 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Topology-Specific Experts for Molecular Property Prediction
Mar 12, 2023Recently, graph neural networks (GNNs) have been successfully applied to predicting molecular properties, which is one of the most classical cheminformatics tasks with various applications. Despite their effectiveness, we empirically observe that training a single GNN model for diverse molecules with distinct structural patterns limits its prediction performance. In this paper, motivated by this observation, we propose TopExpert to leverage topology-specific prediction models (referred to as experts), each of which is responsible for each molecular group sharing similar topological semantics. That is, each expert learns topology-specific discriminative features while being trained with its corresponding topological group. To tackle the key challenge of grouping molecules by their topological patterns, we introduce a clustering-based gating module that assigns an input molecule into one of the clusters and further optimizes the gating module with two different types of self-supervision: topological semantics induced by GNNs and molecular scaffolds, respectively. Extensive experiments demonstrate that TopExpert has boosted the performance for molecular property prediction and also achieved better generalization for new molecules with unseen scaffolds than baselines. The code is available at https://github.com/kimsu55/ToxExpert.
* 11 pages with 8 figures
Distillation from Heterogeneous Models for Top-K Recommendation
Mar 02, 2023Recent recommender systems have shown remarkable performance by using an ensemble of heterogeneous models. However, it is exceedingly costly because it requires resources and inference latency proportional to the number of models, which remains the bottleneck for production. Our work aims to transfer the ensemble knowledge of heterogeneous teachers to a lightweight student model using knowledge distillation (KD), to reduce the huge inference costs while retaining high accuracy. Through an empirical study, we find that the efficacy of distillation severely drops when transferring knowledge from heterogeneous teachers. Nevertheless, we show that an important signal to ease the difficulty can be obtained from the teacher's training trajectory. This paper proposes a new KD framework, named HetComp, that guides the student model by transferring easy-to-hard sequences of knowledge generated from the teachers' trajectories. To provide guidance according to the student's learning state, HetComp uses dynamic knowledge construction to provide progressively difficult ranking knowledge and adaptive knowledge transfer to gradually transfer finer-grained ranking information. Our comprehensive experiments show that HetComp significantly improves the distillation quality and the generalization of the student model.
Dynamic Multi-Behavior Sequence Modeling for Next Item Recommendation
Jan 28, 2023Sequential Recommender Systems (SRSs) aim to predict the next item that users will consume, by modeling the user interests within their item sequences. While most existing SRSs focus on a single type of user behavior, only a few pay attention to multi-behavior sequences, although they are very common in real-world scenarios. It is challenging to effectively capture the user interests within multi-behavior sequences, because the information about user interests is entangled throughout the sequences in complex relationships. To this end, we first address the characteristics of multi-behavior sequences that should be considered in SRSs, and then propose novel methods for Dynamic Multi-behavior Sequence modeling named DyMuS, which is a light version, and DyMuS+, which is an improved version, considering the characteristics. DyMuS first encodes each behavior sequence independently, and then combines the encoded sequences using dynamic routing, which dynamically integrates information required in the final result from among many candidates, based on correlations between the sequences. DyMuS+, furthermore, applies the dynamic routing even to encoding each behavior sequence to further capture the correlations at item-level. Moreover, we release a new, large and up-to-date dataset for multi-behavior recommendation. Our experiments on DyMuS and DyMuS+ show their superiority and the significance of capturing the characteristics of multi-behavior sequences.
Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization
Dec 21, 2022Sentence summarization shortens given texts while maintaining core contents of the texts. Unsupervised approaches have been studied to summarize texts without human-written summaries. However, recent unsupervised models are extractive, which remove words from texts and thus they are less flexible than abstractive summarization. In this work, we devise an abstractive model based on reinforcement learning without ground-truth summaries. We formulate the unsupervised summarization based on the Markov decision process with rewards representing the summary quality. To further enhance the summary quality, we develop a multi-summary learning mechanism that generates multiple summaries with varying lengths for a given text, while making the summaries mutually enhance each other. Experimental results show that the proposed model substantially outperforms both abstractive and extractive models, yet frequently generating new words not contained in input texts.
