 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Predictive Distributions: Does Bayesian Deep Learning Work?
Oct 09, 2021
Posterior predictive distributions quantify uncertainties ignored by point estimates. This paper introduces \textit{The Neural Testbed}, which provides tools for the systematic evaluation of agents that generate such predictions. Crucially, these tools assess not only the quality of marginal predictions per input, but also joint predictions given many inputs. Joint distributions are often critical for useful uncertainty quantification, but they have been largely overlooked by the Bayesian deep learning community. We benchmark several approaches to uncertainty estimation using a neural-network-based data generating process. Our results reveal the importance of evaluation beyond marginal predictions. Further, they reconcile sources of confusion in the field, such as why Bayesian deep learning approaches that generate accurate marginal predictions perform poorly in sequential decision tasks, how incorporating priors can be helpful, and what roles epistemic versus aleatoric uncertainty play when evaluating performance. We also present experiments on real-world challenge datasets, which show a high correlation with testbed results, and that the importance of evaluating joint predictive distributions carries over to real data. As part of this effort, we opensource The Neural Testbed, including all implementations from this paper.
Evaluating Probabilistic Inference in Deep Learning: Beyond Marginal Predictions
Jul 20, 2021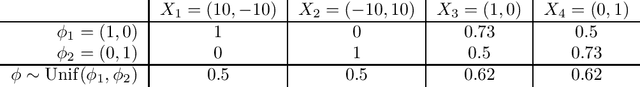
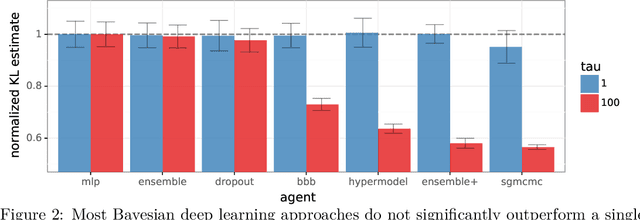
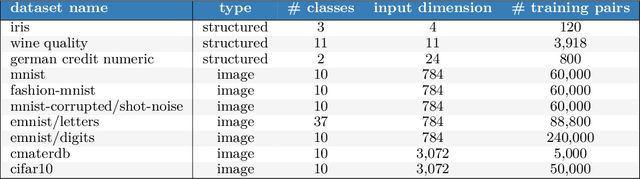
A fundamental challenge for any intelligent system is prediction: given some inputs $X_1,..,X_\tau$ can you predict outcomes $Y_1,.., Y_\tau$. The KL divergence $\mathbf{d}_{\mathrm{KL}}$ provides a natural measure of prediction quality, but the majority of deep learning research looks only at the marginal predictions per input $X_t$. In this technical report we propose a scoring rule $\mathbf{d}_{\mathrm{KL}}^\tau$, parameterized by $\tau \in \mathcal{N}$ that evaluates the joint predictions at $\tau$ inputs simultaneously. We show that the commonly-used $\tau=1$ can be insufficient to drive good decisions in many settings of interest. We also show that, as $\tau$ grows, performing well according to $\mathbf{d}_{\mathrm{KL}}^\tau$ recovers universal guarantees for any possible decision. Finally, we provide problem-dependent guidance on the scale of $\tau$ for which our score provides sufficient guarantees for good performance.
