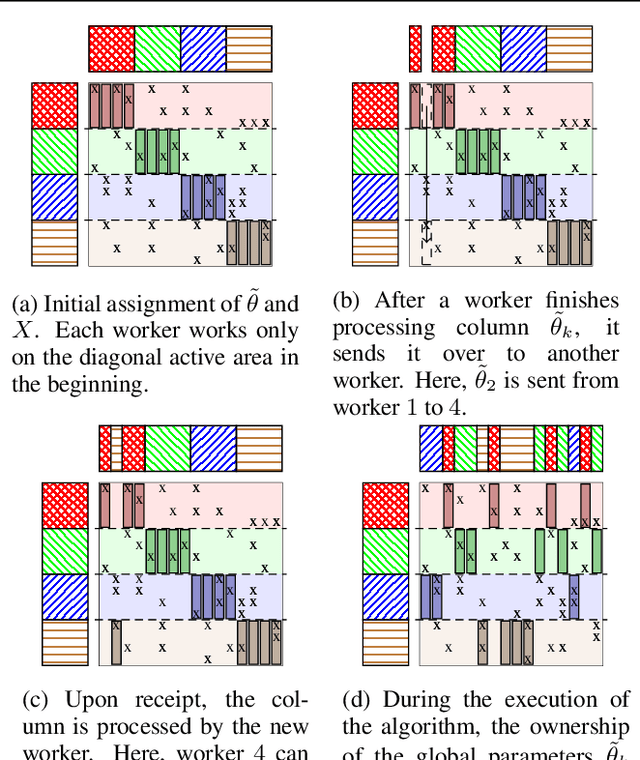
Stochastic variational inference (SVI), the state-of-the-art algorithm for scaling variational inference to large-datasets, is inherently serial. Moreover, it requires the parameters to fit in the memory of a single processor; this is problematic when the number of parameters is in billions. In this paper, we propose extreme stochastic variational inference (ESVI), an asynchronous and lock-free algorithm to perform variational inference for mixture models on massive real world datasets. ESVI overcomes the limitations of SVI by requiring that each processor only access a subset of the data and a subset of the parameters, thus providing data and model parallelism simultaneously. We demonstrate the effectiveness of ESVI by running Latent Dirichlet Allocation (LDA) on UMBC-3B, a dataset that has a vocabulary of 3 million and a token size of 3 billion. In our experiments, we found that ESVI not only outperforms VI and SVI in wallclock-time, but also achieves a better quality solution. In addition, we propose a strategy to speed up computation and save memory when fitting large number of topics.
Nonlinear Inductive Matrix Completion based on One-layer Neural Networks
May 26, 2018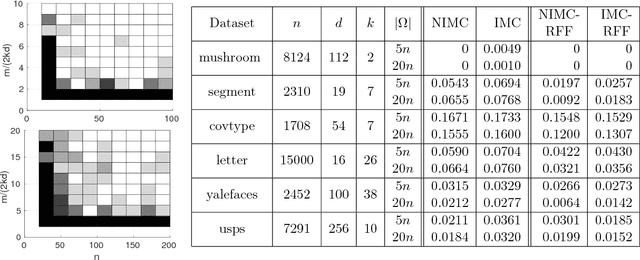

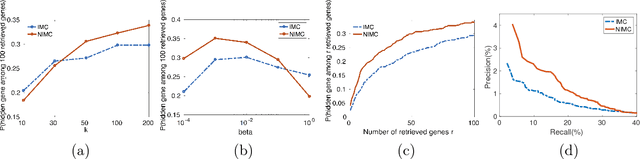
The goal of a recommendation system is to predict the interest of a user in a given item by exploiting the existing set of ratings as well as certain user/item features. A standard approach to modeling this problem is Inductive Matrix Completion where the predicted rating is modeled as an inner product of the user and the item features projected onto a latent space. In order to learn the parameters effectively from a small number of observed ratings, the latent space is constrained to be low-dimensional which implies that the parameter matrix is constrained to be low-rank. However, such bilinear modeling of the ratings can be limiting in practice and non-linear prediction functions can lead to significant improvements. A natural approach to introducing non-linearity in the prediction function is to apply a non-linear activation function on top of the projected user/item features. Imposition of non-linearities further complicates an already challenging problem that has two sources of non-convexity: a) low-rank structure of the parameter matrix, and b) non-linear activation function. We show that one can still solve the non-linear Inductive Matrix Completion problem using gradient descent type methods as long as the solution is initialized well. That is, close to the optima, the optimization function is strongly convex and hence admits standard optimization techniques, at least for certain activation functions, such as Sigmoid and tanh. We also highlight the importance of the activation function and show how ReLU can behave significantly differently than say a sigmoid function. Finally, we apply our proposed technique to recommendation systems and semi-supervised clustering, and show that our method can lead to much better performance than standard linear Inductive Matrix Completion methods.
