 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAPI: Hardware-Aware Progressive Inference
Aug 10, 2020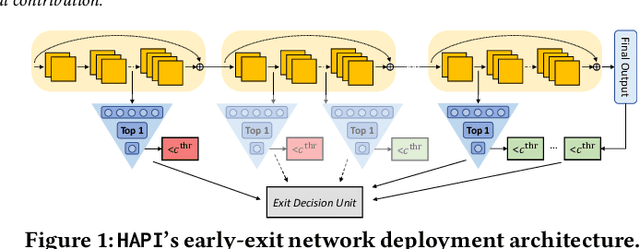

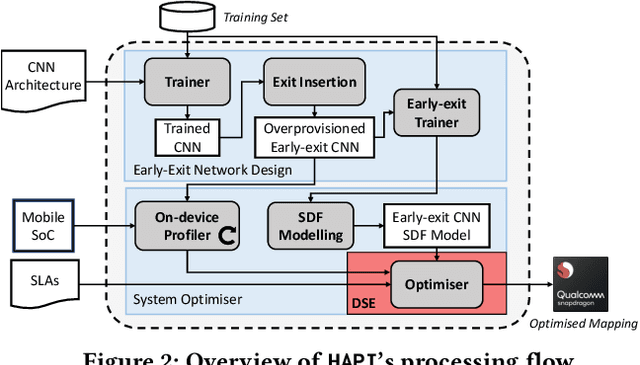
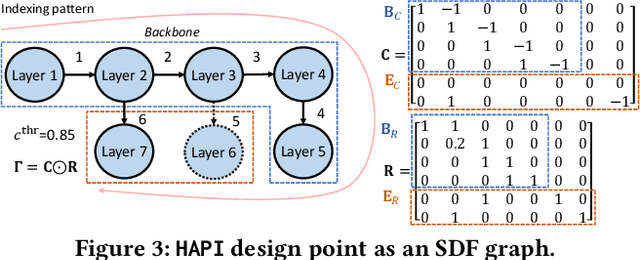
Convolutional neural networks (CNNs) have recently become the state-of-the-art in a diversity of AI tasks. Despite their popularity, CNN inference still comes at a high computational cost. A growing body of work aims to alleviate this by exploiting the difference in the classification difficulty among samples and early-exiting at different stages of the network. Nevertheless, existing studies on early exiting have primarily focused on the training scheme, without considering the use-case requirements or the deployment platform. This work presents HAPI, a novel methodology for generating high-performance early-exit networks by co-optimising the placement of intermediate exits together with the early-exit strategy at inference time. Furthermore, we propose an efficient design space exploration algorithm which enables the faster traversal of a large number of alternative architectures and generates the highest-performing design, tailored to the use-case requirements and target hardware. Quantitative evaluation shows that our system consistently outperforms alternative search mechanisms and state-of-the-art early-exit schemes across various latency budgets. Moreover, it pushes further the performance of highly optimised hand-crafted early-exit CNNs, delivering up to 5.11x speedup over lightweight models on imposed latency-driven SLAs for embedded devices.
