 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Preserving Two-Stage Video Domain Translation for Portrait Stylization
May 30, 2023



Portrait stylization, which translates a real human face image into an artistically stylized image, has attracted considerable interest and many prior works have shown impressive quality in recent years. However, despite their remarkable performances in the image-level translation tasks, prior methods show unsatisfactory results when they are applied to the video domain. To address the issue, we propose a novel two-stage video translation framework with an objective function which enforces a model to generate a temporally coherent stylized video while preserving context in the source video. Furthermore, our model runs in real-time with the latency of 0.011 seconds per frame and requires only 5.6M parameters, and thus is widely applicable to practical real-world applications.
Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance
Feb 26, 2023With the advantages of fast inference and human-friendly flexible manipulation, image-agnostic style manipulation via text guidance enables new applications that were not previously available. The state-of-the-art text-guided image-agnostic manipulation method embeds the representation of each channel of StyleGAN independently in the Contrastive Language-Image Pre-training (CLIP) space, and provides it in the form of a Dictionary to quickly find out the channel-wise manipulation direction during inference time. However, in this paper we argue that this dictionary which is constructed by controlling single channel individually is limited to accommodate the versatility of text guidance since the collective and interactive relation among multiple channels are not considered. Indeed, we show that it fails to discover a large portion of manipulation directions that can be found by existing methods, which manually manipulates latent space without texts. To alleviate this issue, we propose a novel method that learns a Dictionary, whose entry corresponds to the representation of a single channel, by taking into account the manipulation effect coming from the interaction with multiple other channels. We demonstrate that our strategy resolves the inability of previous methods in finding diverse known directions from unsupervised methods and unknown directions from random text while maintaining the real-time inference speed and disentanglement ability.
3D-aware Blending with Generative NeRFs
Feb 13, 2023Image blending aims to combine multiple images seamlessly. It remains challenging for existing 2D-based methods, especially when input images are misaligned due to differences in 3D camera poses and object shapes. To tackle these issues, we propose a 3D-aware blending method using generative Neural Radiance Fields (NeRF), including two key components: 3D-aware alignment and 3D-aware blending. For 3D-aware alignment, we first estimate the camera pose of the reference image with respect to generative NeRFs and then perform 3D local alignment for each part. To further leverage 3D information of the generative NeRF, we propose 3D-aware blending that directly blends images on the NeRF's latent representation space, rather than raw pixel space. Collectively, our method outperforms existing 2D baselines, as validated by extensive quantitative and qualitative evaluations with FFHQ and AFHQ-Cat.
BallGAN: 3D-aware Image Synthesis with a Spherical Background
Jan 22, 2023



3D-aware GANs aim to synthesize realistic 3D scenes such that they can be rendered in arbitrary perspectives to produce images. Although previous methods produce realistic images, they suffer from unstable training or degenerate solutions where the 3D geometry is unnatural. We hypothesize that the 3D geometry is underdetermined due to the insufficient constraint, i.e., being classified as real image to the discriminator is not enough. To solve this problem, we propose to approximate the background as a spherical surface and represent a scene as a union of the foreground placed in the sphere and the thin spherical background. It reduces the degree of freedom in the background field. Accordingly, we modify the volume rendering equation and incorporate dedicated constraints to design a novel 3D-aware GAN framework named BallGAN. BallGAN has multiple advantages as follows. 1) It produces more reasonable 3D geometry; the images of a scene across different viewpoints have better photometric consistency and fidelity than the state-of-the-art methods. 2) The training becomes much more stable. 3) The foreground can be separately rendered on top of different arbitrary backgrounds.
Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Dec 06, 2022Inspired by the impressive performance of recent face image editing methods, several studies have been naturally proposed to extend these methods to the face video editing task. One of the main challenges here is temporal consistency among edited frames, which is still unresolved. To this end, we propose a novel face video editing framework based on diffusion autoencoders that can successfully extract the decomposed features - for the first time as a face video editing model - of identity and motion from a given video. This modeling allows us to edit the video by simply manipulating the temporally invariant feature to the desired direction for the consistency. Another unique strength of our model is that, since our model is based on diffusion models, it can satisfy both reconstruction and edit capabilities at the same time, and is robust to corner cases in wild face videos (e.g. occluded faces) unlike the existing GAN-based methods.
