 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning
Aug 16, 2022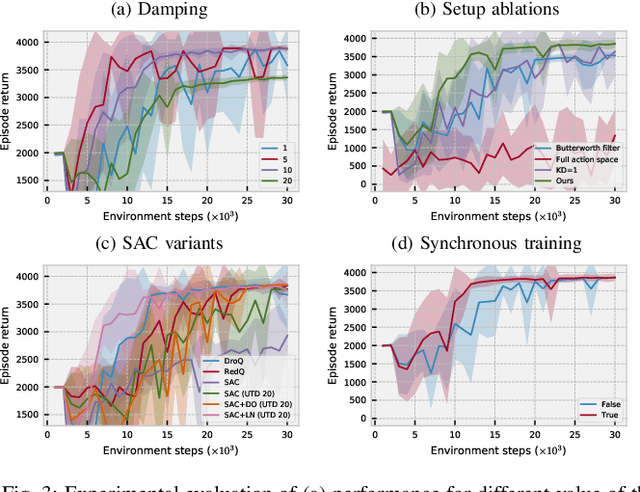

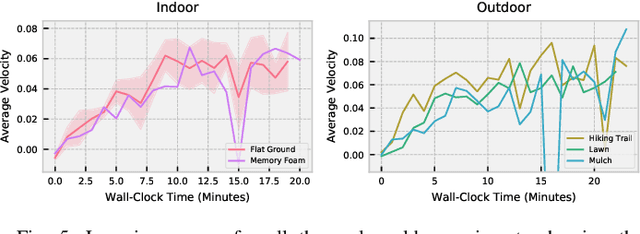
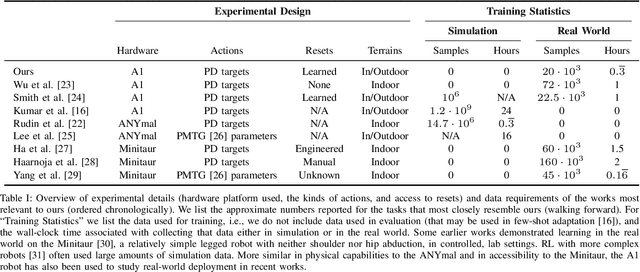
Deep reinforcement learning is a promising approach to learning policies in uncontrolled environments that do not require domain knowledge. Unfortunately, due to sample inefficiency, deep RL applications have primarily focused on simulated environments. In this work, we demonstrate that the recent advancements in machine learning algorithms and libraries combined with a carefully tuned robot controller lead to learning quadruped locomotion in only 20 minutes in the real world. We evaluate our approach on several indoor and outdoor terrains which are known to be challenging for classical model-based controllers. We observe the robot to be able to learn walking gait consistently on all of these terrains. Finally, we evaluate our design decisions in a simulated environment.
