 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECO: Egocentric Cognitive Mapping
Dec 02, 2018


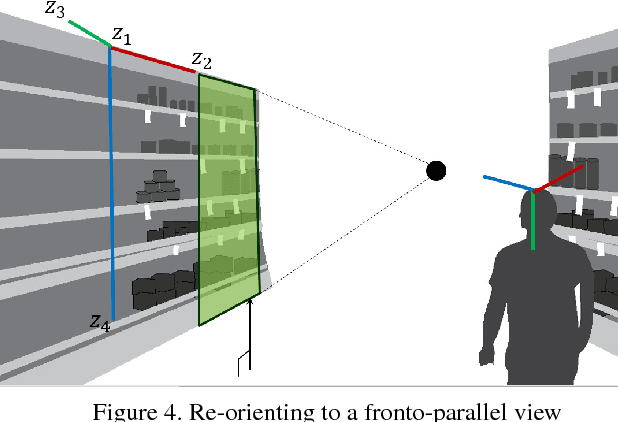
We present a new method to localize a camera within a previously unseen environment perceived from an egocentric point of view. Although this is, in general, an ill-posed problem, humans can effortlessly and efficiently determine their relative location and orientation and navigate into a previously unseen environments, e.g., finding a specific item in a new grocery store. To enable such a capability, we design a new egocentric representation, which we call ECO (Egocentric COgnitive map). ECO is biologically inspired, by the cognitive map that allows human navigation, and it encodes the surrounding visual semantics with respect to both distance and orientation. ECO possesses three main properties: (1) reconfigurability: complex semantics and geometry is captured via the synthesis of atomic visual representations (e.g., image patch); (2) robustness: the visual semantics are registered in a geometrically consistent way (e.g., aligning with respect to the gravity vector, frontalizing, and rescaling to canonical depth), thus enabling us to learn meaningful atomic representations; (3) adaptability: a domain adaptation framework is designed to generalize the learned representation without manual calibration. As a proof-of-concept, we use ECO to localize a camera within real-world scenes---various grocery stores---and demonstrate performance improvements when compared to existing semantic localization approaches.
HUMBI 1.0: HUman Multiview Behavioral Imaging Dataset
Dec 01, 2018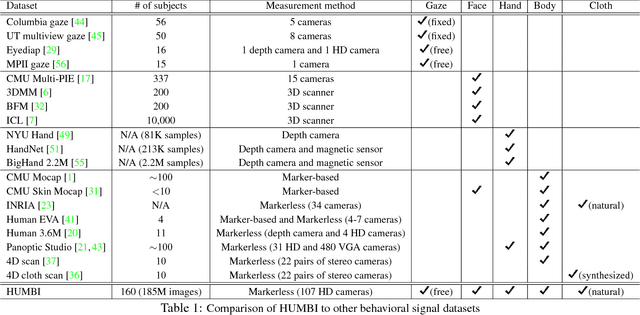



This paper presents a new dataset called HUMBI - a large corpus of high fidelity models of behavioral signals in 3D from a diverse population measured by a massive multi-camera system. With our novel design of a portable imaging system (consists of 107 HD cameras), we collect human behaviors from 164 subjects across gender, ethnicity, age, and physical condition at a public venue. Using the multiview image streams, we reconstruct high fidelity models of five elementary parts: gaze, face, hands, body, and cloth. As a byproduct, the 3D model provides geometrically consistent image annotation via 2D projection, e.g., body part segmentation. This dataset is a significant departure from the existing human datasets that suffers from subject diversity. We hope the HUMBI opens up a new opportunity for the development for behavioral imaging.
Multiview Supervision By Registration
Nov 27, 2018