Beyond Learning from Next Item: Sequential Recommendation via Personalized Interest Sustainability
Sep 14, 2022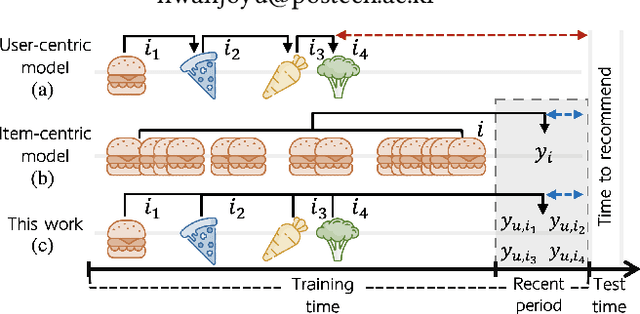
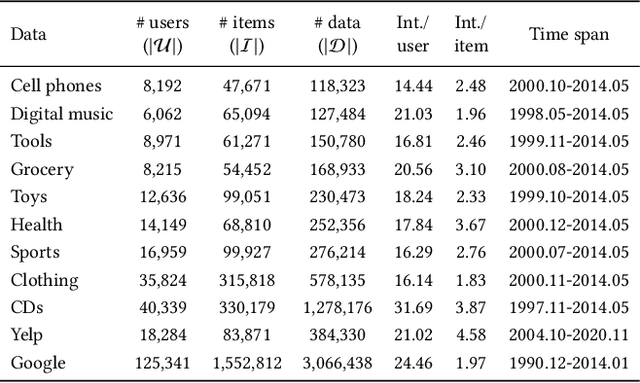
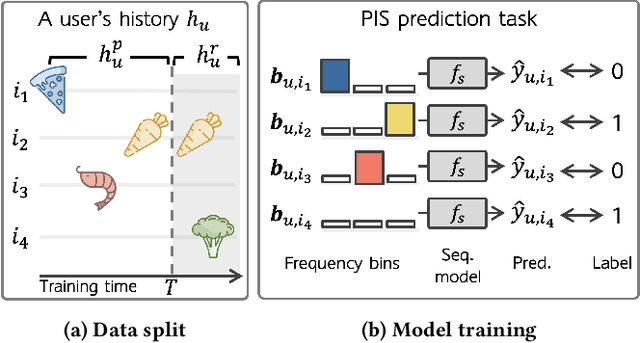
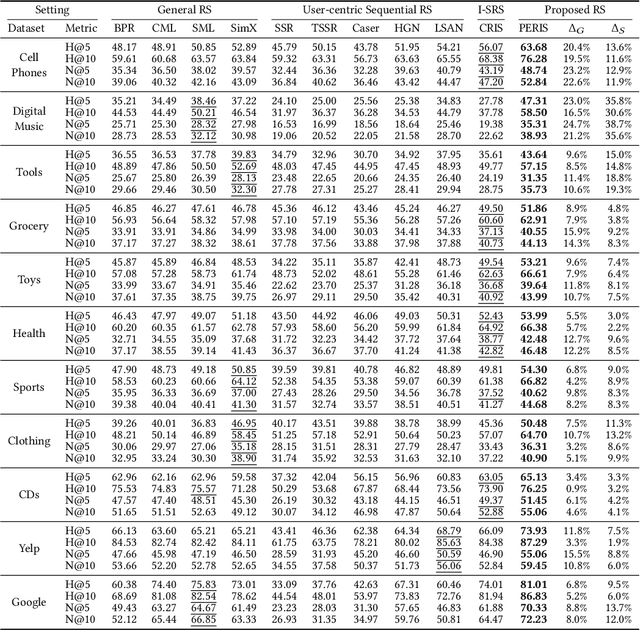
Sequential recommender systems have shown effective suggestions by capturing users' interest drift. There have been two groups of existing sequential models: user- and item-centric models. The user-centric models capture personalized interest drift based on each user's sequential consumption history, but do not explicitly consider whether users' interest in items sustains beyond the training time, i.e., interest sustainability. On the other hand, the item-centric models consider whether users' general interest sustains after the training time, but it is not personalized. In this work, we propose a recommender system taking advantages of the models in both categories. Our proposed model captures personalized interest sustainability, indicating whether each user's interest in items will sustain beyond the training time or not. We first formulate a task that requires to predict which items each user will consume in the recent period of the training time based on users' consumption history. We then propose simple yet effective schemes to augment users' sparse consumption history. Extensive experiments show that the proposed model outperforms 10 baseline models on 11 real-world datasets. The codes are available at https://github.com/dmhyun/PERIS.