Journey Towards Tiny Perceptual Super-Resolution
Jul 08, 2020

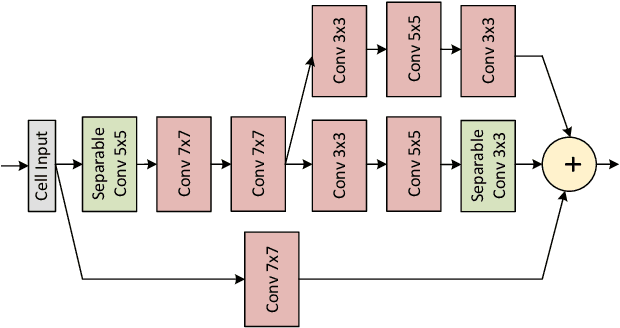
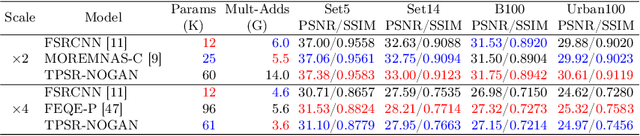
Recent works in single-image perceptual super-resolution (SR) have demonstrated unprecedented performance in generating realistic textures by means of deep convolutional networks. However, these convolutional models are excessively large and expensive, hindering their effective deployment to end devices. In this work, we propose a neural architecture search (NAS) approach that integrates NAS and generative adversarial networks (GANs) with recent advances in perceptual SR and pushes the efficiency of small perceptual SR models to facilitate on-device execution. Specifically, we search over the architectures of both the generator and the discriminator sequentially, highlighting the unique challenges and key observations of searching for an SR-optimized discriminator and comparing them with existing discriminator architectures in the literature. Our tiny perceptual SR (TPSR) models outperform SRGAN and EnhanceNet on both full-reference perceptual metric (LPIPS) and distortion metric (PSNR) while being up to 26.4$\times$ more memory efficient and 33.6$\times$ more compute efficient respectively.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
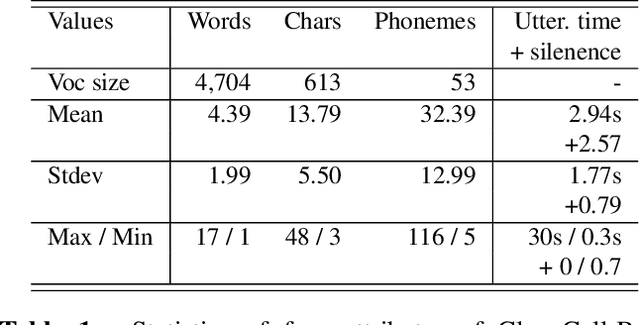
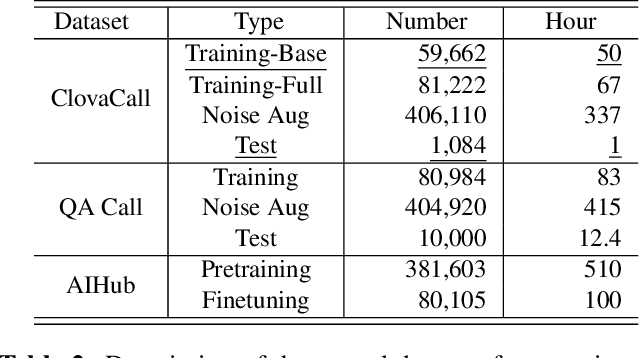
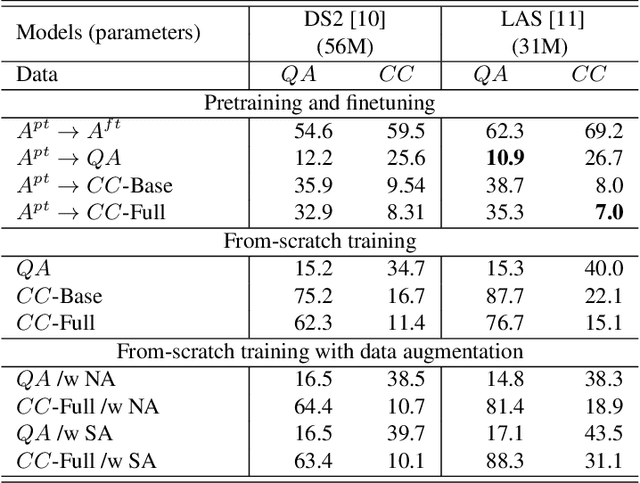
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
Stealth UAV through Coanda Effect
Apr 29, 2020

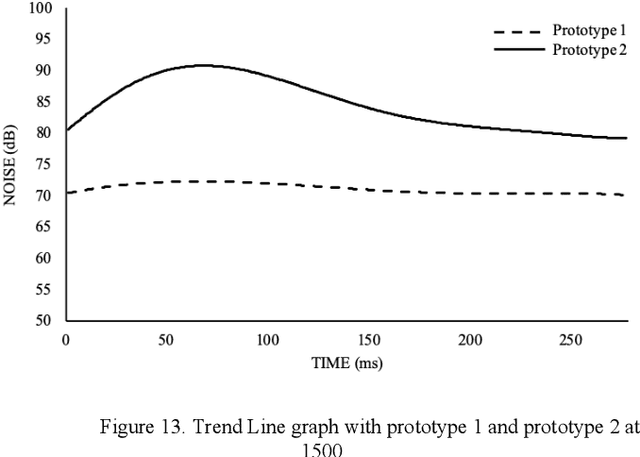
This paper uses Coanda Effect to reduce motors, the source of noise, and finds low noise materials with sufficient lift force so that it can achieve acoustical stealth UAVs.According to NASA research [1], the noise of UAVs is better heard to people. But there must be some moments when we need to operate