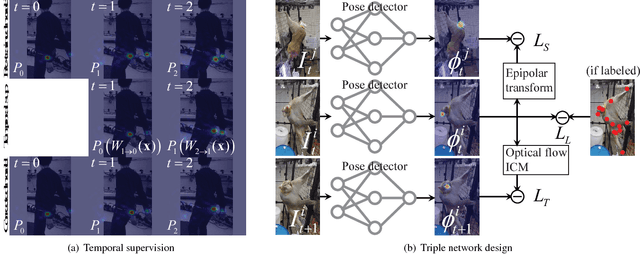

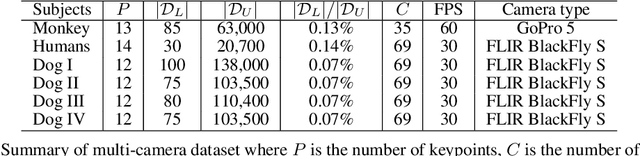
This paper presents a semi-supervised learning framework to train a keypoint pose detector using multiview image streams given the limited number of labeled data (typically <4%). We leverage the complementary relationship between multiview geometry and visual tracking to provide three types of supervisionary signals for the unlabeled data: (1) pose detection in one view can be used to supervise that of the other view as they must satisfy the epipolar constraint; (2) pose detection must be temporally coherent in accordance with its optical flow; (3) the occluded keypoint from one view must be consistently invisible from the near views. We formulate the theory of multiview supervision by registration and design a new end-to-end neural network that integrates these supervisionary signals in a differentiable fashion to incorporate the large unlabeled data in pose detector training. The key innovation of the network is the ability to reason about the visibility/occlusion, which is indicative of the degenerate case of detection and tracking. Our resulting pose detector shows considerable outperformance comparing the state-of-the-art pose detectors in terms of accuracy (keypoint detection) and precision (3D reconstruction). We validate our approach with challenging realworld data including the pose detection of non-human species such as monkeys and dogs.
MONET: Multiview Semi-supervised Keypoint via Epipolar Divergence
May 31, 2018
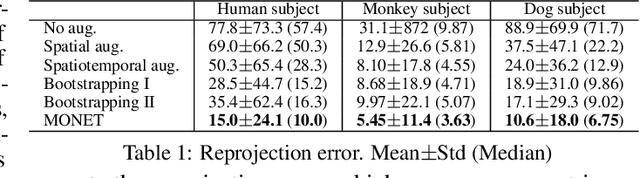
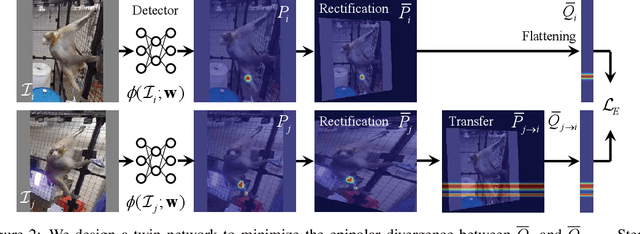
This paper presents MONET---an end-to-end semi-supervised learning framework for a pose detector using multiview image streams. What differentiates MONET from existing models is its capability of detecting general subjects including non-human species without a pre-trained model. A key challenge of such subjects lies in the limited availability of expert manual annotations, which often leads to a large bias in the detection model. We address this challenge by using the epipolar constraint embedded in the unlabeled data in two ways. First, given a set of the labeled data, the keypoint trajectories can be reliably reconstructed in 3D using multiview optical flows, resulting in considerable data augmentation in space and time from nearly exhaustive views. Second, the detection across views must geometrically agree with each other. We introduce a new measure of geometric consistency in keypoint distributions called epipolar divergence---a generalized distance from the epipolar lines to the corresponding keypoint distribution. Epipolar divergence characterizes when two view keypoint distributions produces zero reprojection error. We design a twin network that minimizes the epipolar divergence through stereo rectification that can significantly alleviate computational complexity and sampling aliasing in training. We demonstrate that our framework can localize customized keypoints of diverse species, e.g., humans, dogs, and monkeys.
3D Semantic Trajectory Reconstruction from 3D Pixel Continuum
Dec 04, 2017
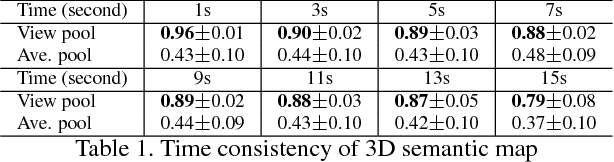

