 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreased-Range Unsupervised Monocular Depth Estimation
Jun 23, 2020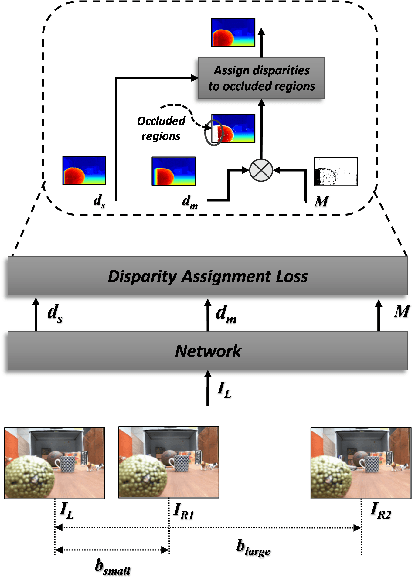
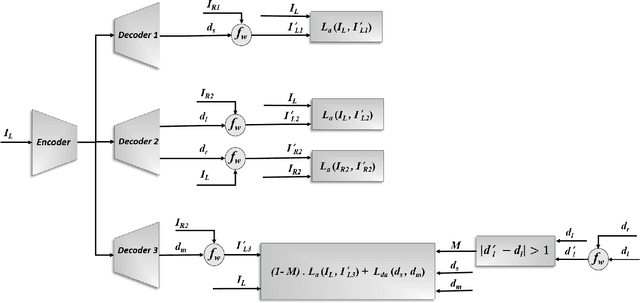
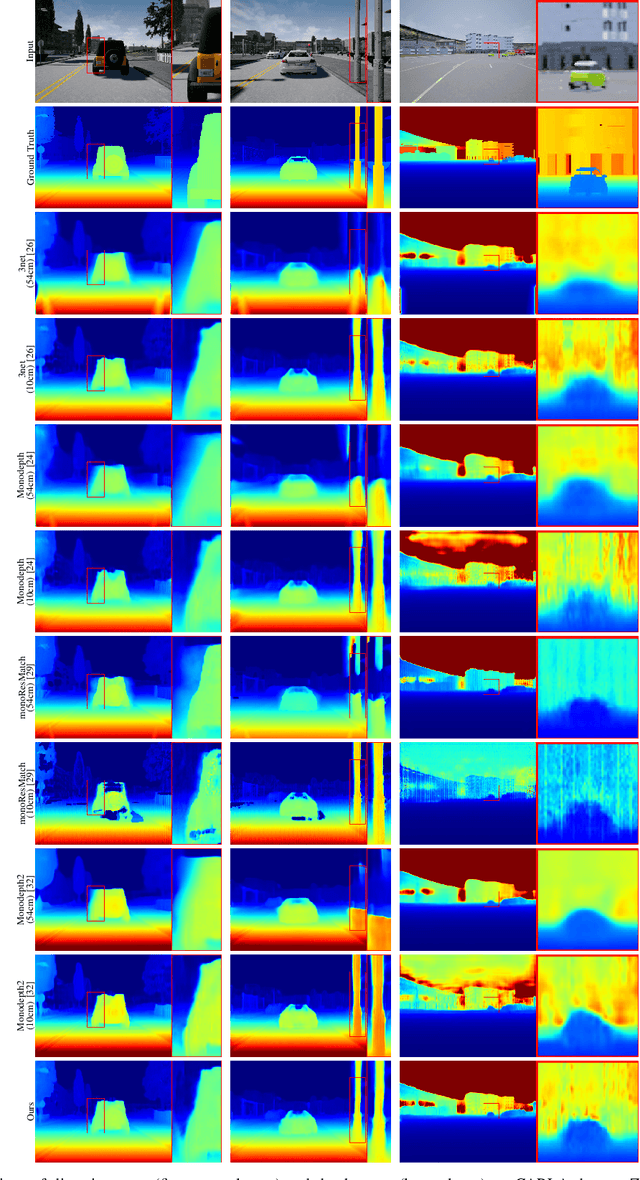
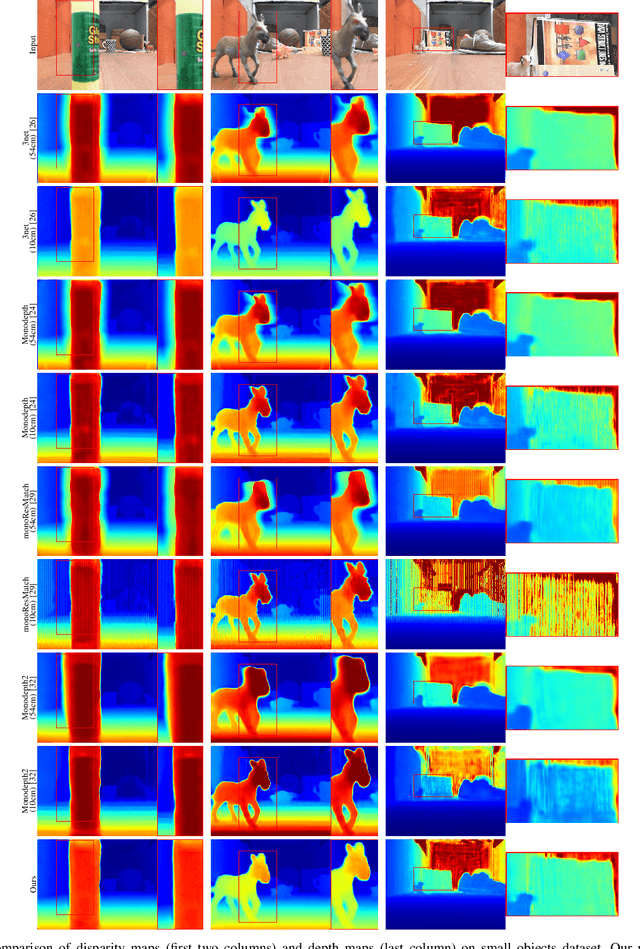
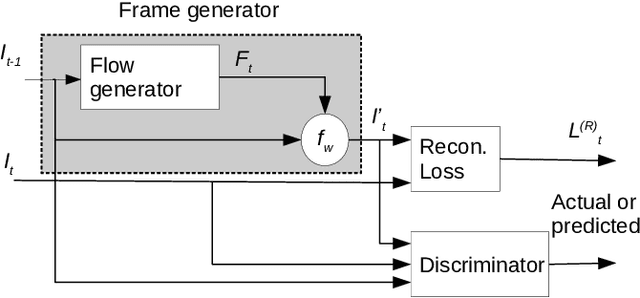
Unsupervised deep learning methods have shown promising performance for single-image depth estimation. Since most of these methods use binocular stereo pairs for self-supervision, the depth range is generally limited. Small-baseline stereo pairs provide small depth range but handle occlusions well. On the other hand, stereo images acquired with a wide-baseline rig cause occlusions-related errors in the near range but estimate depth well in the far range. In this work, we propose to integrate the advantages of the small and wide baselines. By training