 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Secondary Landmark Detection via 3D Representation Learning
Oct 01, 2021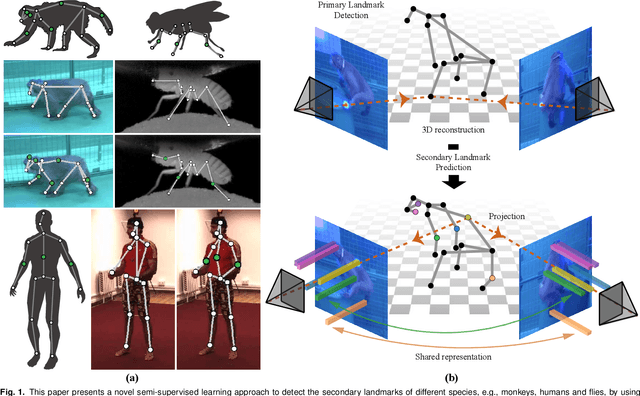
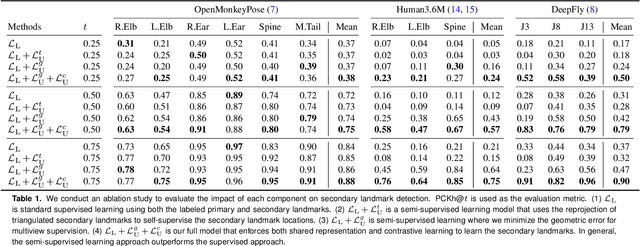

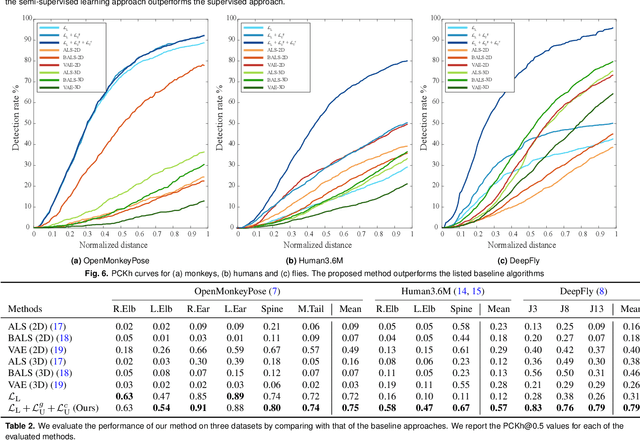
Recent technological developments have spurred great advances in the computerized tracking of joints and other landmarks in moving animals, including humans. Such tracking promises important advances in biology and biomedicine. Modern tracking models depend critically on labor-intensive annotated datasets of primary landmarks by non-expert humans. However, such annotation approaches can be costly and impractical for secondary landmarks, that is, ones that reflect fine-grained geometry of animals, and that are often specific to customized behavioral tasks. Due to visual and geometric ambiguity, nonexperts are often not qualified for secondary landmark annotation, which can require anatomical and zoological knowledge. These barriers significantly impede downstream behavioral studies because the learned tracking models exhibit limited generalizability. We hypothesize that there exists a shared representation between the primary and secondary landmarks because the range of motion of the secondary landmarks can be approximately spanned by that of the primary landmarks. We present a method to learn this spatial relationship of the primary and secondary landmarks in three dimensional space, which can, in turn, self-supervise the secondary landmark detector. This 3D representation learning is generic, and can therefore be applied to various multiview settings across diverse organisms, including macaques, flies, and humans.