the drones quietly, so how can we reduce the noise? In previous research, there have also been steady attempts to produce UAVs using Coanda Effect, but have never tried to achieve Acoustic Stealth through Coanda UAVs. But Coanda Effect uses only one motor and is structurally quiet. So we tried to find quiet methods (materials, structures) while at the same time having sufficient stimulus through the Coanda Effect. Verification went through experiments. The control group used the most common type of Quadrone, and determine if the hypothesis is correct by testing various structures and materials under the same conditions, and measuring noise. UAVs using Coanda Effect are not of any shape or structure that is not changeable, and internal space is also empty. That's why the Coanda Effect UAV we present can be improved through follow-up research. That's why the Coanda Effect UAV could open up a new frontier for the Stealth UAVs.
Best of Both Worlds: AutoML Codesign of a CNN and its Hardware Accelerator
Mar 06, 2020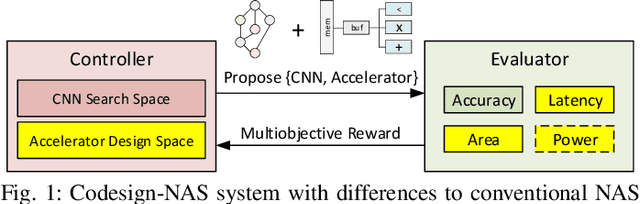
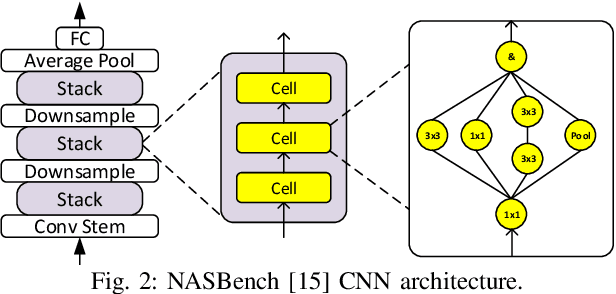
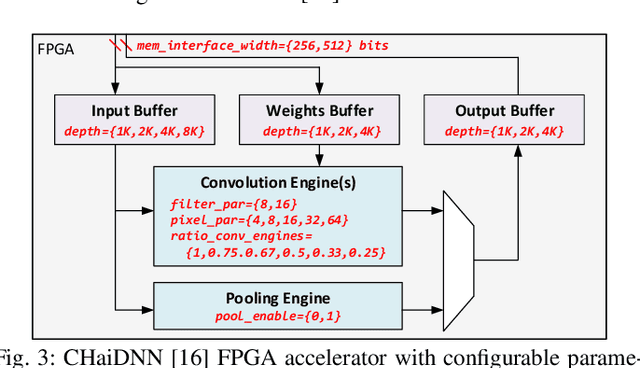
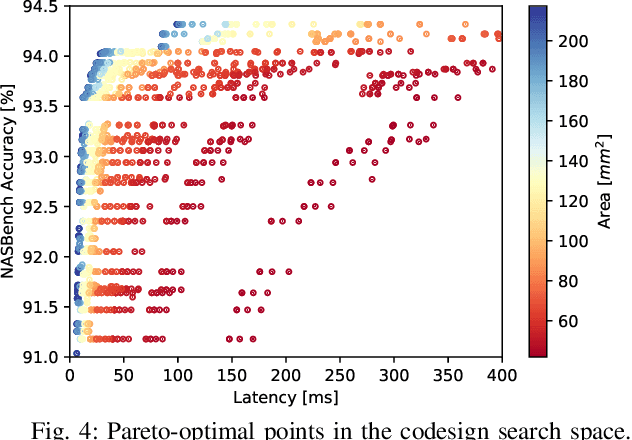
Neural architecture search (NAS) has been very successful at outperforming human-designed convolutional neural networks (CNN) in accuracy, and when hardware information is present, latency as well. However, NAS-designed CNNs typically have a complicated topology, therefore, it may be difficult to design a custom hardware (HW) accelerator for such CNNs. We automate HW-CNN codesign using NAS by including parameters from both the CNN model and the HW accelerator, and we jointly search for the best model-accelerator pair that boosts accuracy and efficiency. We call this Codesign-NAS. In this paper we focus on defining the Codesign-NAS multiobjective optimization problem, demonstrating