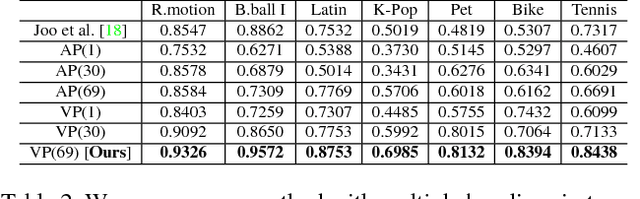
This paper presents a method to reconstruct dense semantic trajectory stream of human interactions in 3D from synchronized multiple videos. The interactions inherently introduce self-occlusion and illumination/appearance/shape changes, resulting in highly fragmented trajectory reconstruction with noisy and coarse semantic labels. Our conjecture is that among many views, there exists a set of views that can confidently recognize the visual semantic label of a 3D trajectory. We introduce a new representation called 3D semantic map---a probability distribution over the semantic labels per trajectory. We construct the 3D semantic map by reasoning about visibility and 2D recognition confidence based on view-pooling, i.e., finding the view that best represents the semantics of the trajectory. Using the 3D semantic map, we precisely infer all trajectory labels jointly by considering the affinity between long range trajectories via estimating their local rigid transformations. This inference quantitatively outperforms the baseline approaches in terms of predictive validity, representation robustness, and affinity effectiveness. We demonstrate that our algorithm can robustly compute the semantic labels of a large scale trajectory set involving real-world human interactions with object, scenes, and people.
Am I a Baller? Basketball Performance Assessment from First-Person Videos
Aug 02, 2017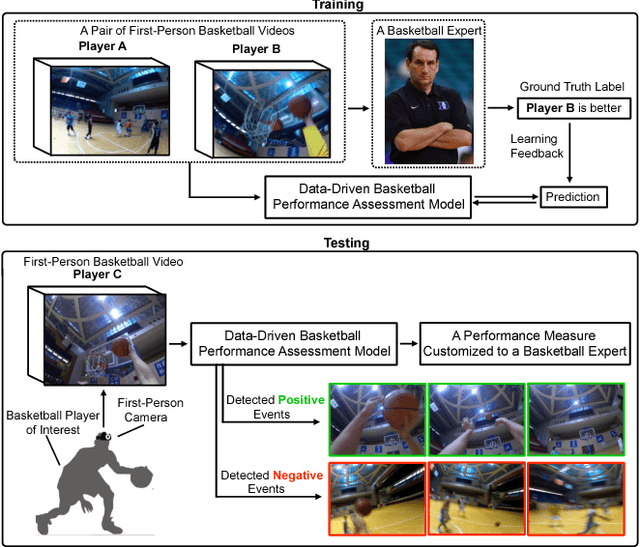
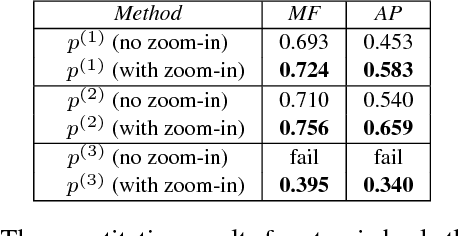

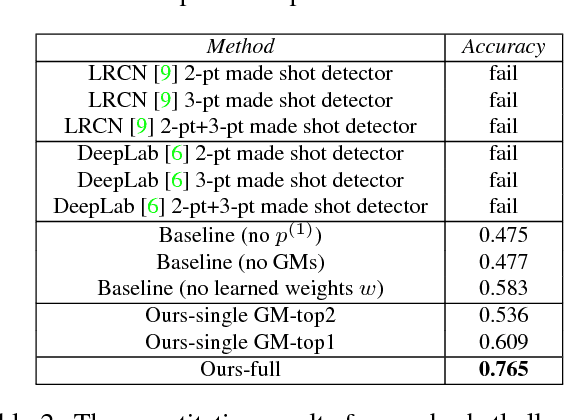
This paper presents a method to assess a basketball player's performance from his/her first-person video. A key challenge lies in the fact that the evaluation metric is highly subjective and specific to a particular evaluator. We leverage the first-person camera to address this challenge. The spatiotemporal visual semantics provided by a first-person view allows us to reason about the camera wearer's actions while he/she is participating in an unscripted basketball game. Our method takes a player's first-person video and provides a player's performance measure that is specific to an evaluator's preference. To achieve this goal, we first use a convolutional LSTM network to detect atomic basketball events from first-person videos. Our network's ability to zoom-in to the salient regions addresses the issue of a severe camera wearer's head movement in first-person videos. The detected atomic events are then passed through the Gaussian mixtures to construct a highly non-linear visual spatiotemporal basketball assessment feature. Finally, we use this feature to learn a basketball assessment model from pairs of labeled first-person basketball videos, for which a basketball expert indicates, which of the two players is better. We demonstrate that despite not knowing the basketball evaluator's criterion, our model learns to accurately assess the players in real-world games. Furthermore, our model can also discover basketball events that contribute positively and negatively to a player's performance.
Unsupervised Learning of Important Objects from First-Person Videos
Aug 02, 2017
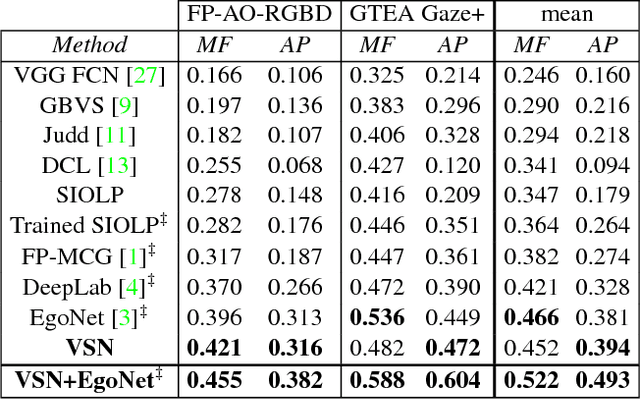
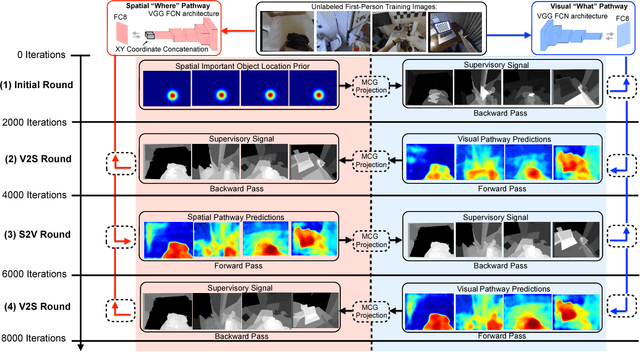