Stabilizing Gradients for Deep Neural Networks via Efficient SVD Parameterization
Mar 25, 2018
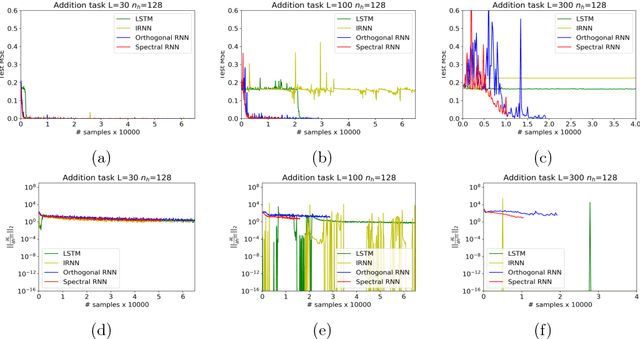
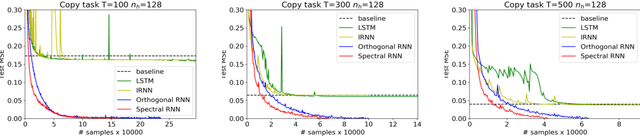

Vanishing and exploding gradients are two of the main obstacles in training deep neural networks, especially in capturing long range dependencies in recurrent neural networks~(RNNs). In this paper, we present an efficient parametrization of the transition matrix of an RNN that allows us to stabilize the gradients that arise in its training. Specifically, we parameterize the transition matrix by its singular value decomposition(SVD), which allows us to explicitly track and control its singular values. We attain efficiency by using tools that are common in numerical linear algebra, namely Householder reflectors for representing the orthogonal matrices that arise in the SVD. By explicitly controlling the singular values, our proposed Spectral-RNN method allows us to easily solve the exploding gradient problem and we observe that it empirically solves the vanishing gradient issue to a large extent. We note that the SVD parameterization can be used for any rectangular weight matrix, hence it can be easily extended to any deep neural network, such as a multi-layer perceptron. Theoretically, we demonstrate that our parameterization does not lose any expressive power, and show how it controls generalization of RNN for the classification task. %, and show how it potentially makes the optimization process easier. Our extensive experimental results also demonstrate that the proposed framework converges faster, and has good generalization, especially in capturing long range dependencies, as shown on the synthetic addition and copy tasks, as well as on MNIST and Penn Tree Bank data sets.