HUMBI: A Large Multiview Dataset of Human Body Expressions and Benchmark Challenge
Sep 30, 2021
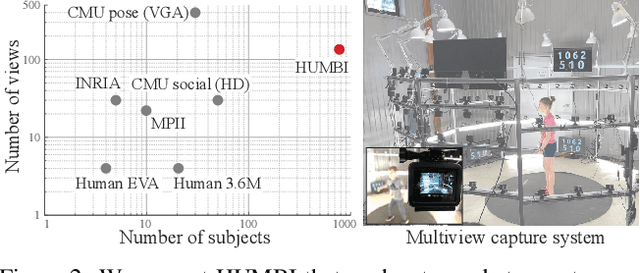
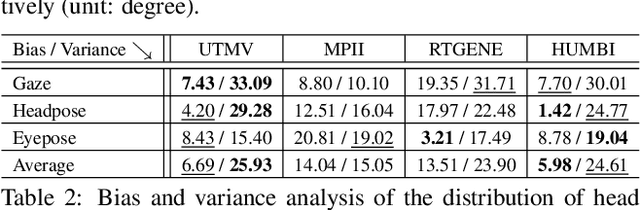
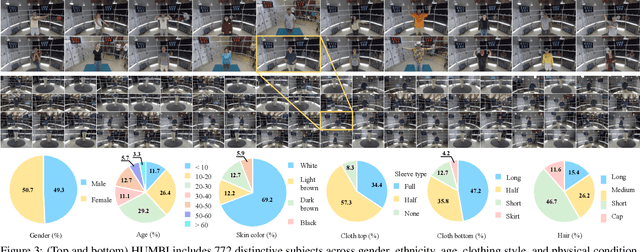
This paper presents a new large multiview dataset called HUMBI for human body expressions with natural clothing. The goal of HUMBI is to facilitate modeling view-specific appearance and geometry of five primary body signals including gaze, face, hand, body, and garment from assorted people. 107 synchronized HD cameras are used to capture 772 distinctive subjects across gender, ethnicity, age, and style. With the multiview image streams, we reconstruct high fidelity body expressions using 3D mesh models, which allows representing view-specific appearance. We demonstrate that HUMBI is highly effective in learning and reconstructing a complete human model and is complementary to the existing datasets of human body expressions with limited views and subjects such as MPII-Gaze, Multi-PIE, Human3.6M, and Panoptic Studio datasets. Based on HUMBI, we formulate a new benchmark challenge of a pose-guided appearance rendering task that aims to substantially extend photorealism in modeling diverse human expressions in 3D, which is the key enabling factor of authentic social tele-presence. HUMBI is publicly available at http://humbi-data.net
Semi-supervised Dense Keypointsusing Unlabeled Multiview Images
Sep 20, 2021
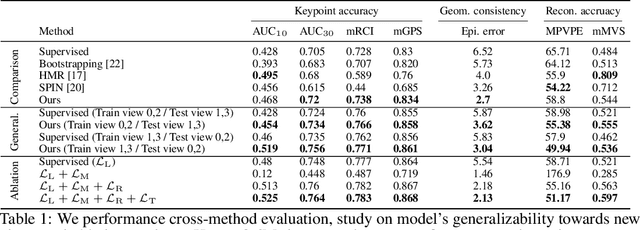


This paper presents a new end-to-end semi-supervised framework to learn a dense keypoint detector using unlabeled multiview images. A key challenge lies in finding the exact correspondences between the dense keypoints in multiple views since the inverse of keypoint mapping can be neither analytically derived nor differentiated. This limits applying existing multiview supervision approaches on sparse keypoint detection that rely on the exact correspondences. To address this challenge, we derive a new probabilistic epipolar constraint that encodes the two desired properties. (1) Soft correspondence: we define a matchability, which measures a likelihood of a point matching to the other image's corresponding point, thus relaxing the exact correspondences' requirement. (2) Geometric consistency: every point in the continuous correspondence fields must satisfy the multiview consistency collectively. We formulate a probabilistic epipolar constraint using a weighted average of epipolar errors through the matchability thereby generalizing the point-to-point geometric error to the field-to-field geometric error. This generalization facilitates learning a geometrically coherent dense keypoint detection model by utilizing a large number of unlabeled multiview images. Additionally, to prevent degenerative cases, we employ a distillation-based regularization by using a pretrained model. Finally, we design a new neural network architecture, made of twin networks, that effectively minimizes the probabilistic epipolar errors of all possible correspondences between two view images by building affinity matrices. Our method shows superior performance compared to existing methods, including non-differentiable bootstrapping in terms of keypoint accuracy, multiview consistency, and 3D reconstruction accuracy.
Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
Mar 04, 2021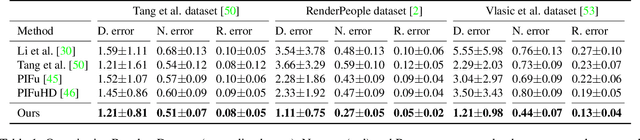
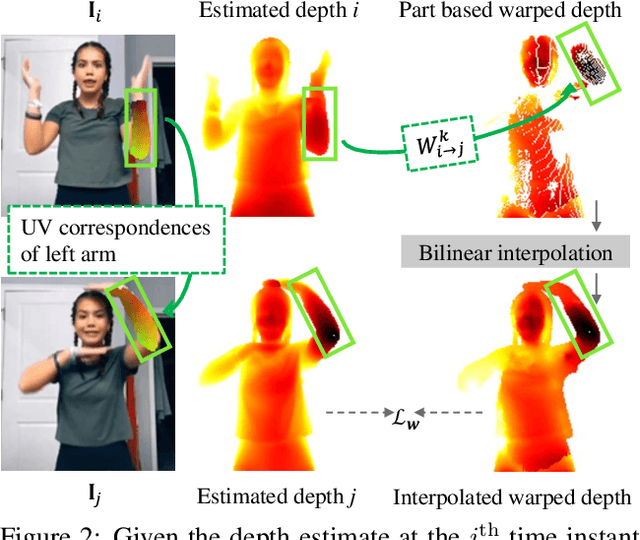
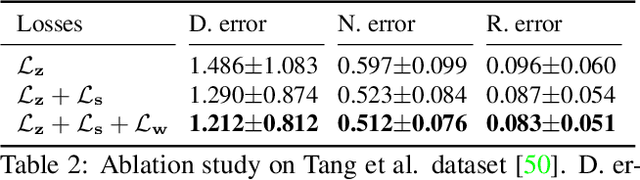

A key challenge of learning the geometry of dressed humans lies in the limited availability of the ground truth data (e.g., 3D scanned models), which results in the performance degradation of 3D human reconstruction when applying to real-world imagery. We address this challenge by leveraging a new data resource: a number of social media dance videos that span diverse appearance, clothing styles, performances, and identities. Each video depicts dynamic movements of the body and clothes of a single person while lacking the 3D ground truth geometry. To utilize these videos, we present a new method to use the local transformation that warps the predicted local geometry of the person from an image to that of another image at a different time instant. This allows self-supervision as enforcing a temporal coherence over the predictions. In addition, we jointly learn the depth along with the surface normals that are highly responsive to local texture, wrinkle, and shade by maximizing their geometric consistency. Our method is end-to-end trainable, resulting in high fidelity depth estimation that predicts fine geometry faithful to the input real image. We demonstrate that our method outperforms the state-of-the-art human depth estimation and human shape recovery approaches on both real and rendered images.
Neural 3D Clothes Retargeting from a Single Image
Jan 29, 2021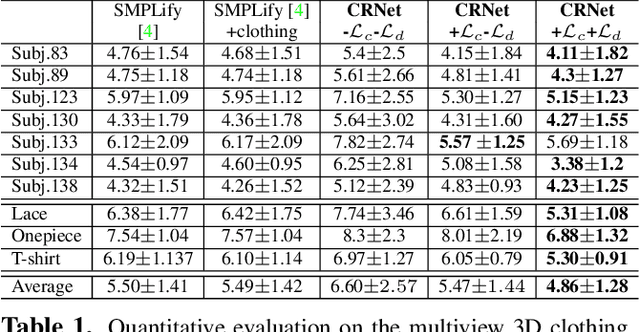

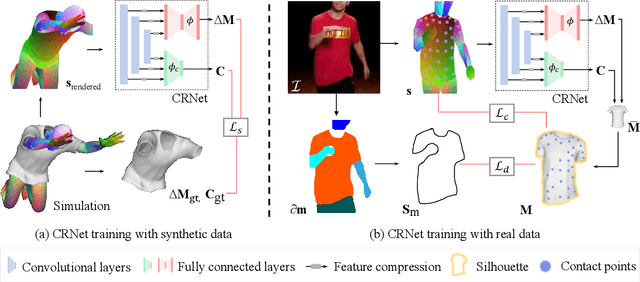
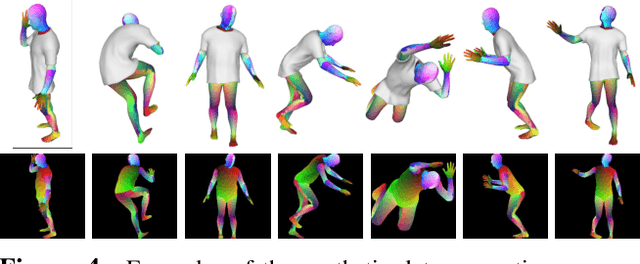
In this paper, we present a method of clothes retargeting; generating the potential poses and deformations of a given 3D clothing template model to fit onto a person in a single RGB image. The problem is fundamentally ill-posed as attaining the ground truth data is impossible, i.e., images of people wearing the different 3D clothing template model at exact same pose. We address this challenge by utilizing large-scale synthetic data generated from physical simulation, allowing us to