the network using three horizontally aligned views, we obtain accurate depth predictions for both close and far ranges. Our strategy allows to infer multi-baseline depth from a single image. This is unlike previous multi-baseline systems which employ more than two cameras. The qualitative and quantitative results show the superior performance of multi-baseline approach over previous stereo-based monocular methods. For 0.1 to 80 meters depth range, our approach decreases the absolute relative error of depth by 24% compared to Monodepth2. Our approach provides 21 frames per second on a single Nvidia1080 GPU, making it useful for practical applications.
Fine-Tuning DARTS for Image Classification
Jun 16, 2020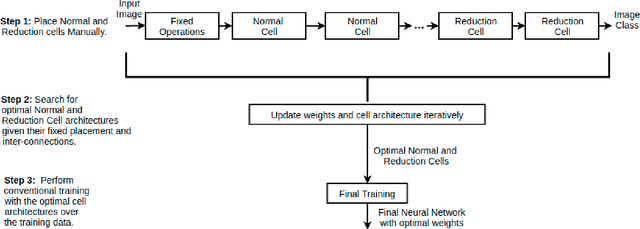
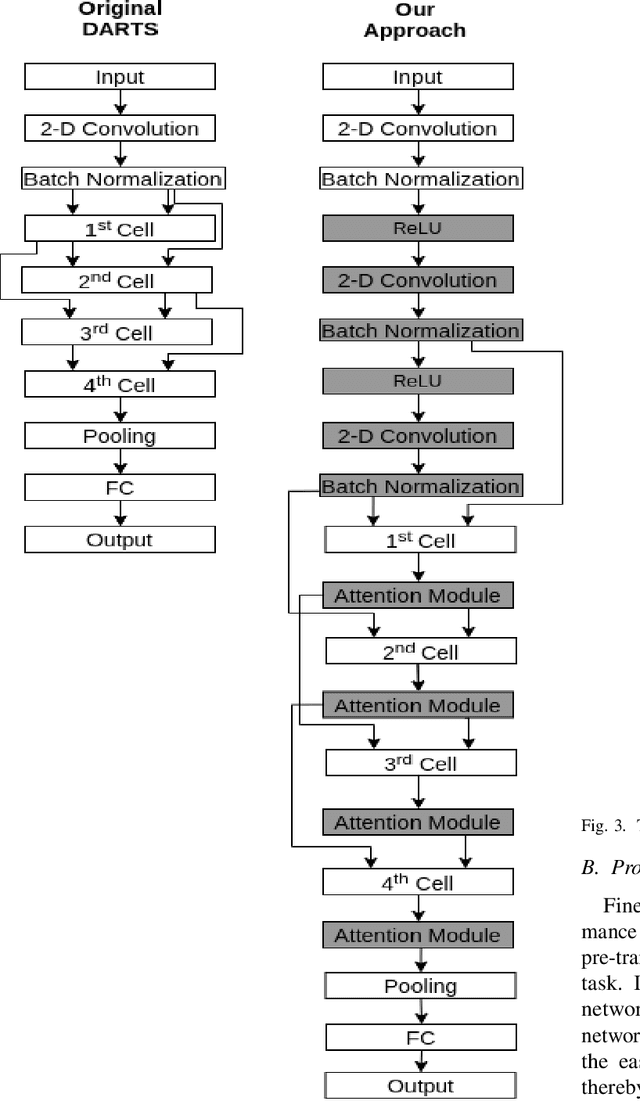
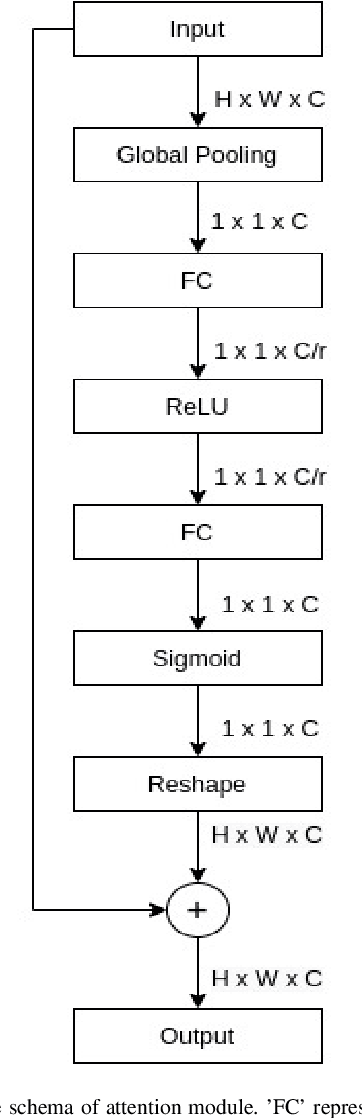
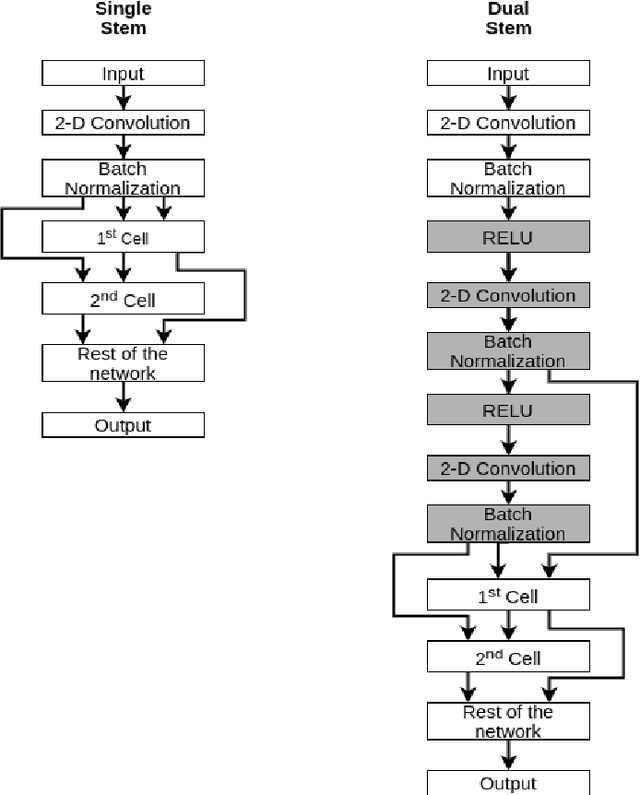
Neural Architecture Search (NAS) has gained attraction due to superior classification performance. Differential Architecture Search (DARTS) is a computationally light method. To limit computational resources DARTS makes numerous approximations. These approximations result in inferior performance. We propose to fine-tune DARTS using fixed operations as they are independent of these approximations. Our method offers a good trade-off between the number of parameters and classification accuracy. Our approach improves the top-1 accuracy on Fashion-MNIST, CompCars, and MIO-TCD datasets by 0.56%, 0.50%, and 0.39%, respectively compared to the state-of-the-art approaches. Our approach performs better than DARTS, improving the accuracy by 0.28%, 1.64%, 0.34%, 4.5%, and 3.27% compared to DARTS, on CIFAR-10, CIFAR-100, Fashion-MNIST, CompCars, and MIO-TCD datasets, respectively.