In Defense of the Unitary Scalarization for Deep Multi-Task Learning
Jan 20, 2022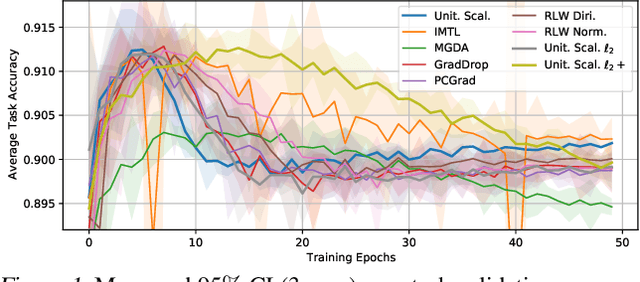
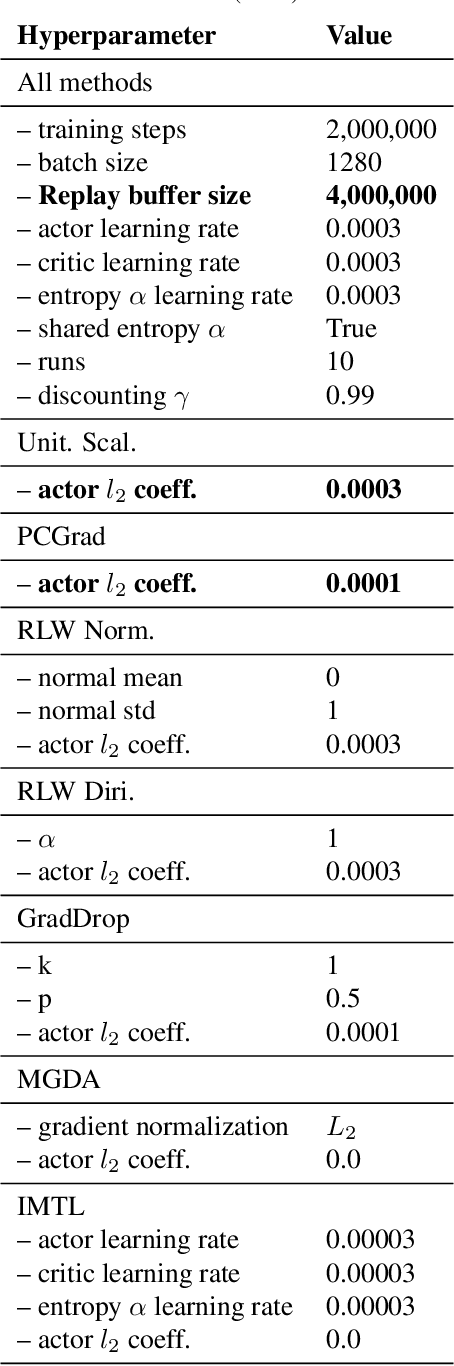


Recent multi-task learning research argues against unitary scalarization, where training simply minimizes the sum of the task losses. Several ad-hoc multi-task optimization algorithms have instead been proposed, inspired by various hypotheses about what makes multi-task settings difficult. The majority of these optimizers require per-task gradients, and introduce significant memory, runtime, and implementation overhead. We present a theoretical analysis suggesting that many specialized multi-task optimizers can be interpreted as forms of regularization. Moreover, we show that, when coupled with standard regularization and stabilization techniques from single-task learning, unitary scalarization matches or improves upon the performance of complex multi-task optimizers in both supervised and reinforcement learning settings. We believe our results call for a critical reevaluation of recent research in the area.
RvS: What is Essential for Offline RL via Supervised Learning?
Dec 20, 2021



Recent work has shown that supervised learning alone, without temporal difference (TD) learning, can be remarkably effective for offline RL. When does this hold true, and which algorithmic components are necessary? Through extensive experiments, we boil supervised learning for offline RL down to its essential elements. In every environment suite we consider, simply maximizing likelihood with a two-layer feedforward MLP is competitive with state-of-the-art results of substantially more complex methods based on TD learning or sequence modeling with Transformers. Carefully choosing model capacity (e.g., via regularization or architecture) and choosing which information to condition on (e.g., goals or rewards) are critical for performance. These insights serve as a field guide for practitioners doing Reinforcement Learning via Supervised Learning (which we coin "RvS learning"). They also probe the limits of existing RvS methods, which are comparatively weak on random data, and suggest a number of open problems.