its effectiveness, and exploring different ways of navigating the codesign search space. For CIFAR-10 image classification, we enumerate close to 4 billion model-accelerator pairs, and find the Pareto frontier within that large search space. This allows us to evaluate three different reinforcement-learning-based search strategies. Finally, compared to ResNet on its most optimal HW accelerator from within our HW design space, we improve on CIFAR-100 classification accuracy by 1.3% while simultaneously increasing performance/area by 41% in just~1000 GPU-hours of running Codesign-NAS.
Turbo Autoencoder: Deep learning based channel codes for point-to-point communication channels
Nov 08, 2019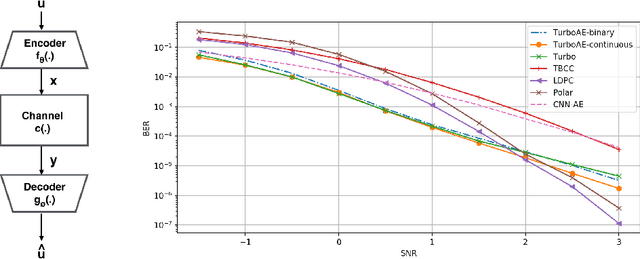

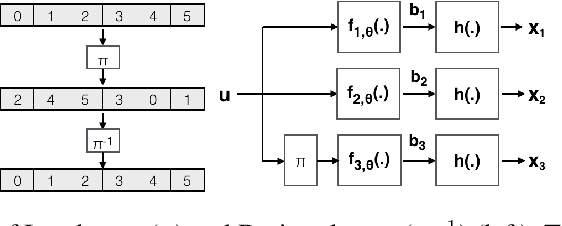

Designing codes that combat the noise in a communication medium has remained a significant area of research in information theory as well as wireless communications. Asymptotically optimal channel codes have been developed by mathematicians for communicating under canonical models after over 60 years of research. On the other hand, in many non-canonical channel settings, optimal codes do not exist and the codes designed for canonical models are adapted via heuristics to these channels and are thus not guaranteed to be optimal. In this work, we make significant progress on this problem by designing a fully end-to-end jointly trained neural encoder and decoder, namely, Turbo Autoencoder (TurboAE), with the following contributions: ($a$) under moderate block lengths, TurboAE approaches state-of-the-art performance under canonical channels; ($b$) moreover, TurboAE outperforms the state-of-the-art codes under non-canonical settings in terms of reliability. TurboAE shows that the development of channel coding design can be automated via deep learning, with near-optimal performance.