Generator Knows What Discriminator Should Learn in Unconditional GANs
Jul 27, 2022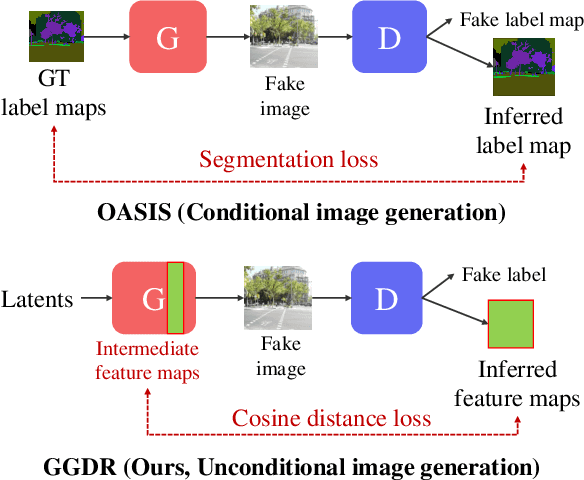
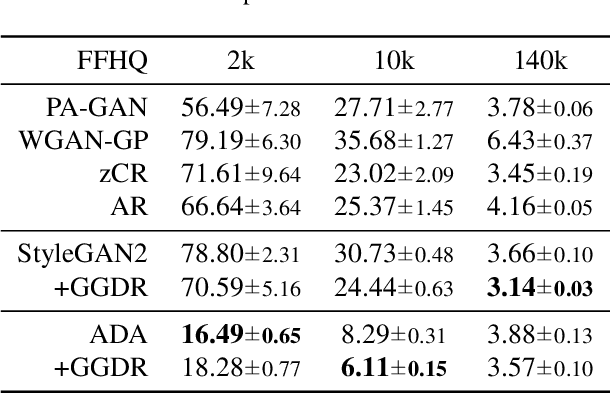
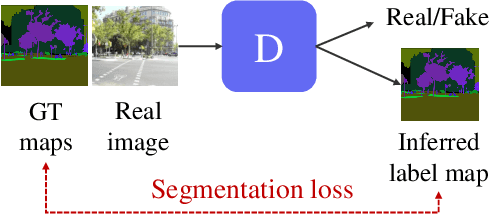
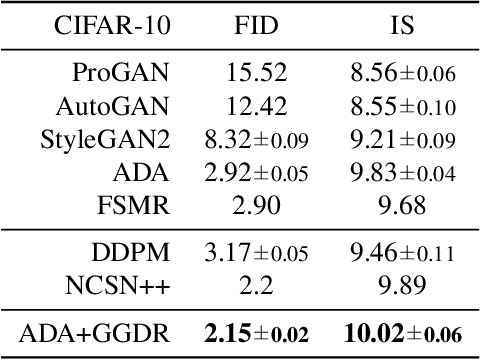
Recent methods for conditional image generation benefit from dense supervision such as segmentation label maps to achieve high-fidelity. However, it is rarely explored to employ dense supervision for unconditional image generation. Here we explore the efficacy of dense supervision in unconditional generation and find generator feature maps can be an alternative of cost-expensive semantic label maps. From our empirical evidences, we propose a new generator-guided discriminator regularization(GGDR) in which the generator feature maps supervise the discriminator to have rich semantic representations in unconditional generation. In specific, we employ an U-Net architecture for discriminator, which is trained to predict the generator feature maps given fake images as inputs. Extensive experiments on mulitple datasets show that our GGDR consistently improves the performance of baseline methods in terms of quantitative and qualitative aspects. Code is available at https://github.com/naver-ai/GGDR
Memory Efficient Patch-based Training for INR-based GANs
Jul 09, 2022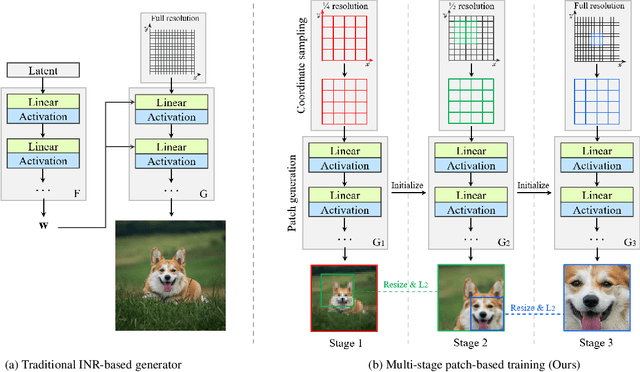
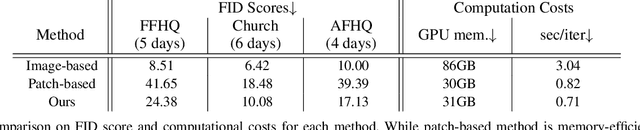


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
Feb 21, 2022
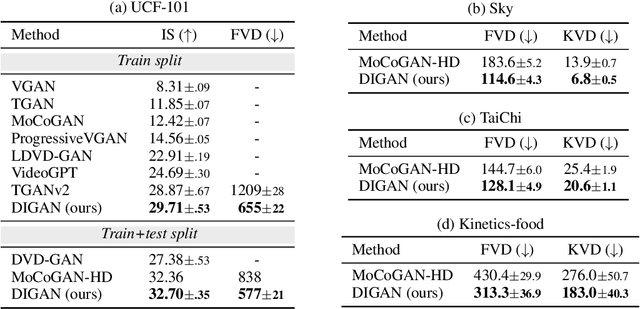
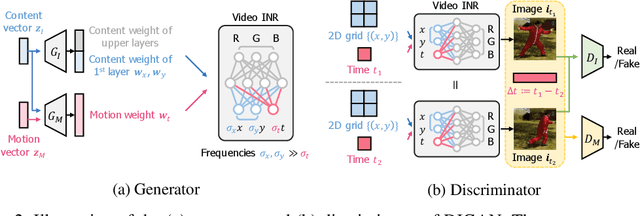
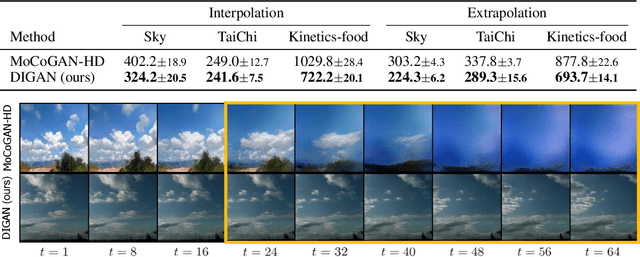
In the deep learning era, long video generation of high-quality still remains challenging due to the spatio-temporal complexity and continuity of videos. Existing prior works have attempted to model video distribution by representing videos as 3D grids of RGB values, which impedes the scale of generated videos and neglects continuous dynamics. In this paper, we found that the recent emerging paradigm of implicit neural representations (INRs) that encodes a