Improving Zero-shot Generalization in Offline Reinforcement Learning using Generalized Similarity Functions
Nov 29, 2021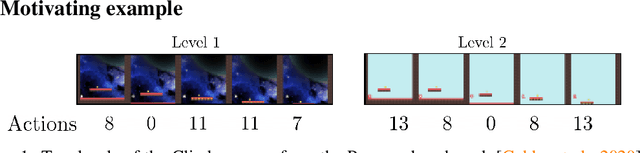

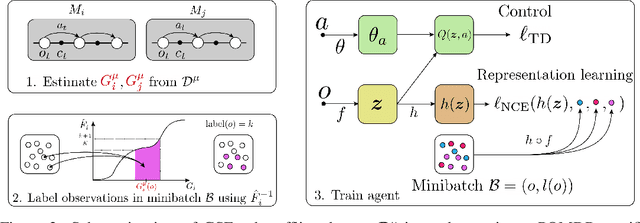
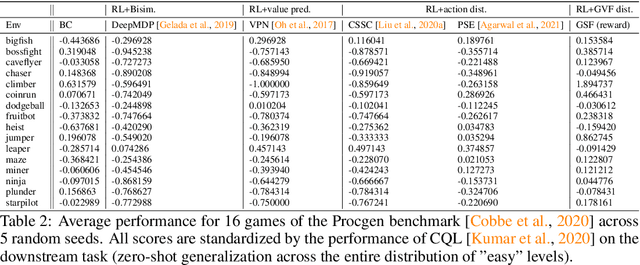
Reinforcement learning (RL) agents are widely used for solving complex sequential decision making tasks, but still exhibit difficulty in generalizing to scenarios not seen during training. While prior online approaches demonstrated that using additional signals beyond the reward function can lead to better generalization capabilities in RL agents, i.e. using self-supervised learning (SSL), they struggle in the offline RL setting, i.e. learning from a static dataset. We show that performance of online algorithms for generalization in RL can be hindered in the offline setting due to poor estimation of similarity between observations. We propose a new theoretically-motivated framework called Generalized Similarity Functions (GSF), which uses contrastive learning to train an offline RL agent to aggregate observations based on the similarity of their expected future behavior, where we quantify this similarity using \emph{generalized value functions}. We show that GSF is general enough to recover existing SSL objectives while also improving zero-shot generalization performance on a complex offline RL benchmark, offline Procgen.
Offline Reinforcement Learning with Implicit Q-Learning
Oct 12, 2021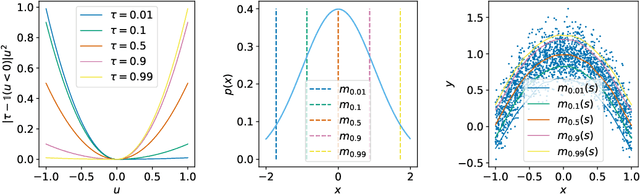
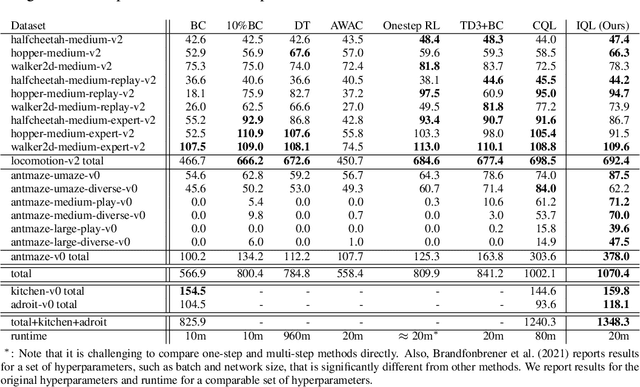
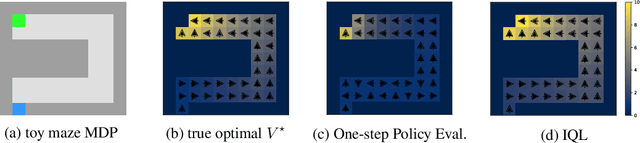
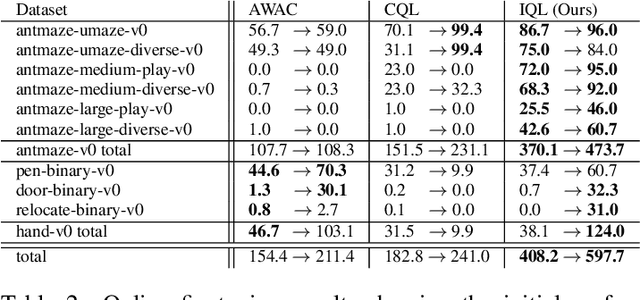
Offline reinforcement learning requires reconciling two conflicting aims: learning a policy that improves over the behavior policy that collected the dataset, while at the same time minimizing the deviation from the behavior policy so as to avoid errors due to distributional shift. This trade-off is critical, because most current offline reinforcement learning methods need to query the value of unseen actions