Learning Long Term Dependencies via Fourier Recurrent Units
Mar 17, 2018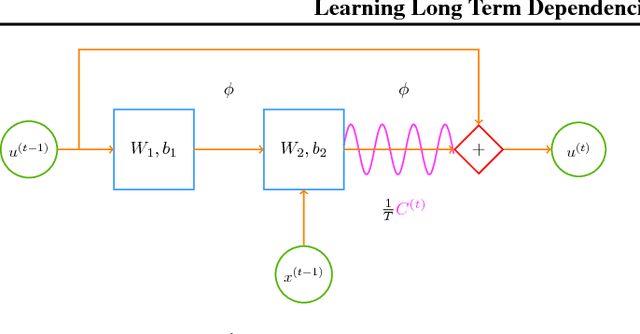
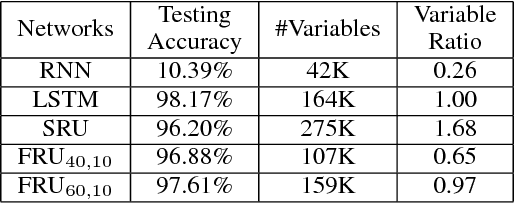
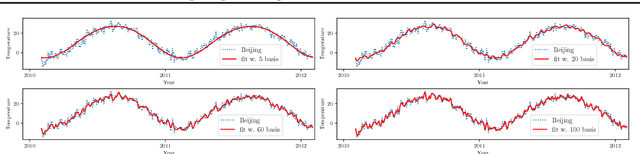
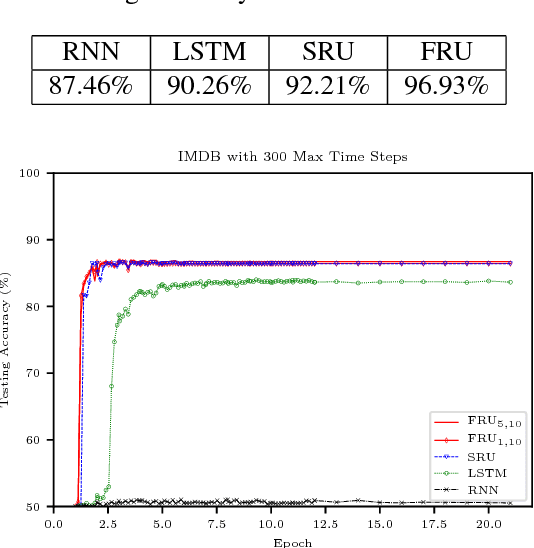
It is a known fact that training recurrent neural networks for tasks that have long term dependencies is challenging. One of the main reasons is the vanishing or exploding gradient problem, which prevents gradient information from propagating to early layers. In this paper we propose a simple recurrent architecture, the Fourier Recurrent Unit (FRU), that stabilizes the gradients that arise in its training while giving us stronger expressive power. Specifically, FRU summarizes the hidden states $h^{(t)}$ along the temporal dimension with Fourier basis functions. This allows gradients to easily reach any layer due to FRU's residual learning structure and the global support of trigonometric functions. We show that FRU has gradient lower and upper bounds independent of temporal dimension. We also show the strong expressivity of sparse Fourier basis, from which FRU obtains its strong expressive power. Our experimental study also demonstrates that with fewer parameters the proposed architecture outperforms other recurrent architectures on many tasks.
Learning Non-overlapping Convolutional Neural Networks with Multiple Kernels
Nov 08, 2017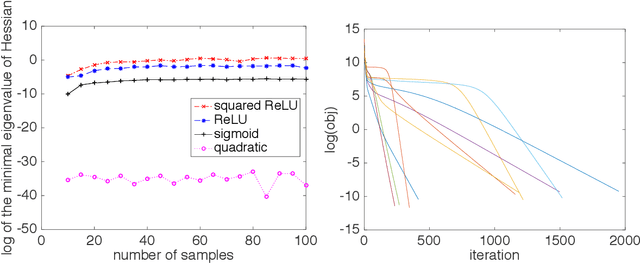

In this paper, we consider parameter recovery for non-overlapping convolutional neural networks (CNNs) with multiple kernels. We show that when the inputs follow Gaussian distribution and the sample size is sufficiently large, the squared loss of such CNNs is $\mathit{~locally~strongly~convex}$ in a basin of attraction near the global optima for most popular activation functions, like ReLU, Leaky ReLU, Squared ReLU, Sigmoid and Tanh. The required sample complexity is proportional to the dimension of the input and polynomial in the number of kernels and a condition number of the parameters. We also show that tensor methods are able to initialize the parameters to the local strong convex region. Hence, for most smooth activations, gradient descent following tensor initialization is guaranteed to converge to the global optimal with time that is linear in input dimension, logarithmic in precision and polynomial in other factors. To the best of our knowledge, this is the first work that provides recovery guarantees for CNNs with multiple kernels under polynomial sample and computational complexities.