map 2D dense body pose to 3D clothing deformation. With the simulated data, we propose a semi-supervised learning framework that validates the physical plausibility of the 3D deformation by matching with the prescribed body-to-cloth contact points and clothing silhouette to fit onto the unlabeled real images. A new neural clothes retargeting network (CRNet) is designed to integrate the semi-supervised retargeting task in an end-to-end fashion. In our evaluation, we show that our method can predict the realistic 3D pose and deformation field needed for retargeting clothes models in real-world examples.
Pose-Guided Human Animation from a Single Image in the Wild
Dec 07, 2020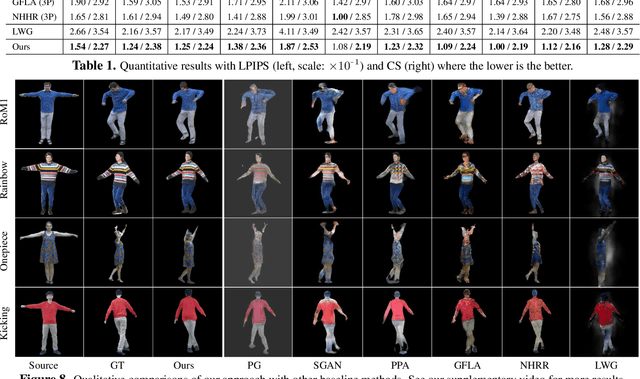
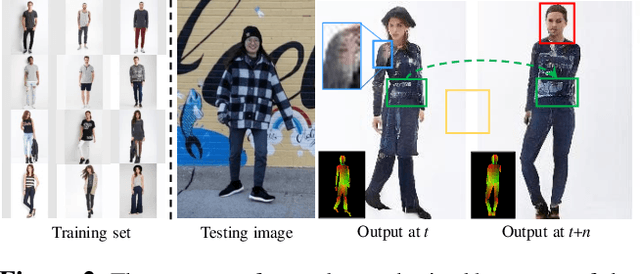
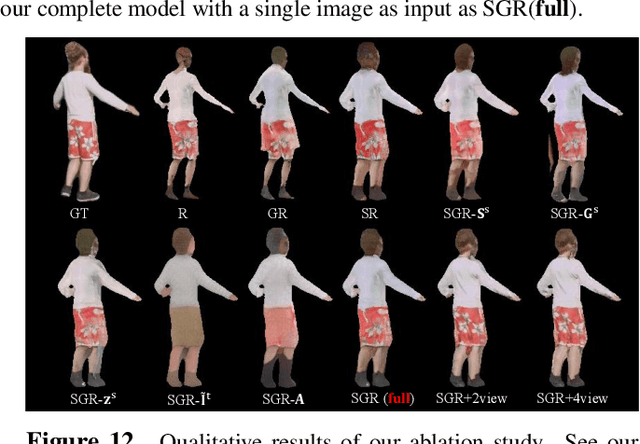
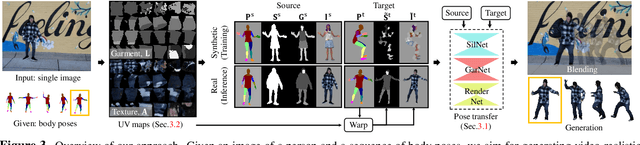
We present a new pose transfer method for synthesizing a human animation from a single image of a person controlled by a sequence of body poses. Existing pose transfer methods exhibit significant visual artifacts when applying to a novel scene, resulting in temporal inconsistency and failures in preserving the identity and textures of the person. To address these limitations, we design a compositional neural network that predicts the silhouette, garment labels, and textures. Each modular network is explicitly dedicated to a subtask that can be learned from the synthetic data. At the inference time, we utilize the trained network to produce a unified representation of appearance and its labels in UV coordinates, which remains constant across poses. The unified representation provides an incomplete yet strong guidance to generating the appearance in response to the pose change. We use the trained network to complete the appearance and render it with the background. With these strategies, we are able to synthesize human animations that can preserve the identity and appearance of the person in a temporally coherent way without any fine-tuning of the network on the testing scene. Experiments show that our method outperforms the state-of-the-arts in terms of synthesis quality, temporal coherence, and generalization ability.