during training to improve the policy, and therefore need to either constrain these actions to be in-distribution, or else regularize their values. We propose an offline RL method that never needs to evaluate actions outside of the dataset, but still enables the learned policy to improve substantially over the best behavior in the data through generalization. The main insight in our work is that, instead of evaluating unseen actions from the latest policy, we can approximate the policy improvement step implicitly by treating the state value function as a random variable, with randomness determined by the action (while still integrating over the dynamics to avoid excessive optimism), and then taking a state conditional upper expectile of this random variable to estimate the value of the best actions in that state. This leverages the generalization capacity of the function approximator to estimate the value of the best available action at a given state without ever directly querying a Q-function with this unseen action. Our algorithm alternates between fitting this upper expectile value function and backing it up into a Q-function. Then, we extract the policy via advantage-weighted behavioral cloning. We dub our method implicit Q-learning (IQL). IQL demonstrates the state-of-the-art performance on D4RL, a standard benchmark for offline reinforcement learning. We also demonstrate that IQL achieves strong performance fine-tuning using online interaction after offline initialization.
Offline Reinforcement Learning with Fisher Divergence Critic Regularization
Mar 14, 2021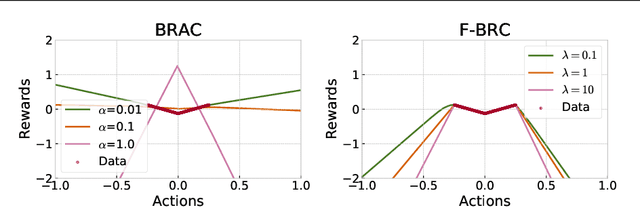
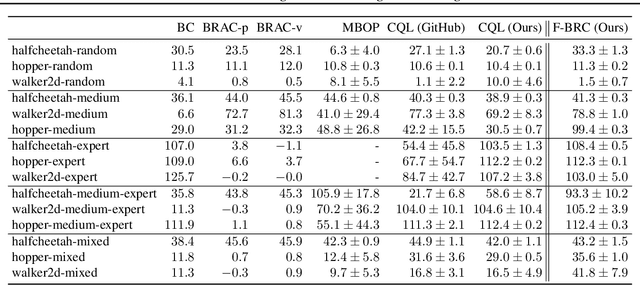
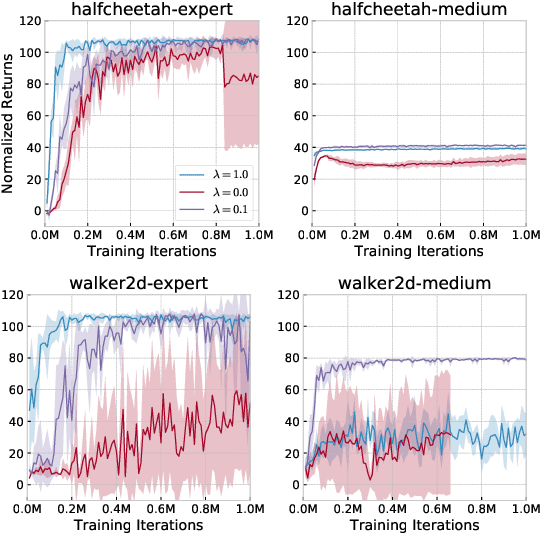
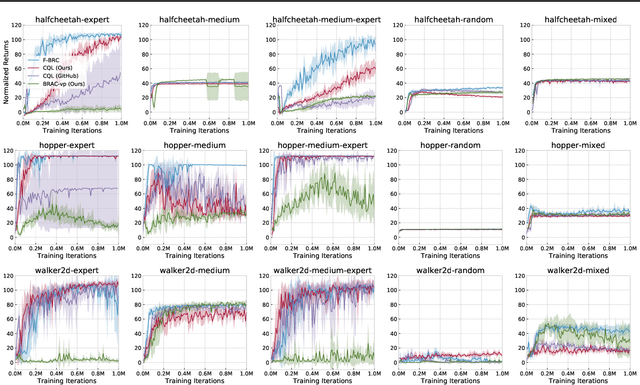