A Framework for Fast and Efficient Neural Network Compression
Dec 04, 2018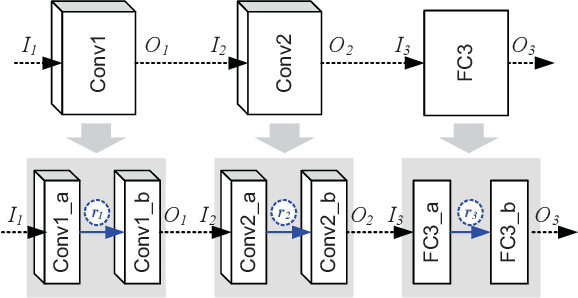
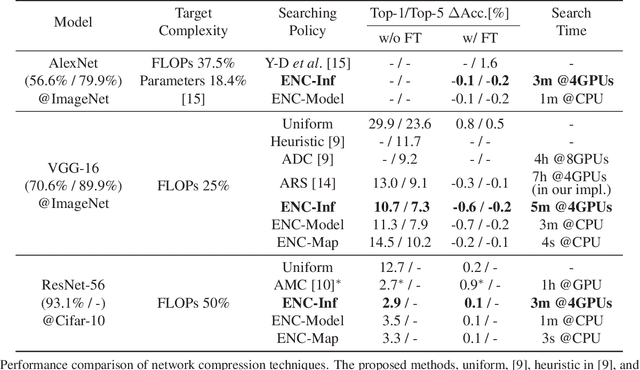
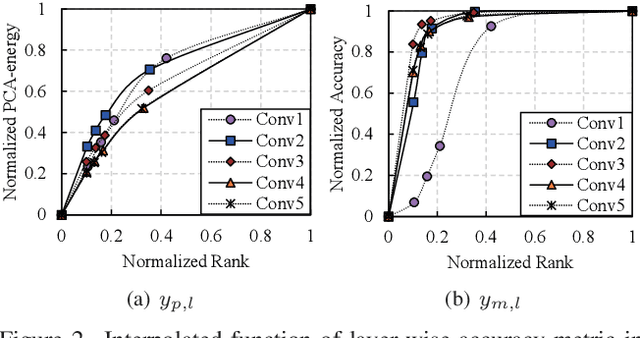
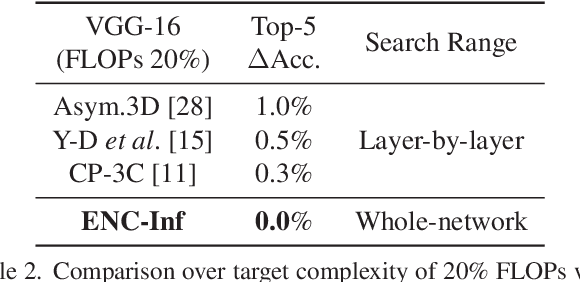
Network compression reduces the computational complexity and memory consumption of deep neural networks by reducing the number of parameters. In SVD-based network compression, the right rank needs to be decided for every layer of the network. In this paper, we propose an efficient method for obtaining the rank configuration of the whole network. Unlike previous methods which consider each layer separately, our method considers the whole network to choose the right rank configuration. We propose novel accuracy metrics to represent the accuracy and complexity relationship for a given neural network. We use these metrics in a non-iterative fashion to obtain the right rank configuration which satisfies the constraints on FLOPs and memory while maintaining sufficient accuracy. Experiments show that our method provides better compromise between accuracy and computational complexity/memory consumption while performing compression at much higher speed. For VGG-16 our network can reduce the FLOPs by 25% and improve accuracy by 0.7% compared to the baseline, while requiring only 3 minutes on a CPU to search for the right rank configuration. Previously, similar results were achieved in 4 hours with 8 GPUs. The proposed method can be used for lossless compression of neural network as well. The better accuracy and complexity compromise, as well as the extremely fast speed of our method makes it suitable for neural network compression.