Recovery Guarantees for One-hidden-layer Neural Networks
Jun 10, 2017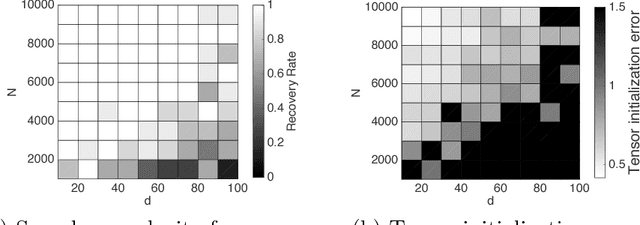

In this paper, we consider regression problems with one-hidden-layer neural networks (1NNs). We distill some properties of activation functions that lead to $\mathit{local~strong~convexity}$ in the neighborhood of the ground-truth parameters for the 1NN squared-loss objective. Most popular nonlinear activation functions satisfy the distilled properties, including rectified linear units (ReLUs), leaky ReLUs, squared ReLUs and sigmoids. For activation functions that are also smooth, we show $\mathit{local~linear~convergence}$ guarantees of gradient descent under a resampling rule. For homogeneous activations, we show tensor methods are able to initialize the parameters to fall into the local strong convexity region. As a result, tensor initialization followed by gradient descent is guaranteed to recover the ground truth with sample complexity $ d \cdot \log(1/\epsilon) \cdot \mathrm{poly}(k,\lambda )$ and computational complexity $n\cdot d \cdot \mathrm{poly}(k,\lambda) $ for smooth homogeneous activations with high probability, where $d$ is the dimension of the input, $k$ ($k\leq d$) is the number of hidden nodes, $\lambda$ is a conditioning property of the ground-truth parameter matrix between the input layer and the hidden layer, $\epsilon$ is the targeted precision and $n$ is the number of samples. To the best of our knowledge, this is the first work that provides recovery guarantees for 1NNs with both sample complexity and computational complexity $\mathit{linear}$ in the input dimension and $\mathit{logarithmic}$ in the precision.
Similarity Preserving Representation Learning for Time Series Analysis
Mar 09, 2017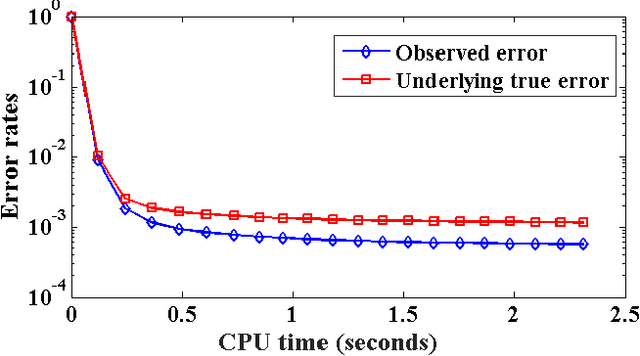
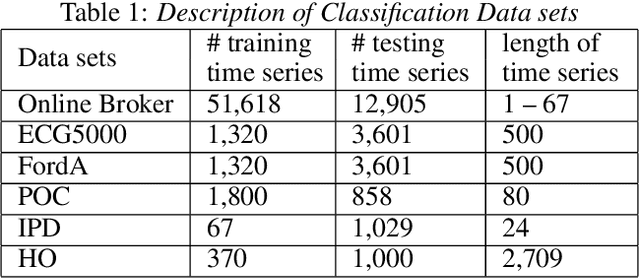
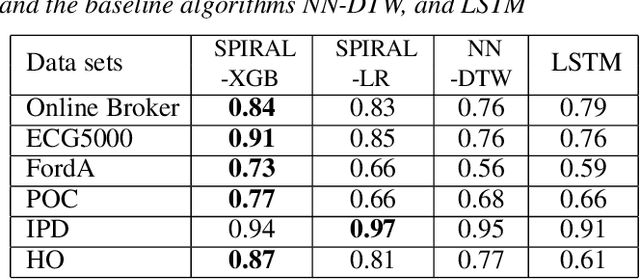
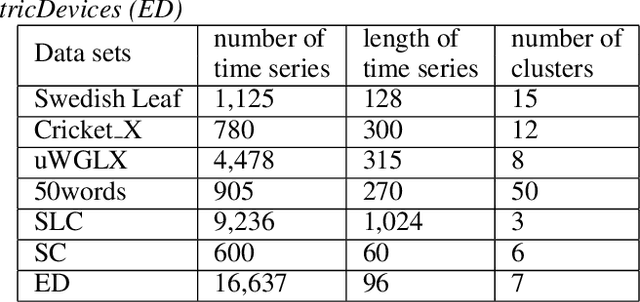