Plug-and-Play Anomaly Detection with Expectation Maximization Filtering
Jun 16, 2020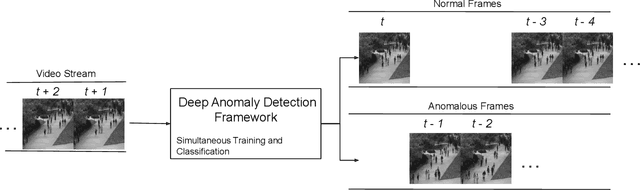


Anomaly detection in crowds enables early rescue response. A plug-and-play smart camera for crowd surveillance has numerous constraints different from typical anomaly detection: the training data cannot be used iteratively; there are no training labels; and training and classification needs to be performed simultaneously. We tackle all these constraints with our approach in this paper. We propose a Core Anomaly-Detection (CAD) neural network which learns the motion behavior of objects in the scene with an unsupervised method. On average over standard datasets, CAD with a single epoch of training shows a percentage increase in Area Under the Curve (AUC) of 4.66% and 4.9% compared to the best results with convolutional autoencoders and convolutional LSTM-based methods, respectively. With a single epoch of training, our method improves the AUC by 8.03% compared to the convolutional LSTM-based approach. We also propose an Expectation Maximization filter which chooses samples for training the core anomaly-detection network. The overall framework improves the AUC compared to future frame prediction-based approach by 24.87% when crowd anomaly detection is performed on a video stream. We believe our work is the first step towards using deep learning methods with autonomous plug-and-play smart cameras for crowd anomaly detection.
A Framework for Fast and Efficient Neural Network Compression
Dec 04, 2018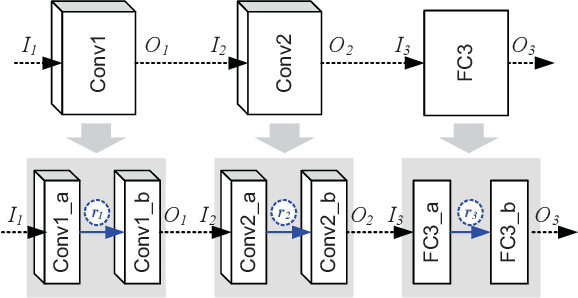
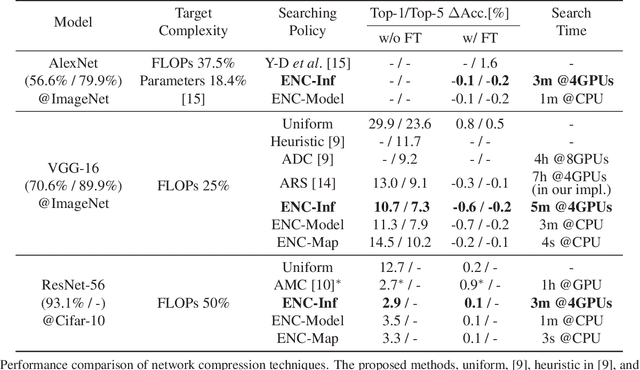
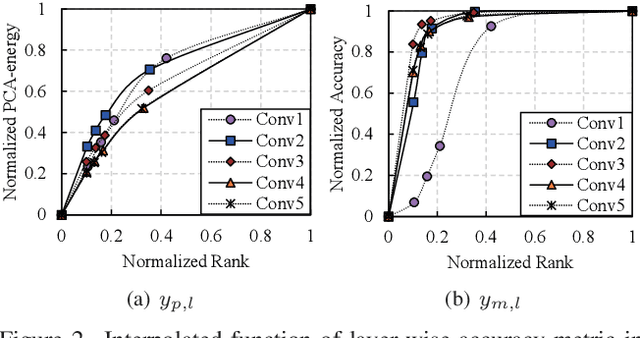
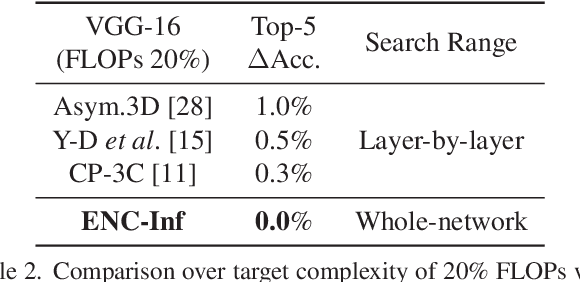
Network compression reduces the computational complexity and memory consumption of deep neural networks by reducing the number of parameters. In SVD-based network compression, the right rank needs to be decided for every layer of the network. In this paper, we propose an efficient method for obtaining the rank configuration of the whole network. Unlike previous methods which consider each layer separately, our method considers the whole network to choose the right rank