LEARN Codes: Inventing Low-latency Codes via Recurrent Neural Networks
Nov 30, 2018
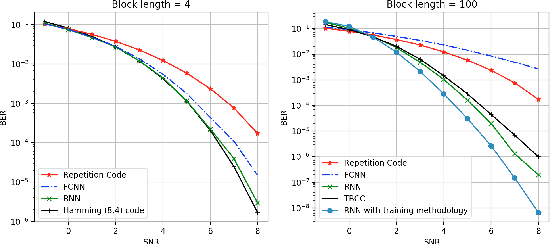
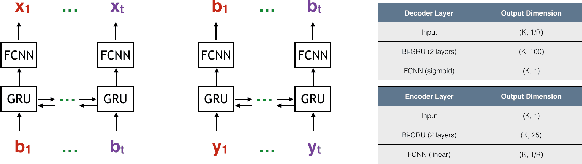
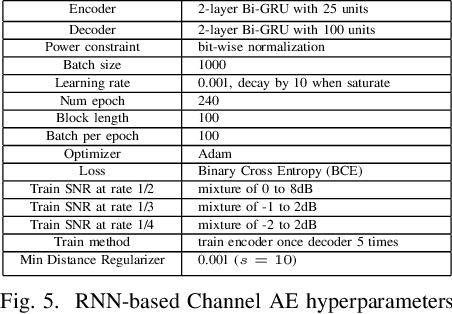
Designing channel codes under low latency constraints is one of the most demanding requirements in 5G standards. However, sharp characterizations of the performances of traditional codes are only available in the large block-length limit. Code designs are guided by those asymptotic analyses and require large block lengths and long latency to achieve the desired error rate. Furthermore, when the codes designed for one channel (e.g. Additive White Gaussian Noise (AWGN) channel) are used for another (e.g. non-AWGN channels), heuristics are necessary to achieve any nontrivial performance -thereby severely lacking in robustness as well as adaptivity. Obtained by jointly designing Recurrent Neural Network (RNN) based encoder and decoder, we propose an end-to-end learned neural code which outperforms canonical convolutional code under block settings. With this gained experience of designing a novel neural block code, we propose a new class of codes under low latency constraint - Low-latency Efficient Adaptive Robust Neural (LEARN) codes, which outperforms the state-of-the-art low latency codes as well as exhibits robustness and adaptivity properties. LEARN codes show the potential of designing new versatile and universal codes for future communications via tools of modern deep learning coupled with communication engineering insights.
Deepcode: Feedback Codes via Deep Learning
Jul 02, 2018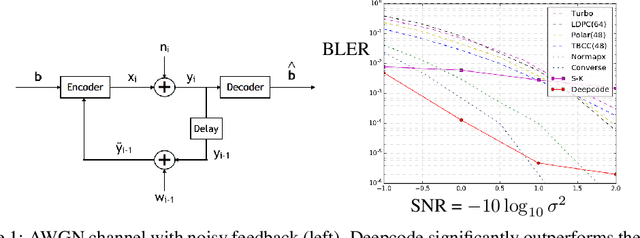
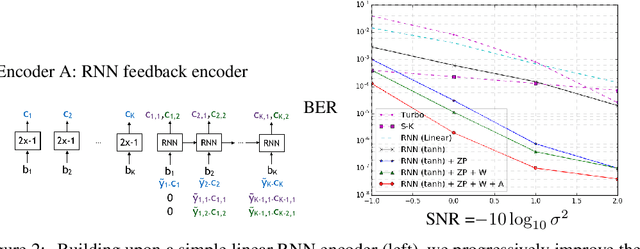
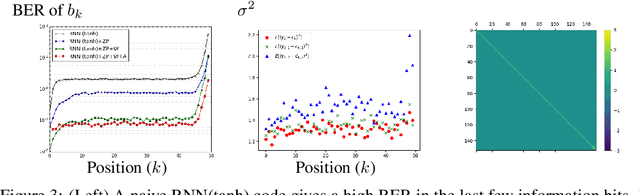
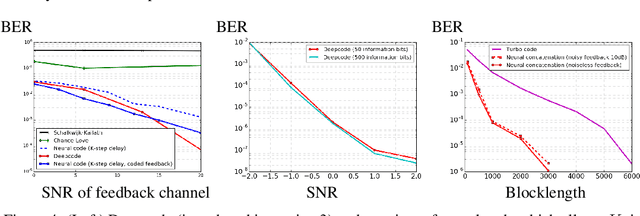
The design of codes for communicating reliably over a statistically well defined channel is an important endeavor involving deep mathematical research and wide-ranging practical applications. In this work, we present the first family of codes obtained via deep learning, which significantly beats state-of-the-art codes designed over several decades of research. The communication channel under consideration is the Gaussian noise channel with feedback, whose study was initiated by Shannon; feedback is known theoretically to improve reliability of communication, but no practical codes that do so have ever been successfully constructed. We break this logjam by integrating information theoretic insights harmoniously with recurrent-neural-network based encoders and decoders to create novel codes that outperform known codes by 3 orders of magnitude in reliability. We also demonstrate several desirable properties of the codes: (a) generalization to larger block lengths, (b) composability with known codes, (c) adaptation to practical constraints. This result also has broader ramifications for coding theory: even when the channel has a clear mathematical model, deep learning methodologies, when combined with channel-specific information-theoretic insights, can potentially beat state-of-the-art codes constructed over decades of mathematical research.