Many modern approaches to offline Reinforcement Learning (RL) utilize behavior regularization, typically augmenting a model-free actor critic algorithm with a penalty measuring divergence of the policy from the offline data. In this work, we propose an alternative approach to encouraging the learned policy to stay close to the data, namely parameterizing the critic as the log-behavior-policy, which generated the offline data, plus a state-action value offset term, which can be learned using a neural network. Behavior regularization then corresponds to an appropriate regularizer on the offset term. We propose using a gradient penalty regularizer for the offset term and demonstrate its equivalence to Fisher divergence regularization, suggesting connections to the score matching and generative energy-based model literature. We thus term our resulting algorithm Fisher-BRC (Behavior Regularized Critic). On standard offline RL benchmarks, Fisher-BRC achieves both improved performance and faster convergence over existing state-of-the-art methods.
Statistical Bootstrapping for Uncertainty Estimation in Off-Policy Evaluation
Jul 27, 2020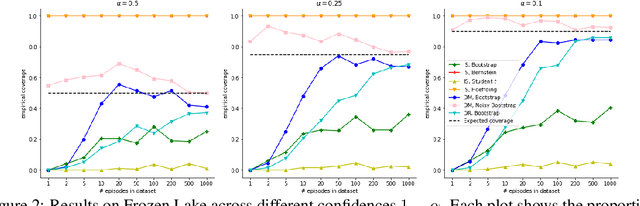
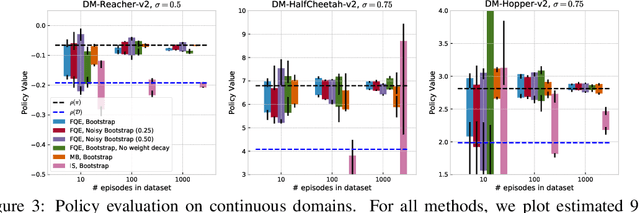
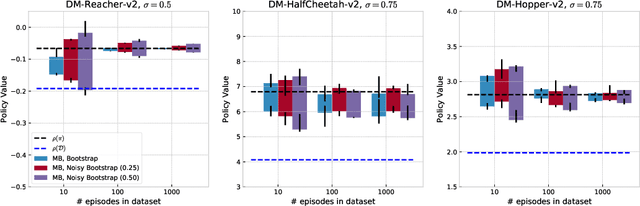
In reinforcement learning, it is typical to use the empirically observed transitions and rewards to estimate the value of a policy via either model-based or Q-fitting approaches. Although straightforward, these techniques in general yield biased estimates of the true value of the policy. In this work, we investigate the potential for statistical bootstrapping to be used as a way to take these biased estimates and produce calibrated confidence intervals for the true value of the policy. We identify conditions - specifically, sufficient data size and sufficient coverage - under which statistical bootstrapping in this setting is guaranteed to yield correct confidence intervals. In practical situations, these conditions often do not hold, and so we discuss and propose mechanisms that can be employed to mitigate their effects. We evaluate our proposed method and show that it can yield accurate confidence intervals in a variety of conditions, including challenging continuous control environments and small data regimes.