configuration. We propose novel accuracy metrics to represent the accuracy and complexity relationship for a given neural network. We use these metrics in a non-iterative fashion to obtain the right rank configuration which satisfies the constraints on FLOPs and memory while maintaining sufficient accuracy. Experiments show that our method provides better compromise between accuracy and computational complexity/memory consumption while performing compression at much higher speed. For VGG-16 our network can reduce the FLOPs by 25% and improve accuracy by 0.7% compared to the baseline, while requiring only 3 minutes on a CPU to search for the right rank configuration. Previously, similar results were achieved in 4 hours with 8 GPUs. The proposed method can be used for lossless compression of neural network as well. The better accuracy and complexity compromise, as well as the extremely fast speed of our method makes it suitable for neural network compression.
Automatic Rank Selection for High-Speed Convolutional Neural Network
Jun 29, 2018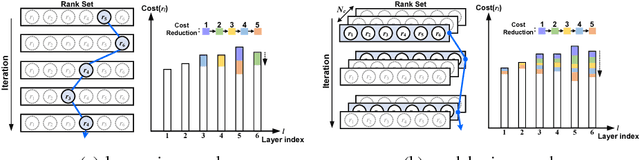
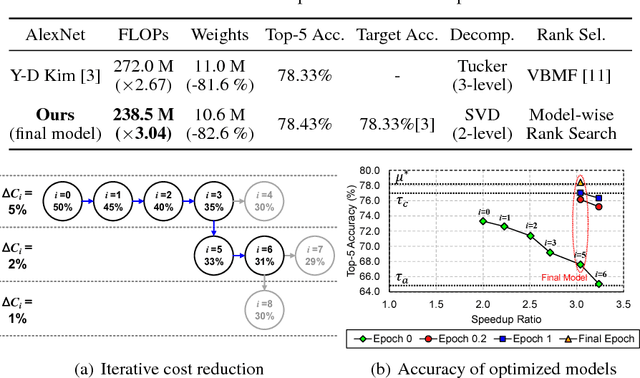

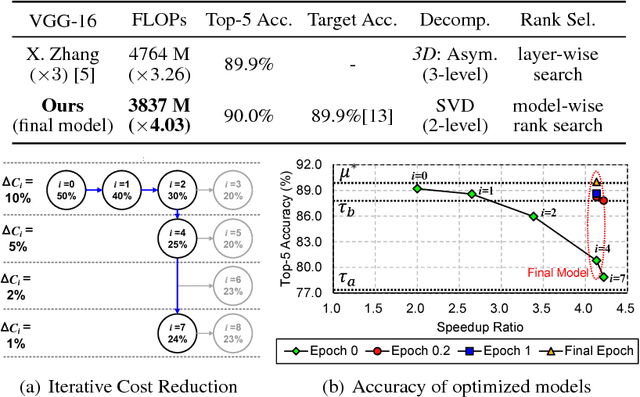
Low-rank decomposition plays a central role in accelerating convolutional neural network (CNN), and the rank of decomposed kernel-tensor is a key parameter that determines the complexity and accuracy of a neural network. In this paper, we define rank selection as a combinatorial optimization problem and propose a methodology to minimize network complexity while maintaining the desired accuracy. Combinatorial optimization is not feasible due to search space limitations. To restrict the search space and obtain the optimal rank, we define the space constraint parameters with a boundary condition. We also propose a linearly-approximated accuracy function to predict the fine-tuned accuracy of the optimized CNN model during the cost reduction. Experimental results on AlexNet and VGG-16 show that the proposed rank selection algorithm satisfies the accuracy constraint. Our method combined with truncated-SVD outperforms state-of-the-art methods in terms of inference and training time at almost the same accuracy.