Automatic Rank Selection for High-Speed Convolutional Neural Network
Jun 29, 2018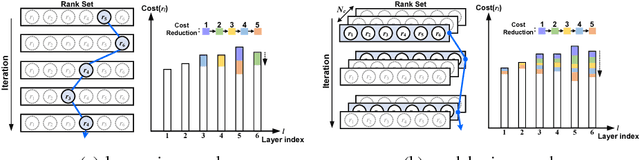
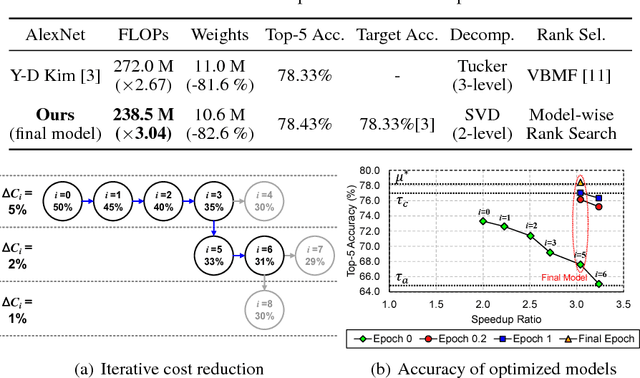

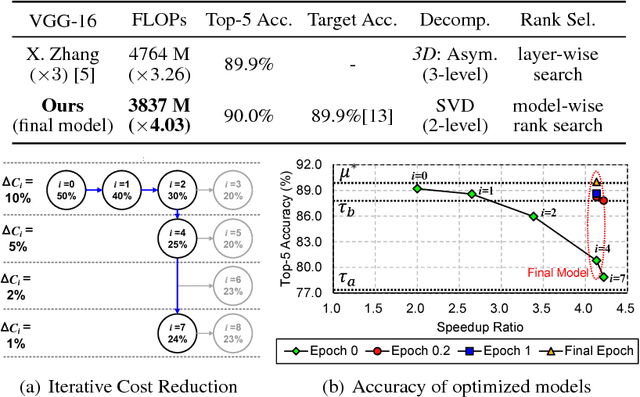
Low-rank decomposition plays a central role in accelerating convolutional neural network (CNN), and the rank of decomposed kernel-tensor is a key parameter that determines the complexity and accuracy of a neural network. In this paper, we define rank selection as a combinatorial optimization problem and propose a methodology to minimize network complexity while maintaining the desired accuracy. Combinatorial optimization is not feasible due to search space limitations. To restrict the search space and obtain the optimal rank, we define the space constraint parameters with a boundary condition. We also propose a linearly-approximated accuracy function to predict the fine-tuned accuracy of the optimized CNN model during the cost reduction. Experimental results on AlexNet and VGG-16 show that the proposed rank selection algorithm satisfies the accuracy constraint. Our method combined with truncated-SVD outperforms state-of-the-art methods in terms of inference and training time at almost the same accuracy.