Surface Normal Estimation of Tilted Images via Spatial Rectifier
Jul 17, 2020
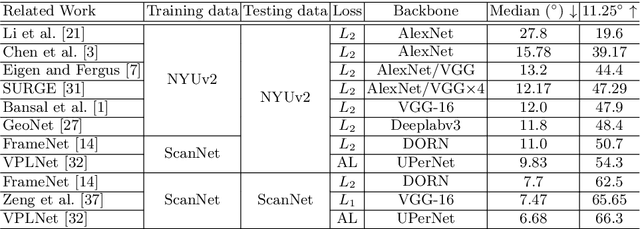
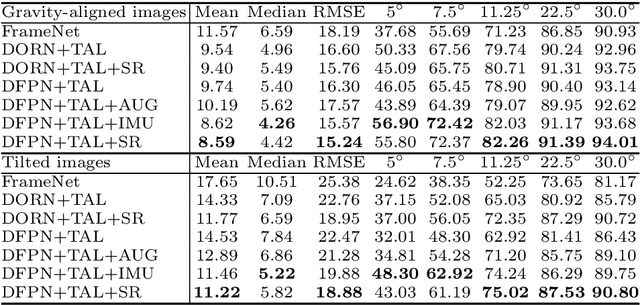
In this paper, we present a spatial rectifier to estimate surface normals of tilted images. Tilted images are of particular interest as more visual data are captured by arbitrarily oriented sensors such as body-/robot-mounted cameras. Existing approaches exhibit bounded performance on predicting surface normals because they were trained using gravity-aligned images. Our two main hypotheses are: (1) visual scene layout is indicative of the gravity direction; and (2) not all surfaces are equally represented by a learned estimator due to the structured distribution of the training data, thus, there exists a transformation for each tilted image that is more responsive to the learned estimator than others. We design a spatial rectifier that is learned to transform the surface normal distribution of a tilted image to the rectified one that matches the gravity-aligned training data distribution. Along with the spatial rectifier, we propose a novel truncated angular loss that offers a stronger gradient at smaller angular errors and robustness to outliers. The resulting estimator outperforms the state-of-the-art methods including data augmentation baselines not only on ScanNet and NYUv2 but also on a new dataset called Tilt-RGBD that includes considerable roll and pitch camera motion.