A considerable amount of machine learning algorithms take instance-feature matrices as their inputs. As such, they cannot directly analyze time series data due to its temporal nature, usually unequal lengths, and complex properties. This is a great pity since many of these algorithms are effective, robust, efficient, and easy to use. In this paper, we bridge this gap by proposing an efficient representation learning framework that is able to convert a set of time series with equal or unequal lengths to a matrix format. In particular, we guarantee that the pairwise similarities between time series are well preserved after the transformation. The learned feature representation is particularly suitable to the class of learning problems that are sensitive to data similarities. Given a set of $n$ time series, we first construct an $n\times n$ partially observed similarity matrix by randomly sampling $O(n \log n)$ pairs of time series and computing their pairwise similarities. We then propose an extremely efficient algorithm that solves a highly non-convex and NP-hard problem to learn new features based on the partially observed similarity matrix. We use the learned features to conduct experiments on both data classification and clustering tasks. Our extensive experimental results demonstrate that the proposed framework is both effective and efficient.
A Greedy Approach for Budgeted Maximum Inner Product Search
Oct 11, 2016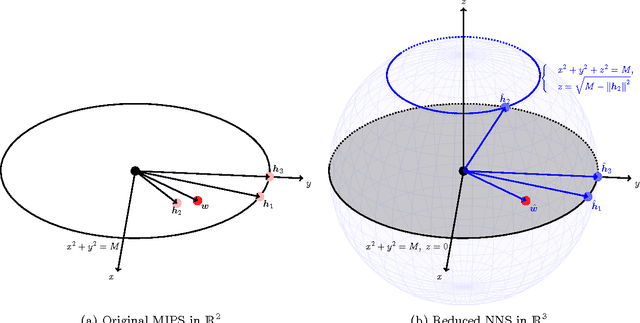
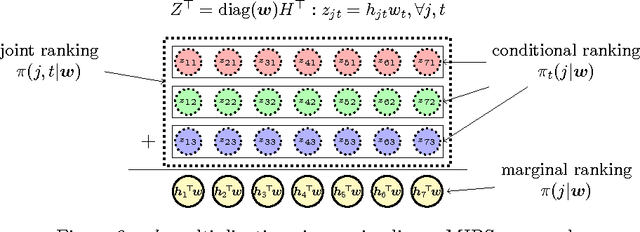
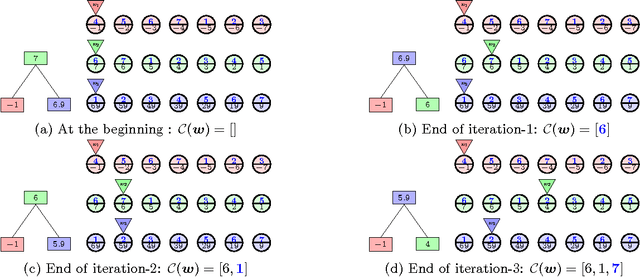
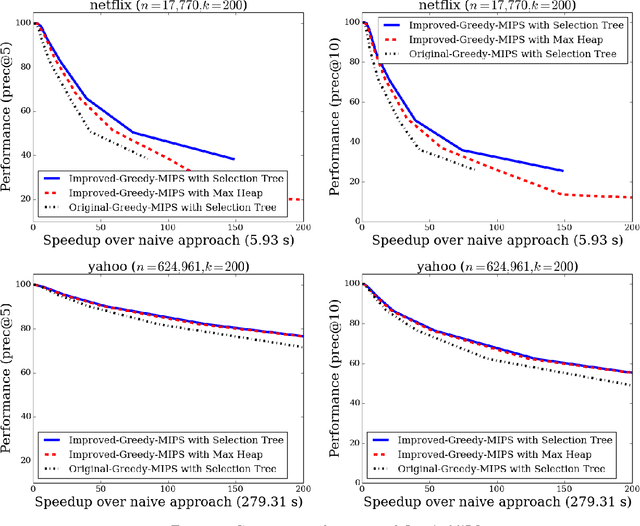
Maximum Inner Product Search (MIPS) is an important task in many machine learning applications such as the prediction phase of a low-rank matrix factorization model for a recommender system. There have been some works on how to perform MIPS in sub-linear time recently. However, most of them do not have the flexibility to control the trade-off between search efficient and search quality. In this paper, we study the MIPS problem with a computational budget. By carefully studying the problem structure of MIPS, we develop a novel Greedy-MIPS algorithm, which can handle budgeted MIPS by design. While simple and intuitive, Greedy-MIPS yields surprisingly superior performance compared to state-of-the-art approaches. As a specific example, on a candidate set containing half a million vectors of dimension 200, Greedy-MIPS runs 200x faster than the naive approach while yielding search results with the top-5 precision greater than 75\%.