Automatic Data Augmentation for Generalization in Deep Reinforcement Learning
Jun 23, 2020
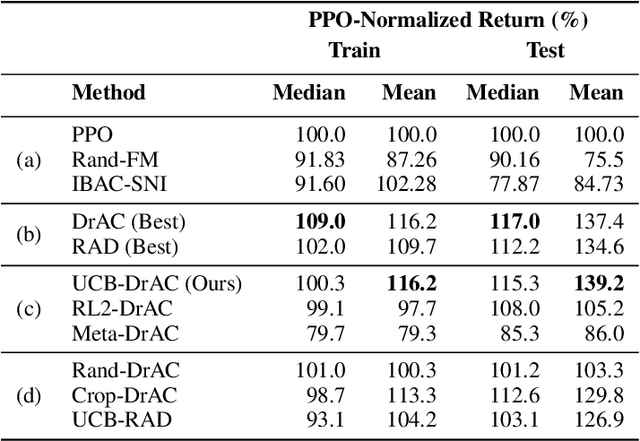
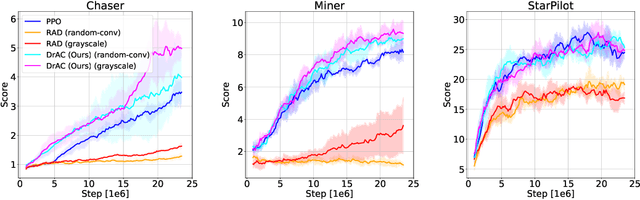
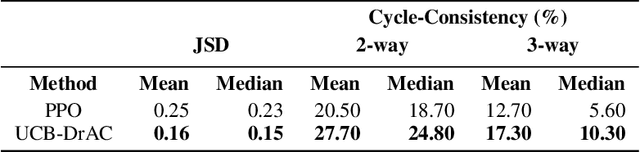
Deep reinforcement learning (RL) agents often fail to generalize to unseen scenarios, even when they are trained on many instances of semantically similar environments. Data augmentation has recently been shown to improve the sample efficiency and generalization of RL agents. However, different tasks tend to benefit from different kinds of data augmentation. In this paper, we compare three approaches for automatically finding an appropriate augmentation. These are combined with two novel regularization terms for the policy and value function, required to make the use of data augmentation theoretically sound for certain actor-critic algorithms. We evaluate our methods on the Procgen benchmark which consists of 16 procedurally-generated environments and show that it improves test performance by ~40% relative to standard RL algorithms. Our agent outperforms other baselines specifically designed to improve generalization in RL. In addition, we show that our agent learns policies and representations that are more robust to changes in the environment that do not affect the agent, such as the background. Our implementation is available at https://github.com/rraileanu/auto-drac.
Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
Apr 28, 2020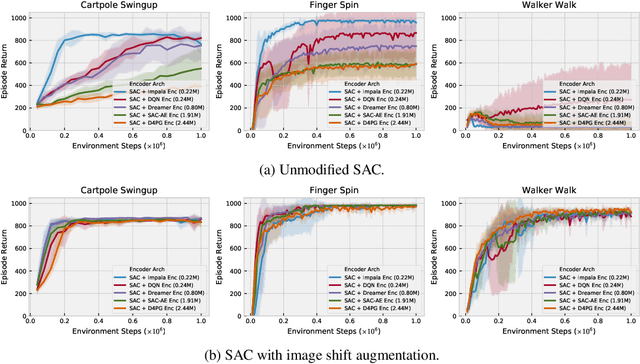
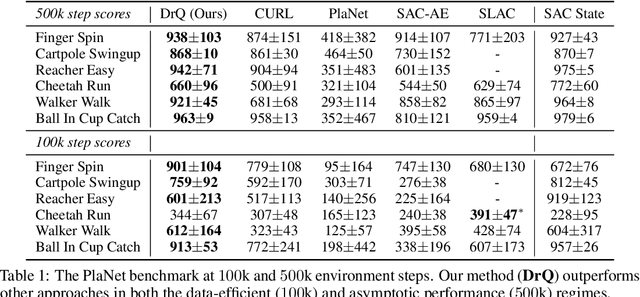
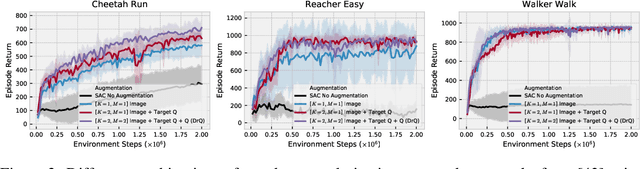
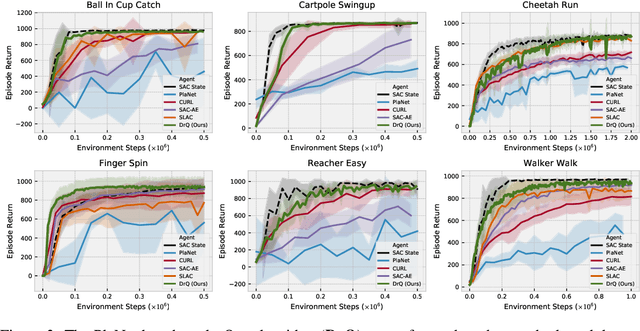
We propose a simple data augmentation technique that can be applied to standard model-free reinforcement learning algorithms, enabling robust learning directly from pixels without the need for auxiliary losses or pre-training. The approach leverages input perturbations commonly used in computer vision tasks to regularize the value