Epistemic Neural Networks
Jul 19, 2021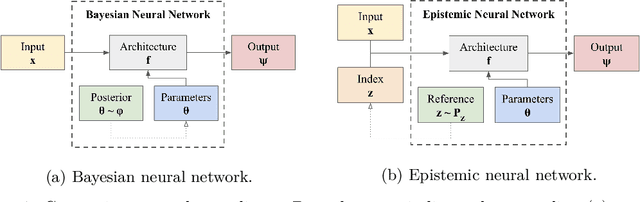
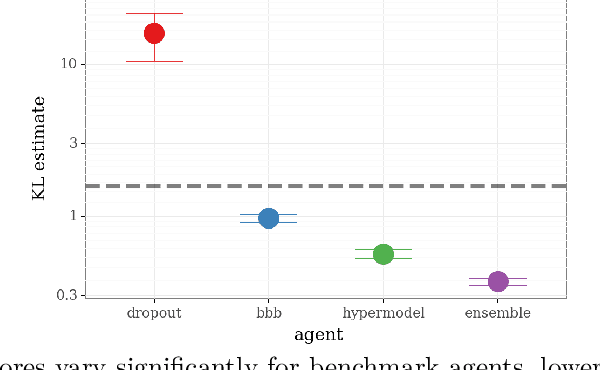
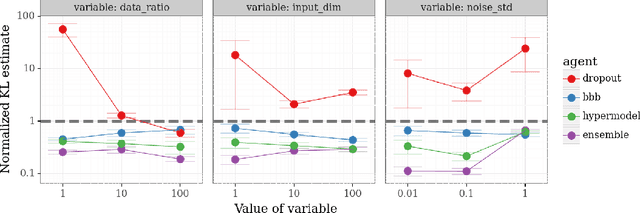
We introduce the \textit{epistemic neural network} (ENN) as an interface for uncertainty modeling in deep learning. All existing approaches to uncertainty modeling can be expressed as ENNs, and any ENN can be identified with a Bayesian neural network. However, this new perspective provides several promising directions for future research. Where prior work has developed probabilistic inference tools for neural networks; we ask instead, `which neural networks are suitable as tools for probabilistic inference?'. We propose a clear and simple metric for progress in ENNs: the KL-divergence with respect to a target distribution. We develop a computational testbed based on inference in a neural network Gaussian process and release our code as a benchmark at \url{https://github.com/deepmind/enn}. We evaluate several canonical approaches to uncertainty modeling in deep learning, and find they vary greatly in their performance. We provide insight to the sensitivity of these results and show that our metric is highly correlated with performance in sequential decision problems. Finally, we provide indications that new ENN architectures can improve performance in both the statistical quality and computational cost.
Reinforcement Learning, Bit by Bit
Mar 14, 2021
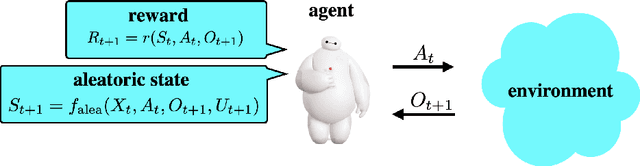

Reinforcement learning agents have demonstrated remarkable achievements in simulated environments. Data efficiency poses an impediment to carrying this success over to real environments. The design of data-efficient agents calls for a deeper understanding of information acquisition and representation. We develop concepts and establish a regret bound that together offer principled guidance. The bound sheds light on questions of what information to seek, how to seek that information, and it what information to retain. To illustrate concepts, we design simple agents that build on them and present computational results that demonstrate improvements in data efficiency.