continuous signal into a parameterized neural network effectively mitigates the issue. By utilizing INRs of video, we propose dynamics-aware implicit generative adversarial network (DIGAN), a novel generative adversarial network for video generation. Specifically, we introduce (a) an INR-based video generator that improves the motion dynamics by manipulating the space and time coordinates differently and (b) a motion discriminator that efficiently identifies the unnatural motions without observing the entire long frame sequences. We demonstrate the superiority of DIGAN under various datasets, along with multiple intriguing properties, e.g., long video synthesis, video extrapolation, and non-autoregressive video generation. For example, DIGAN improves the previous state-of-the-art FVD score on UCF-101 by 30.7% and can be trained on 128 frame videos of 128x128 resolution, 80 frames longer than the 48 frames of the previous state-of-the-art method.
StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
Apr 30, 2021
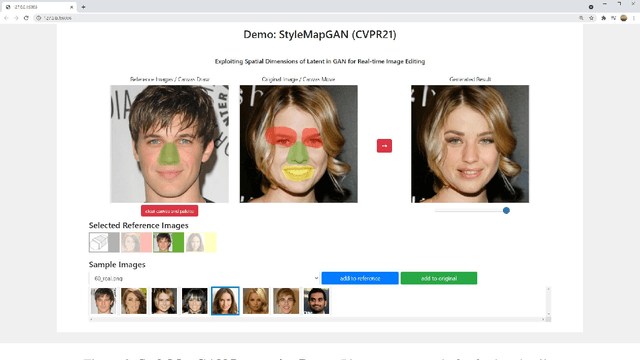
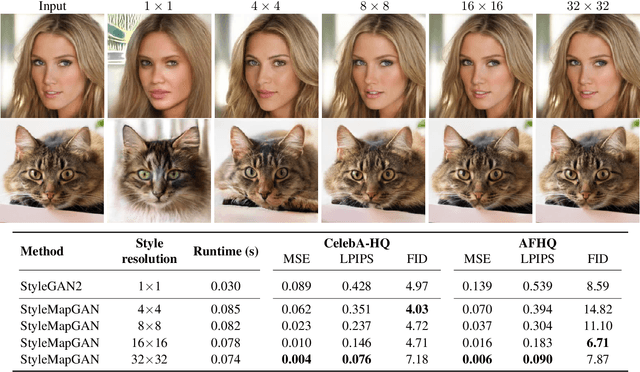
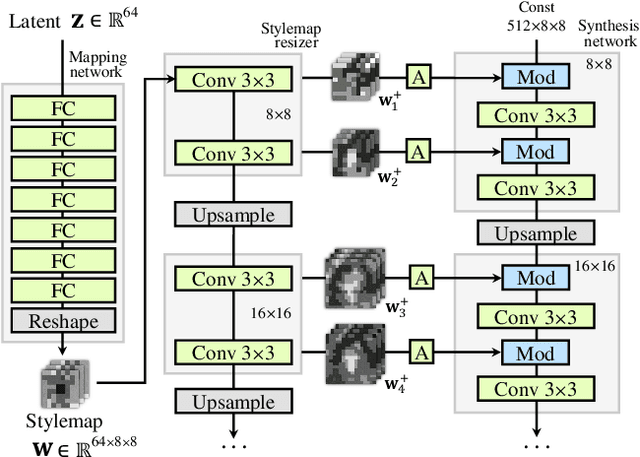
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. Although manipulating the latent vectors controls the synthesized outputs, editing real images with GANs suffers from i) time-consuming optimization for projecting real images to the latent vectors, ii) or inaccurate embedding through an encoder. We propose StyleMapGAN: the intermediate latent space has spatial dimensions, and a spatially variant modulation replaces AdaIN. It makes the embedding through an encoder more accurate than existing optimization-based methods while maintaining the properties of GANs. Experimental results demonstrate that our method significantly outperforms state-of-the-art models in various image manipulation tasks such as local editing and image interpolation. Last but not least, conventional editing methods on GANs are still valid on our StyleMapGAN. Source code is available at https://github.com/naver-ai/StyleMapGAN.