function. Existing model-free approaches, such as Soft Actor-Critic (SAC), are not able to train deep networks effectively from image pixels. However, the addition of our augmentation method dramatically improves SAC's performance, enabling it to reach state-of-the-art performance on the DeepMind control suite, surpassing model-based (Dreamer, PlaNet, and SLAC) methods and recently proposed contrastive learning (CURL). Our approach can be combined with any model-free reinforcement learning algorithm, requiring only minor modifications. An implementation can be found at https://sites.google.com/view/data-regularized-q.
Imitation Learning via Off-Policy Distribution Matching
Dec 10, 2019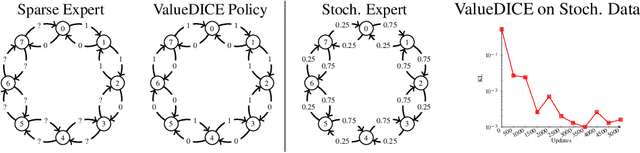
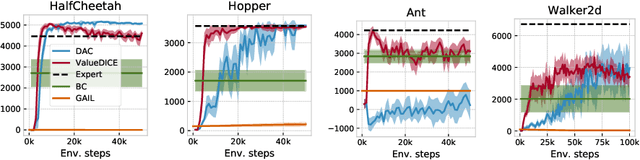
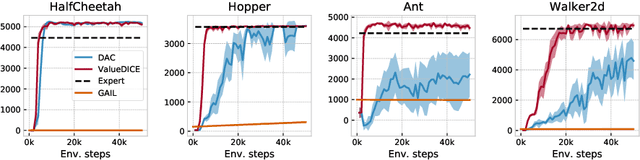
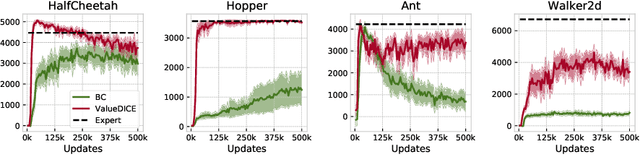
When performing imitation learning from expert demonstrations, distribution matching is a popular approach, in which one alternates between estimating distribution ratios and then using these ratios as rewards in a standard reinforcement learning (RL) algorithm. Traditionally, estimation of the distribution ratio requires on-policy data, which has caused previous work to either be exorbitantly data-inefficient or alter the original objective in a manner that can drastically change its optimum. In this work, we show how the original distribution ratio estimation objective may be transformed in a principled manner to yield a completely off-policy objective. In addition to the data-efficiency that this provides, we are able to show that this objective also renders the use of a separate RL optimization unnecessary.Rather, an imitation policy may be learned directly from this objective without the use of explicit rewards. We call the resulting algorithm ValueDICE and evaluate it on a suite of popular imitation learning benchmarks, finding that it can achieve state-of-the-art sample efficiency and performance.