A first-person camera, placed at a person's head, captures, which objects are important to the camera wearer. Most prior methods for this task learn to detect such important objects from the manually labeled first-person data in a supervised fashion. However, important objects are strongly related to the camera wearer's internal state such as his intentions and attention, and thus, only the person wearing the camera can provide the importance labels. Such a constraint makes the annotation process costly and limited in scalability. In this work, we show that we can detect important objects in first-person images without the supervision by the camera wearer or even third-person labelers. We formulate an important detection problem as an interplay between the 1) segmentation and 2) recognition agents. The segmentation agent first proposes a possible important object segmentation mask for each image, and then feeds it to the recognition agent, which learns to predict an important object mask using visual semantics and spatial features. We implement such an interplay between both agents via an alternating cross-pathway supervision scheme inside our proposed Visual-Spatial Network (VSN). Our VSN consists of spatial ("where") and visual ("what") pathways, one of which learns common visual semantics while the other focuses on the spatial location cues. Our unsupervised learning is accomplished via a cross-pathway supervision, where one pathway feeds its predictions to a segmentation agent, which proposes a candidate important object segmentation mask that is then used by the other pathway as a supervisory signal. We show our method's success on two different important object datasets, where our method achieves similar or better results as the supervised methods.
First Person Action-Object Detection with EgoNet
Jun 10, 2017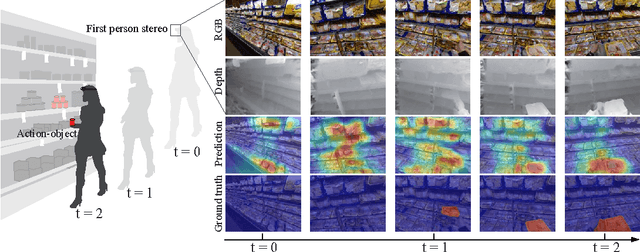
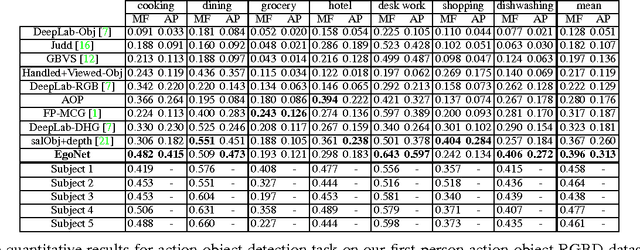
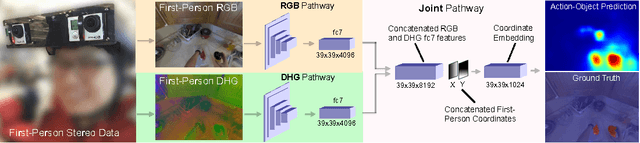
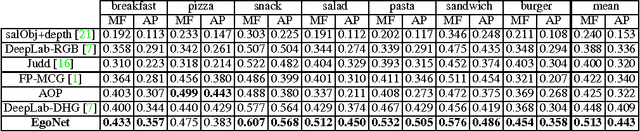
Unlike traditional third-person cameras mounted on robots, a first-person camera, captures a person's visual sensorimotor object interactions from up close. In this paper, we study the tight interplay between our momentary visual attention and motor action with objects from a first-person camera. We propose a concept of action-objects---the objects that capture person's conscious visual (watching a TV) or tactile (taking a cup) interactions. Action-objects may be task-dependent but since many tasks share common person-object spatial configurations, action-objects exhibit a characteristic 3D spatial distance and orientation with respect to the person. We design a predictive model that detects action-objects using EgoNet, a joint two-stream network that holistically integrates visual appearance (RGB) and 3D spatial layout (depth and height) cues to predict per-pixel likelihood of action-objects. Our network also incorporates a first-person coordinate embedding, which is designed to learn a spatial distribution of the action-objects in the first-person data. We demonstrate EgoNet's predictive power, by showing that it consistently outperforms previous baseline approaches. Furthermore, EgoNet also exhibits a strong generalization ability, i.e., it predicts semantically meaningful objects in novel first-person datasets. Our method's ability to effectively detect action-objects could be used to improve robots' understanding of human-object interactions.
Customizing First Person Image Through Desired Actions
Apr 01, 2017