Communication-Efficient Parallel Block Minimization for Kernel Machines
Aug 05, 2016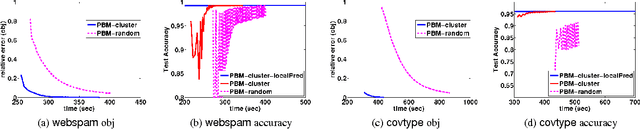
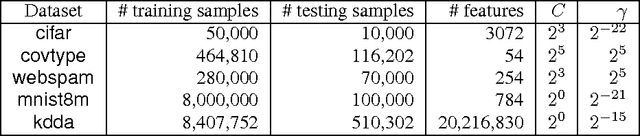
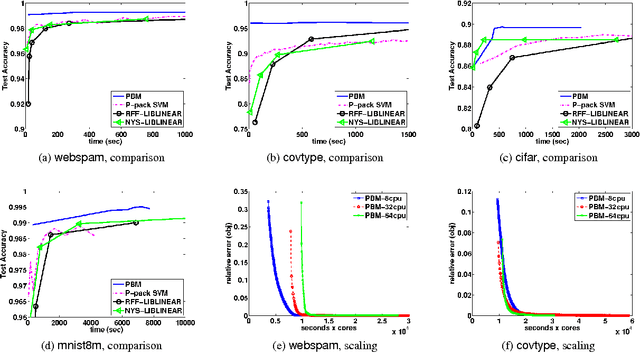
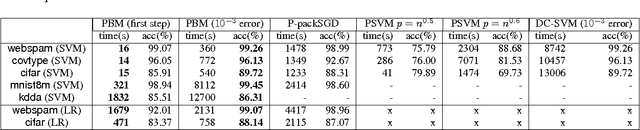
Kernel machines often yield superior predictive performance on various tasks; however, they suffer from severe computational challenges. In this paper, we show how to overcome the important challenge of speeding up kernel machines. In particular, we develop a parallel block minimization framework for solving kernel machines, including kernel SVM and kernel logistic regression. Our framework proceeds by dividing the problem into smaller subproblems by forming a block-diagonal approximation of the Hessian matrix. The subproblems are then solved approximately in parallel. After that, a communication efficient line search procedure is developed to ensure sufficient reduction of the objective function value at each iteration. We prove global linear convergence rate of the proposed method with a wide class of subproblem solvers, and our analysis covers strongly convex and some non-strongly convex functions. We apply our algorithm to solve large-scale kernel SVM problems on distributed systems, and show a significant improvement over existing parallel solvers. As an example, on the covtype dataset with half-a-million samples, our algorithm can obtain an approximate solution with 96% accuracy in 20 seconds using 32 machines, while all the other parallel kernel SVM solvers require more than 2000 seconds to achieve a solution with 95% accuracy. Moreover, our algorithm can scale to very large data sets, such as the kdd algebra dataset with 8 million samples and 20 million features.