Hypermodels for Exploration
Jun 12, 2020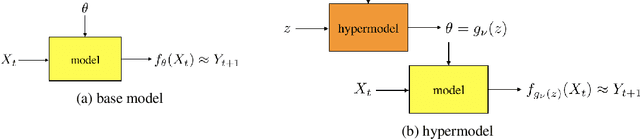
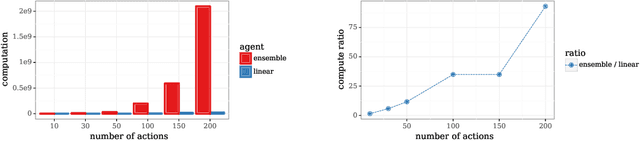
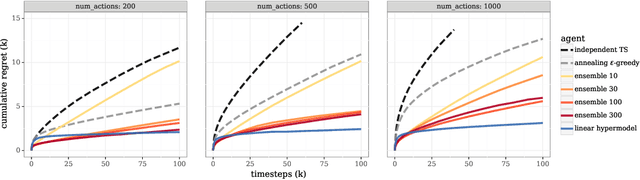
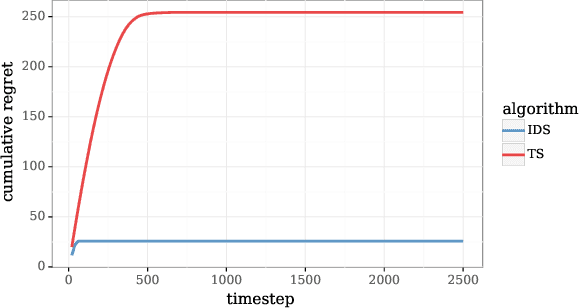
We study the use of hypermodels to represent epistemic uncertainty and guide exploration. This generalizes and extends the use of ensembles to approximate Thompson sampling. The computational cost of training an ensemble grows with its size, and as such, prior work has typically been limited to ensembles with tens of elements. We show that alternative hypermodels can enjoy dramatic efficiency gains, enabling behavior that would otherwise require hundreds or thousands of elements, and even succeed in situations where ensemble methods fail to learn regardless of size. This allows more accurate approximation of Thompson sampling as well as use of more sophisticated exploration schemes. In particular, we consider an approximate form of information-directed sampling and demonstrate performance gains relative to Thompson sampling. As alternatives to ensembles, we consider linear and neural network hypermodels, also known as hypernetworks. We prove that, with neural network base models, a linear hypermodel can represent essentially any distribution over functions, and as such, hypernetworks are no more expressive.
Stochastic matrix games with bandit feedback
Jun 09, 2020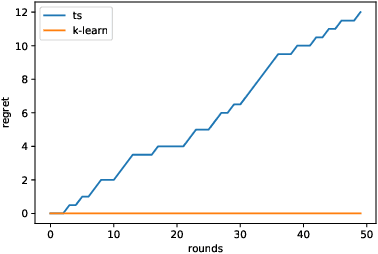

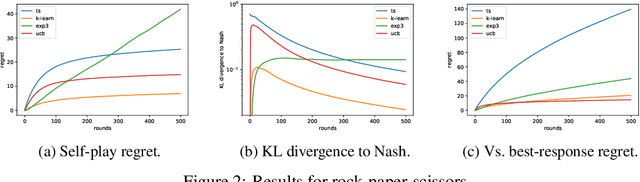
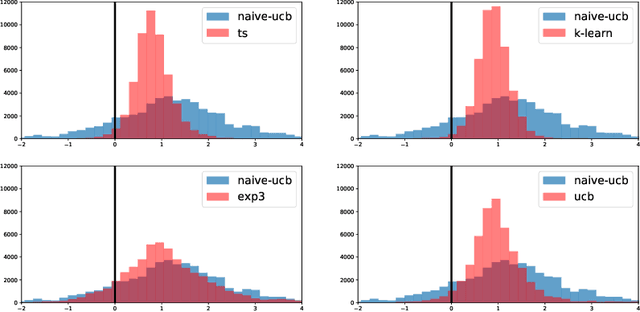
We study a version of the classical zero-sum matrix game with unknown payoff matrix and bandit feedback, where the players only observe each others actions and a noisy payoff. This generalizes the usual matrix game, where the payoff matrix is known to the players. Despite numerous applications, this problem has received relatively little attention. Although adversarial bandit algorithms achieve low regret, they do not exploit the matrix structure and perform poorly relative to the new algorithms. The main contributions are regret analyses of variants of UCB and K-learning that hold for any opponent, e.g., even when the opponent adversarially plays the best response to the learner's mixed strategy. Along the way, we show that Thompson fails catastrophically in this setting and provide empirical comparison to existing algorithms.