Toward Interpretable Semantic Textual Similarity via Optimal Transport-based Contrastive Sentence Learning
Feb 26, 2022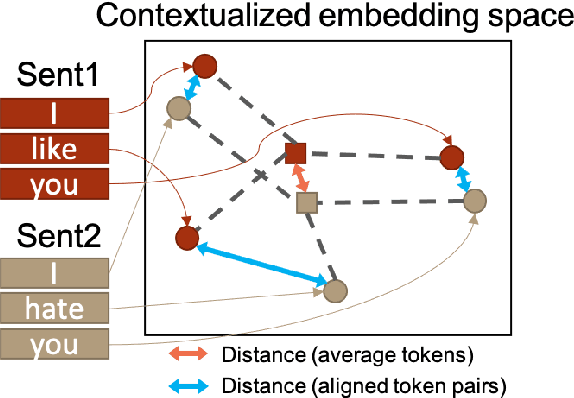
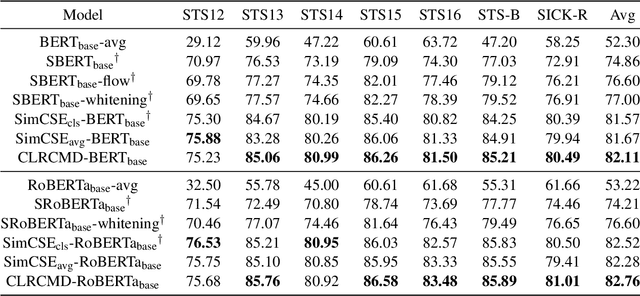

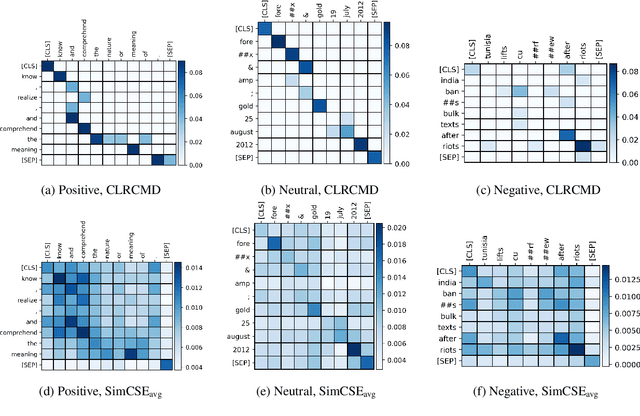
Recently, finetuning a pretrained language model to capture the similarity between sentence embeddings has shown the state-of-the-art performance on the semantic textual similarity (STS) task. However, the absence of an interpretation method for the sentence similarity makes it difficult to explain the model output. In this work, we explicitly describe the sentence distance as the weighted sum of contextualized token distances on the basis of a transportation problem, and then present the optimal transport-based distance measure, named RCMD; it identifies and leverages semantically-aligned token pairs. In the end, we propose CLRCMD, a contrastive learning framework that optimizes RCMD of sentence pairs, which enhances the quality of sentence similarity and their interpretation. Extensive experiments demonstrate that our learning framework outperforms other baselines on both STS and interpretable-STS benchmarks, indicating that it computes effective sentence similarity and also provides interpretation consistent with human judgement.
Consensus Learning from Heterogeneous Objectives for One-Class Collaborative Filtering
Feb 26, 2022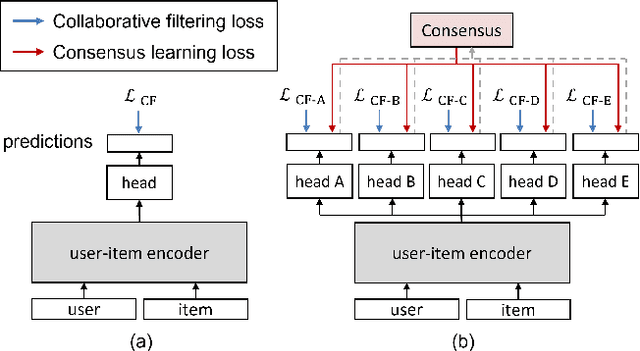
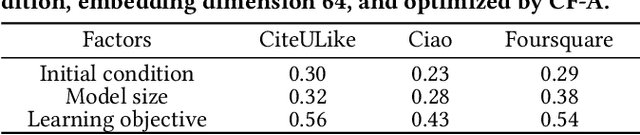
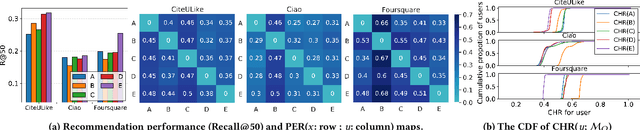
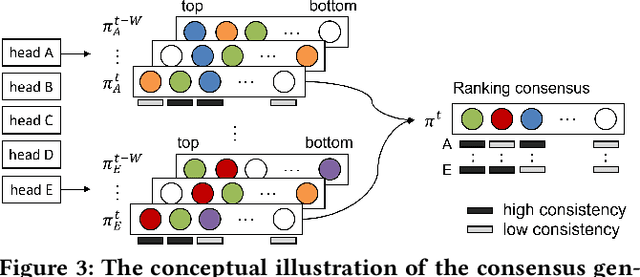
Over the past decades, for One-Class Collaborative Filtering (OCCF), many learning objectives have been researched based on a variety of underlying probabilistic models. From our analysis, we observe that models trained with different OCCF objectives capture distinct aspects of user-item relationships, which in turn produces complementary recommendations. This paper proposes a novel OCCF framework, named ConCF, that exploits the complementarity from heterogeneous objectives throughout the training process, generating a more generalizable model. ConCF constructs a multi-branch variant of a given target model by adding auxiliary heads, each of which is trained with heterogeneous objectives. Then, it generates consensus by consolidating