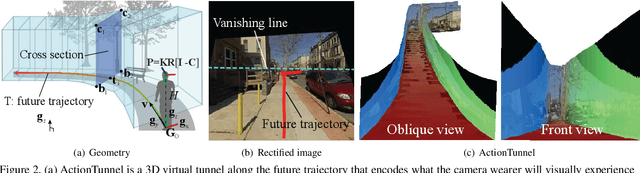
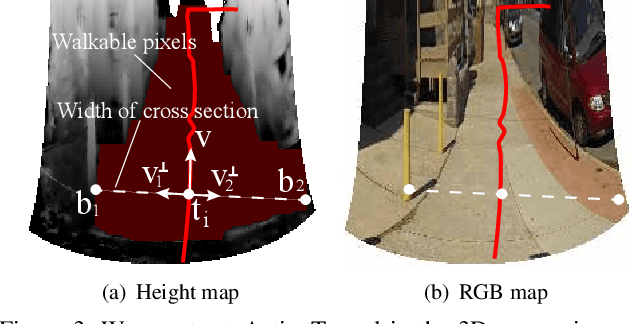
This paper studies a problem of inverse visual path planning: creating a visual scene from a first person action. Our conjecture is that the spatial arrangement of a first person visual scene is deployed to afford an action, and therefore, the action can be inversely used to synthesize a new scene such that the action is feasible. As a proof-of-concept, we focus on linking visual experiences induced by walking. A key innovation of this paper is a concept of ActionTunnel---a 3D virtual tunnel along the future trajectory encoding what the wearer will visually experience as moving into the scene. This connects two distinctive first person images through similar walking paths. Our method takes a first person image with a user defined future trajectory and outputs a new image that can afford the future motion. The image is created by combining present and future ActionTunnels in 3D where the missing pixels in adjoining area are computed by a generative adversarial network. Our work can provide a travel across different first person experiences in diverse real world scenes.
Social Behavior Prediction from First Person Videos
Nov 29, 2016


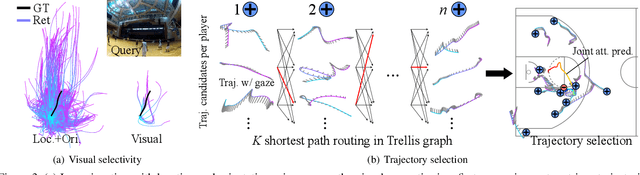
This paper presents a method to predict the future movements (location and gaze direction) of basketball players as a whole from their first person videos. The predicted behaviors reflect an individual physical space that affords to take the next actions while conforming to social behaviors by engaging to joint attention. Our key innovation is to use the 3D reconstruction of multiple first person cameras to automatically annotate each other's the visual semantics of social configurations. We leverage two learning signals uniquely embedded in first person videos. Individually, a first person video records the visual semantics of a spatial and social layout around a person that allows associating with past similar situations. Collectively, first person videos follow joint attention that can link the individuals to a group. We learn the egocentric visual semantics of group movements using a Siamese neural network to retrieve future trajectories. We consolidate the retrieved trajectories from all players by maximizing a measure of social compatibility---the gaze alignment towards joint attention predicted by their social formation, where the dynamics of joint attention is learned by a long-term recurrent convolutional network. This allows us to characterize which social configuration is more plausible and predict future group trajectories.