Making Sense of Reinforcement Learning and Probabilistic Inference
Feb 14, 2020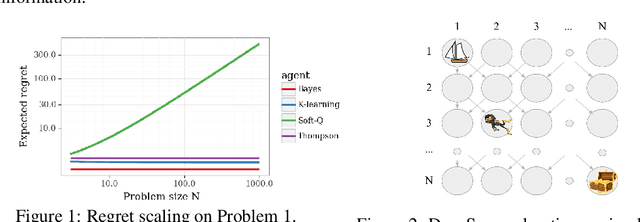
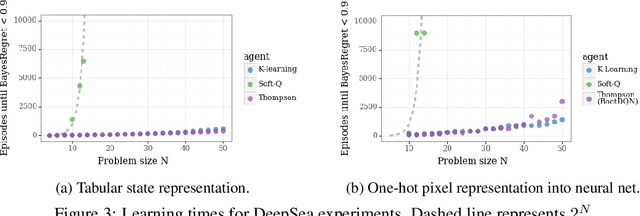
Reinforcement learning (RL) combines a control problem with statistical estimation: The system dynamics are not known to the agent, but can be learned through experience. A recent line of research casts 'RL as inference' and suggests a particular framework to generalize the RL problem as probabilistic inference. Our paper surfaces a key shortcoming in that approach, and clarifies the sense in which RL can be coherently cast as an inference problem. In particular, an RL agent must consider the effects of its actions upon future rewards and observations: The exploration-exploitation tradeoff. In all but the most simple settings, the resulting inference is computationally intractable so that practical RL algorithms must resort to approximation. We demonstrate that the popular 'RL as inference' approximation can perform poorly in even very basic problems. However, we show that with a small modification the framework does yield algorithms that can provably perform well, and we show that the resulting algorithm is equivalent to the recently proposed K-learning, which we further connect with Thompson sampling.