the various views from the heads, and guides the heads based on the consensus. The heads are collaboratively evolved based on their complementarity throughout the training, which again results in generating more accurate consensus iteratively. After training, we convert the multi-branch architecture back to the original target model by removing the auxiliary heads, thus there is no extra inference cost for the deployment. Our extensive experiments on real-world datasets demonstrate that ConCF significantly improves the generalization of the model by exploiting the complementarity from heterogeneous objectives.
TaxoCom: Topic Taxonomy Completion with Hierarchical Discovery of Novel Topic Clusters
Jan 19, 2022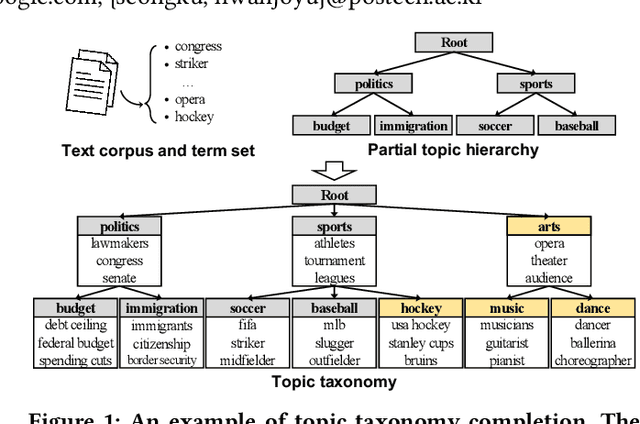
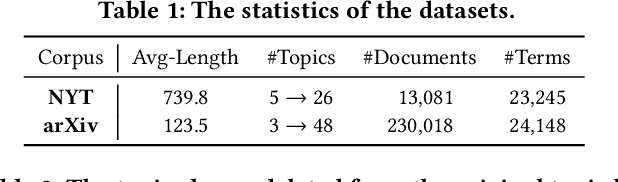
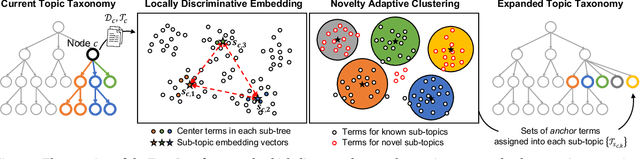
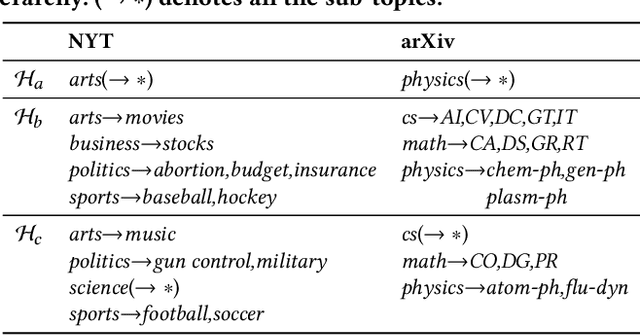
Topic taxonomies, which represent the latent topic (or category) structure of document collections, provide valuable knowledge of contents in many applications such as web search and information filtering. Recently, several unsupervised methods have been developed to automatically construct the topic taxonomy from a text corpus, but it is challenging to generate the desired taxonomy without any prior knowledge. In this paper, we study how to leverage the partial (or incomplete) information about the topic structure as guidance to find out the complete topic taxonomy. We propose a novel framework for topic taxonomy completion, named TaxoCom, which recursively expands the topic taxonomy by discovering novel sub-topic clusters of terms and documents. To effectively identify novel topics within a hierarchical topic structure, TaxoCom devises its embedding and clustering techniques to be closely-linked with each other: (i) locally discriminative embedding optimizes the text embedding space to be discriminative among known (i.e., given) sub-topics, and (ii) novelty adaptive clustering assigns terms into either one of the known sub-topics or novel sub-topics. Our comprehensive experiments on two real-world datasets demonstrate that TaxoCom not only generates the high-quality topic taxonomy in terms of term coherency and topic coverage but also outperforms all other baselines for a downstream task.