Square Root Graphical Models: Multivariate Generalizations of Univariate Exponential Families that Permit Positive Dependencies
Jun 10, 2016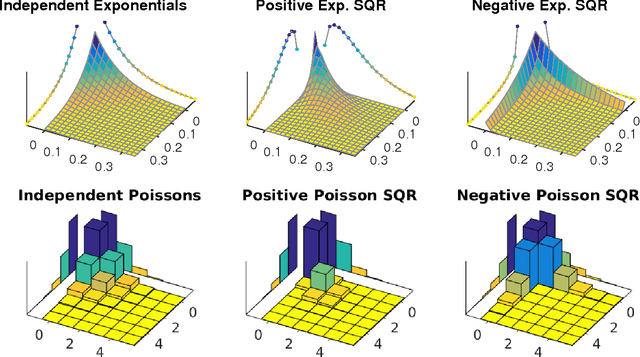
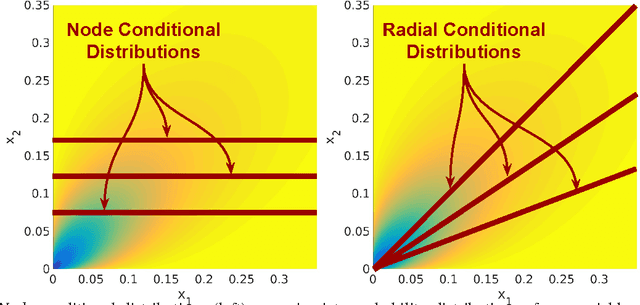
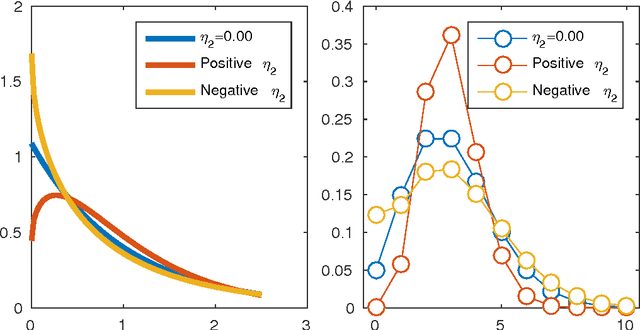
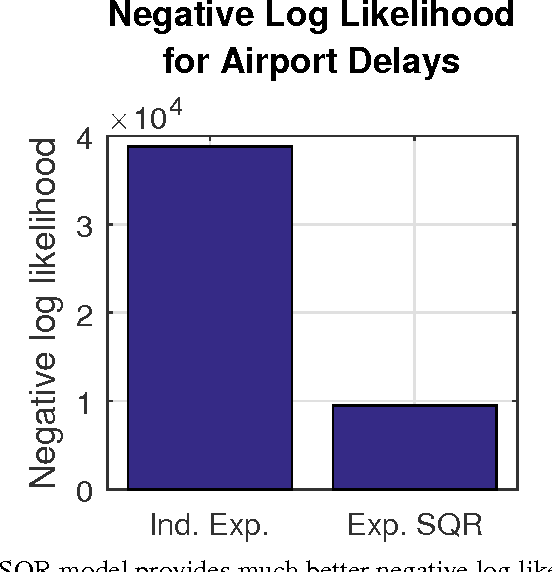
We develop Square Root Graphical Models (SQR), a novel class of parametric graphical models that provides multivariate generalizations of univariate exponential family distributions. Previous multivariate graphical models [Yang et al. 2015] did not allow positive dependencies for the exponential and Poisson generalizations. However, in many real-world datasets, variables clearly have positive dependencies. For example, the airport delay time in New York---modeled as an exponential distribution---is positively related to the delay time in Boston. With this motivation, we give an example of our model class derived from the univariate exponential distribution that allows for almost arbitrary positive and negative dependencies with only a mild condition on the parameter matrix---a condition akin to the positive definiteness of the Gaussian covariance matrix. Our Poisson generalization allows for both positive and negative dependencies without any constraints on the parameter values. We also develop parameter estimation methods using node-wise regressions with $\ell_1$ regularization and likelihood approximation methods using sampling. Finally, we demonstrate our exponential generalization on a synthetic dataset and a real-world dataset of airport delay times.