Behaviour Suite for Reinforcement Learning
Aug 13, 2019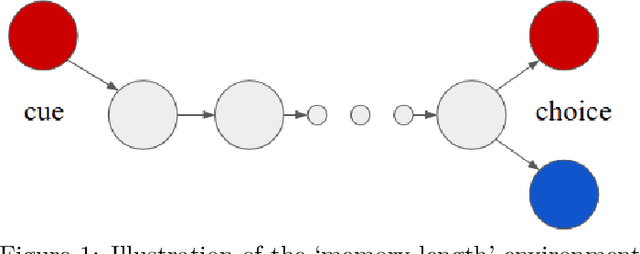
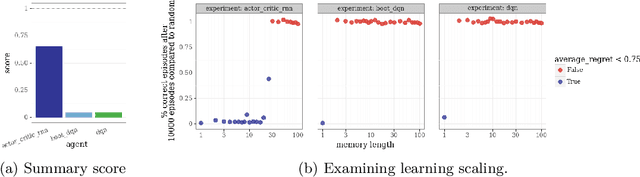
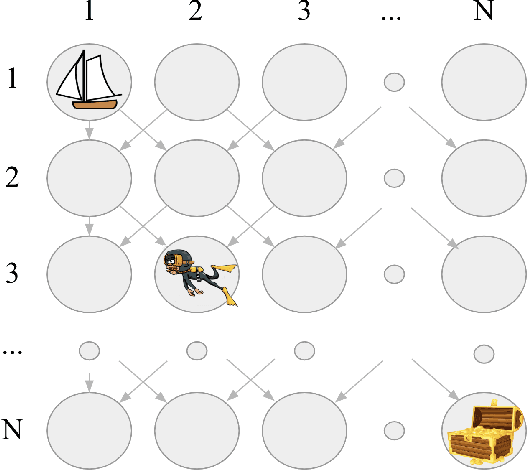
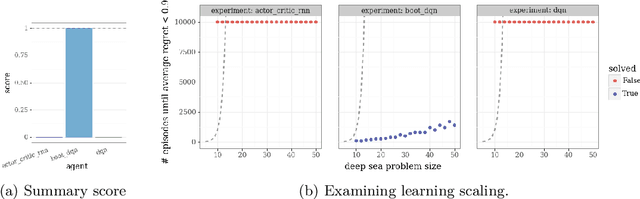
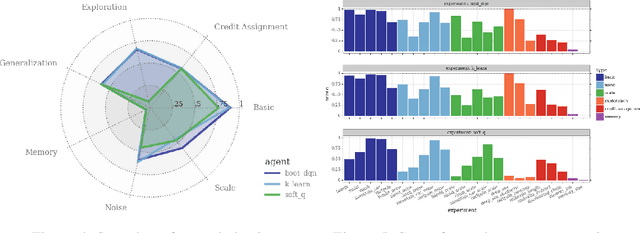
This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks. To complement this effort, we open source github.com/deepmind/bsuite, which automates evaluation and analysis of any agent on bsuite. This library facilitates reproducible and accessible research on the core issues in RL, and ultimately the design of superior learning algorithms. Our code is Python, and easy to use within existing projects. We include examples with OpenAI Baselines, Dopamine as well as new reference implementations. Going forward, we hope to incorporate more excellent experiments from the research community, and commit to a periodic review of bsuite from a committee of prominent researchers.
Meta-learning of Sequential Strategies
May 08, 2019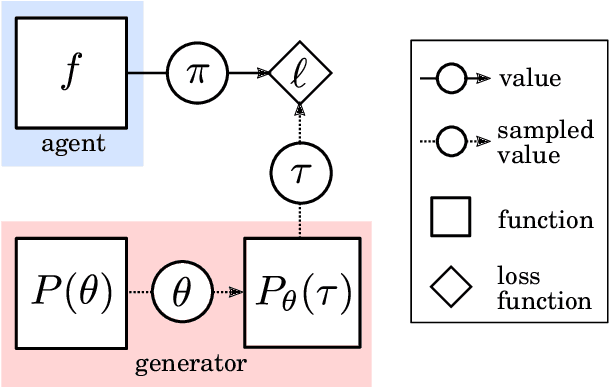
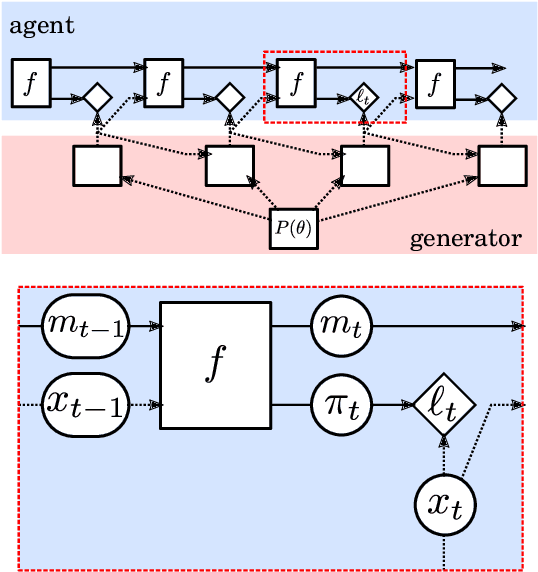
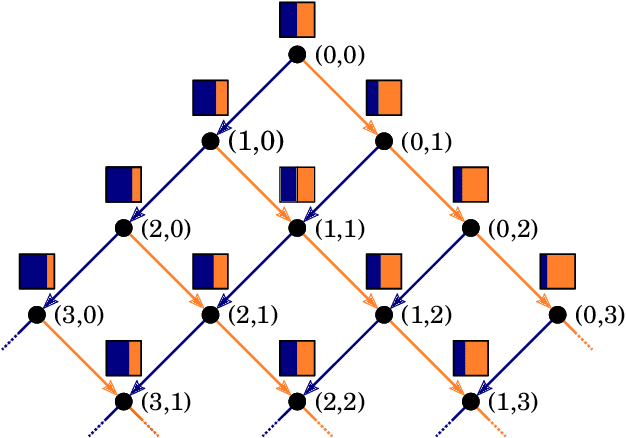
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
The Uncertainty Bellman Equation and Exploration