Novel View Synthesis of Dynamic Scenes with Globally Coherent Depths from a Monocular Camera
Apr 02, 2020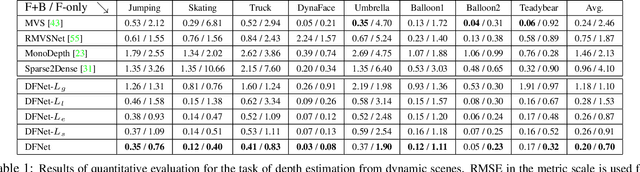
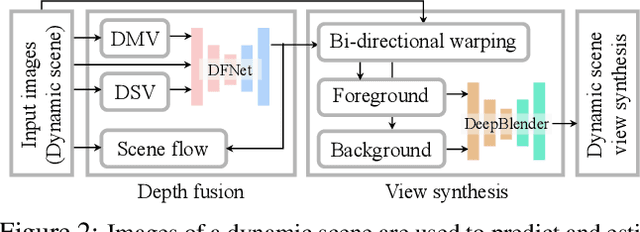
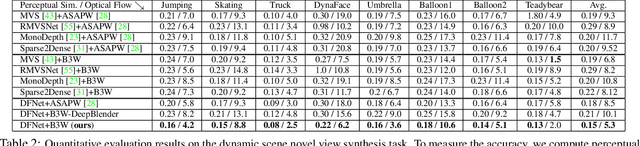
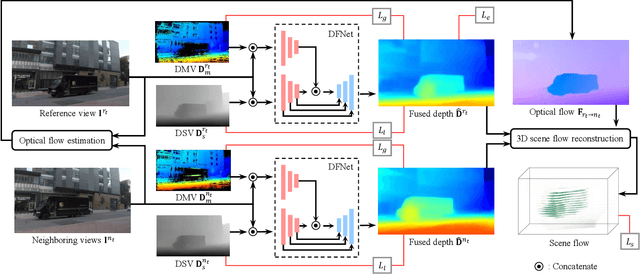
This paper presents a new method to synthesize an image from arbitrary views and times given a collection of images of a dynamic scene. A key challenge for the novel view synthesis arises from dynamic scene reconstruction where epipolar geometry does not apply to the local motion of dynamic contents. To address this challenge, we propose to combine the depth from single view (DSV) and the depth from multi-view stereo (DMV), where DSV is complete, i.e., a depth is assigned to every pixel, yet view-variant in its scale, while DMV is view-invariant yet incomplete. Our insight is that although its scale and quality are inconsistent with other views, the depth estimation from a single view can be used to reason about the globally coherent geometry of dynamic contents. We cast this problem as learning to correct the scale of DSV, and to refine each depth with locally consistent motions between views to form a coherent depth estimation. We integrate these tasks into a depth fusion network in a self-supervised fashion. Given the fused depth maps, we synthesize a photorealistic virtual view in a specific location and time with our deep blending network that completes the scene and renders the virtual view. We evaluate our method of depth estimation and view synthesis on diverse real-world dynamic scenes and show the outstanding performance over existing methods.
Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking
Jul 25, 2019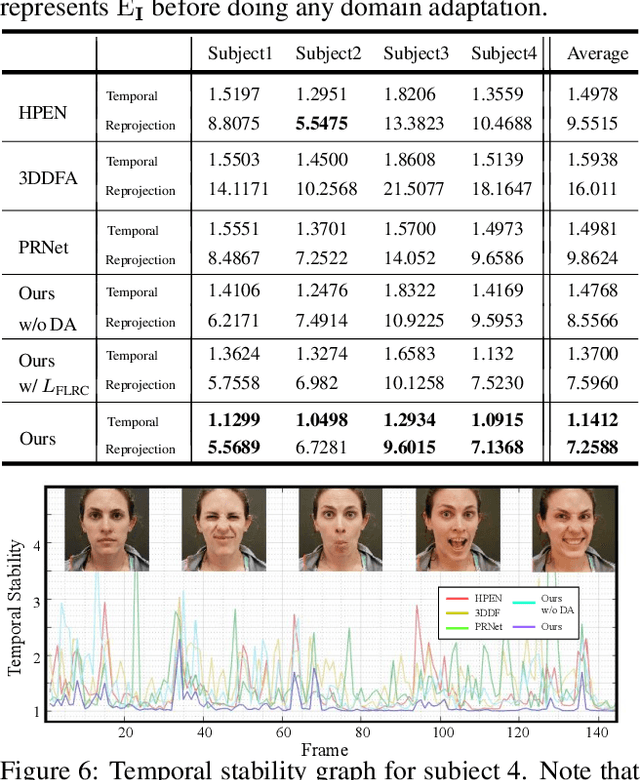
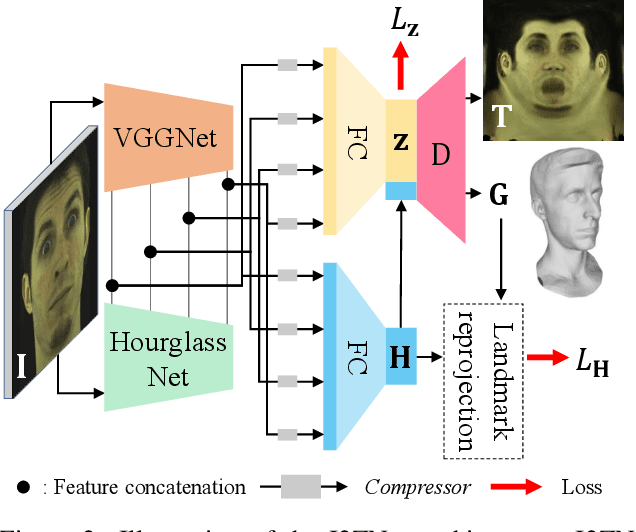
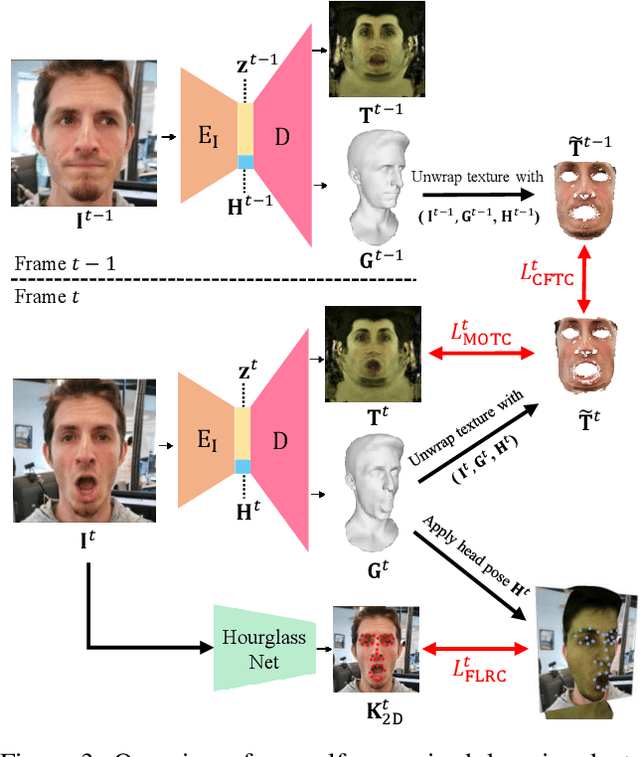
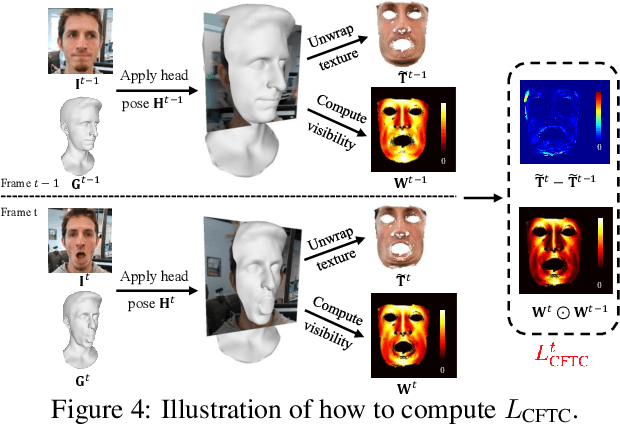
Improvements in data-capture and face modeling techniques have enabled us to create high-fidelity realistic face models. However, driving these realistic face models requires special input data, e.g. 3D meshes and unwrapped textures. Also, these face models expect clean input data taken under controlled lab environments, which is very different from data collected in the wild. All these constraints make it challenging to use the high-fidelity models in tracking for commodity cameras. In this paper, we propose a self-supervised domain adaptation approach to enable the animation of high-fidelity face models from a commodity camera. Our approach first circumvents the requirement for special input data by training a new network that can directly drive a face model just from a single 2D image. Then, we overcome the domain mismatch between lab and uncontrolled environments by performing self-supervised domain adaptation based on "consecutive frame texture consistency" based on the assumption that the appearance of the face is consistent over consecutive frames, avoiding the necessity of modeling the new environment such as lighting or background. Experiments show that we are able to drive a high-fidelity face model to perform complex facial motion from a cellphone camera without requiring any labeled data from the new domain.