Deep Hedging, Generative Adversarial Networks, and Beyond
Mar 05, 2021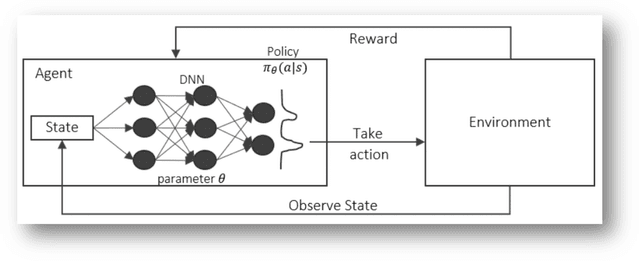
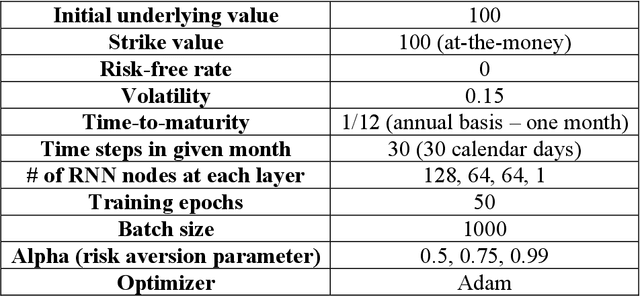

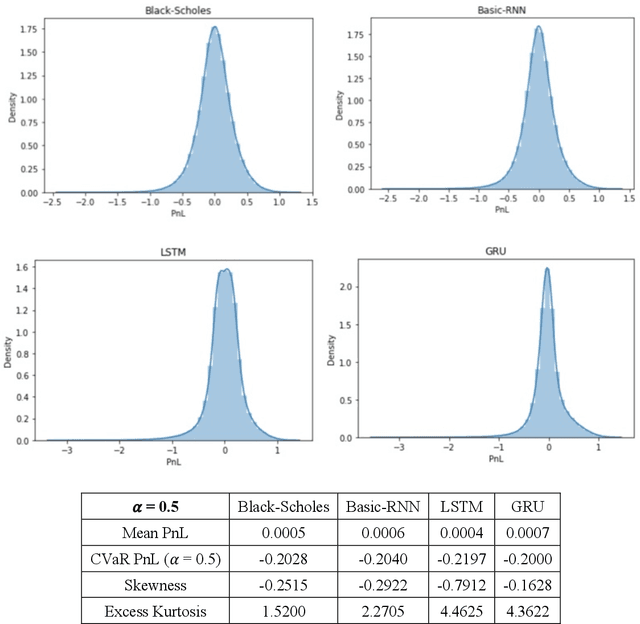
This paper introduces a potential application of deep learning and artificial intelligence in finance, particularly its application in hedging. The major goal encompasses two objectives. First, we present a framework of a direct policy search reinforcement agent replicating a simple vanilla European call option and use the agent for the model-free delta hedging. Through the first part of this paper, we demonstrate how the RNN-based direct policy search RL agents can perform delta hedging better than the classic Black-Scholes model in Q-world based on parametrically generated underlying scenarios, particularly minimizing tail exposures at higher values of the risk aversion parameter. In the second part of this paper, with the non-parametric paths generated by time-series GANs from multi-variate temporal space, we illustrate its delta hedging performance on various values of the risk aversion parameter via the basic RNN-based RL agent introduced in the first part of the paper, showing that we can potentially achieve higher average profits with a rather evident risk-return trade-off. We believe that this RL-based hedging framework is a more efficient way of performing hedging in practice, addressing some of the inherent issues with the classic models, providing promising/intuitive hedging results, and rendering a flexible framework that can be easily paired with other AI-based models for many other purposes.