Oct 22, 2018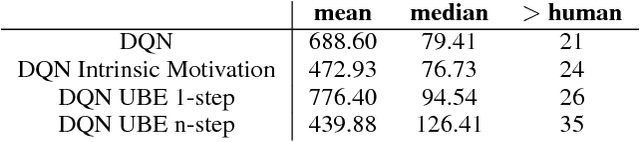
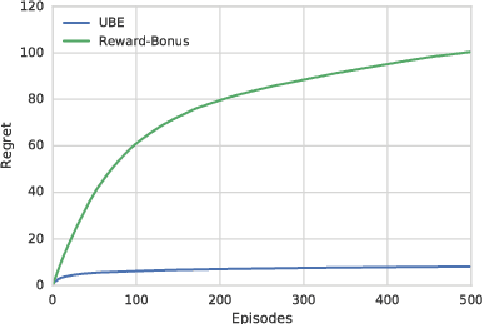
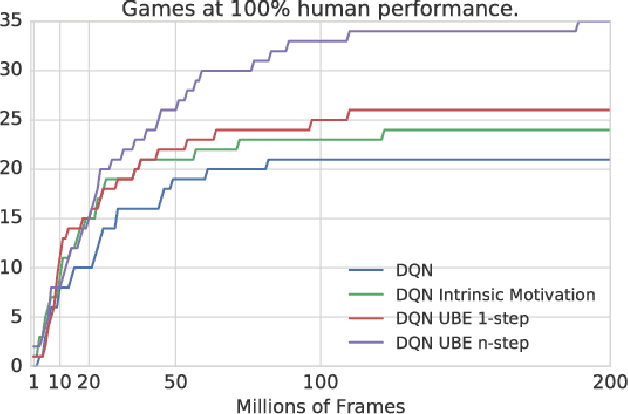
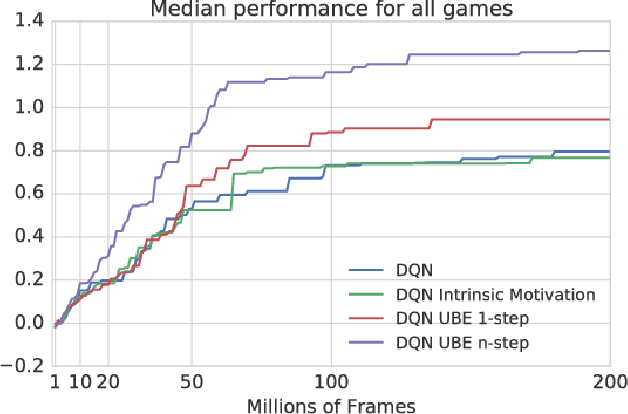
We consider the exploration/exploitation problem in reinforcement learning. For exploitation, it is well known that the Bellman equation connects the value at any time-step to the expected value at subsequent time-steps. In this paper we consider a similar \textit{uncertainty} Bellman equation (UBE), which connects the uncertainty at any time-step to the expected uncertainties at subsequent time-steps, thereby extending the potential exploratory benefit of a policy beyond individual time-steps. We prove that the unique fixed point of the UBE yields an upper bound on the variance of the posterior distribution of the Q-values induced by any policy. This bound can be much tighter than traditional count-based bonuses that compound standard deviation rather than variance. Importantly, and unlike several existing approaches to optimism, this method scales naturally to large systems with complex generalization. Substituting our UBE-exploration strategy for $\epsilon$-greedy improves DQN performance on 51 out of 57 games in the Atari suite.