Multiview Cross-supervision for Semantic Segmentation
Dec 04, 2018

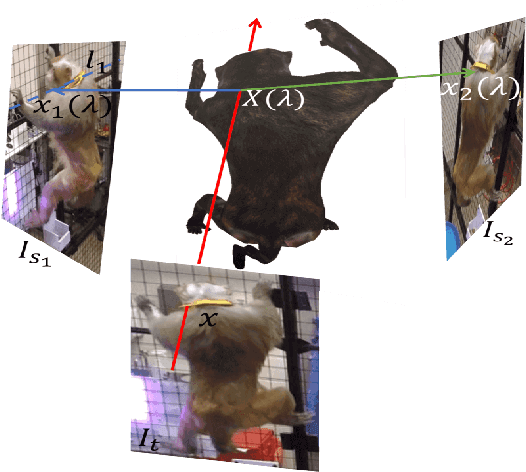
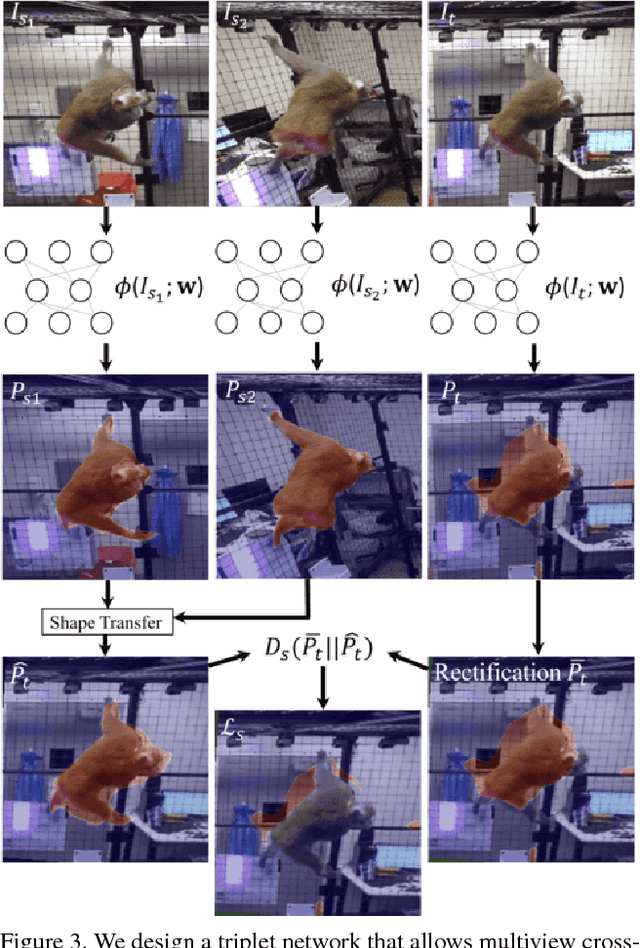
This paper presents a semi-supervised learning framework for a customized semantic segmentation task using multiview image streams. A key challenge of the customized task lies in the limited accessibility of the labeled data due to the requirement of prohibitive manual annotation effort. We hypothesize that it is possible to leverage multiview image streams that are linked through the underlying 3D geometry, which can provide an additional supervisionary signal to train a segmentation model. We formulate a new cross-supervision method using a shape belief transfer---the segmentation belief in one image is used to predict that of the other image through epipolar geometry analogous to shape-from-silhouette. The shape belief transfer provides the upper and lower bounds of the segmentation for the unlabeled data where its gap approaches asymptotically to zero as the number of the labeled views increases. We integrate this theory to design a novel network that is agnostic to camera calibration, network model, and semantic category and bypasses the intermediate process of suboptimal 3D reconstruction. We validate this network by recognizing a customized semantic category per pixel from realworld visual data including non-human species and a subject of interest in social videos where attaining large-scale annotation data is infeasible.