Obtaining Calibrated Probabilities with Personalized Ranking Models
Dec 09, 2021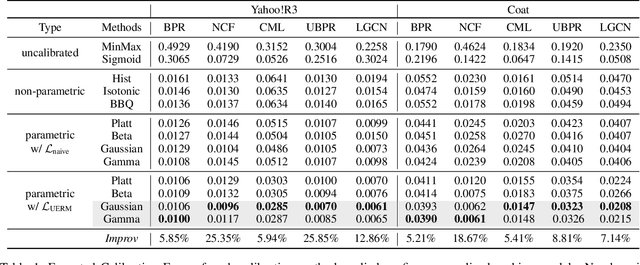
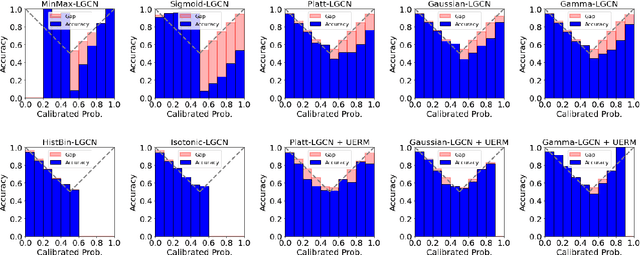
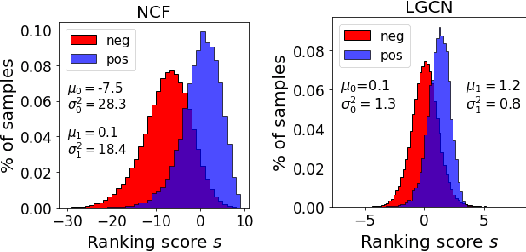
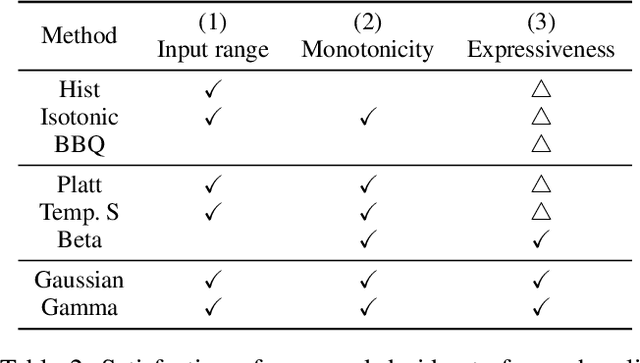
For personalized ranking models, the well-calibrated probability of an item being preferred by a user has great practical value. While existing work shows promising results in image classification, probability calibration has not been much explored for personalized ranking. In this paper, we aim to estimate the calibrated probability of how likely a user will prefer an item. We investigate various parametric distributions and propose two parametric calibration methods, namely Gaussian calibration and Gamma calibration. Each proposed method can be seen as a post-processing function that maps the ranking scores of pre-trained models to well-calibrated preference probabilities, without affecting the recommendation performance. We also design the unbiased empirical risk minimization framework that guides the calibration methods to learning of true preference probability from the biased user-item interaction dataset. Extensive evaluations with various personalized ranking models on real-world datasets show that both the proposed calibration methods and the unbiased empirical risk minimization significantly improve the calibration performance.
Out-of-Category Document Identification Using Target-Category Names as Weak Supervision
Nov 24, 2021
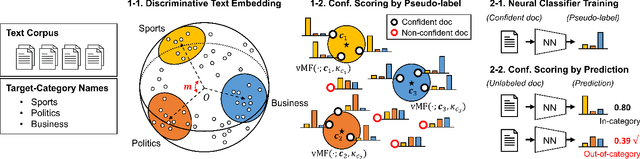

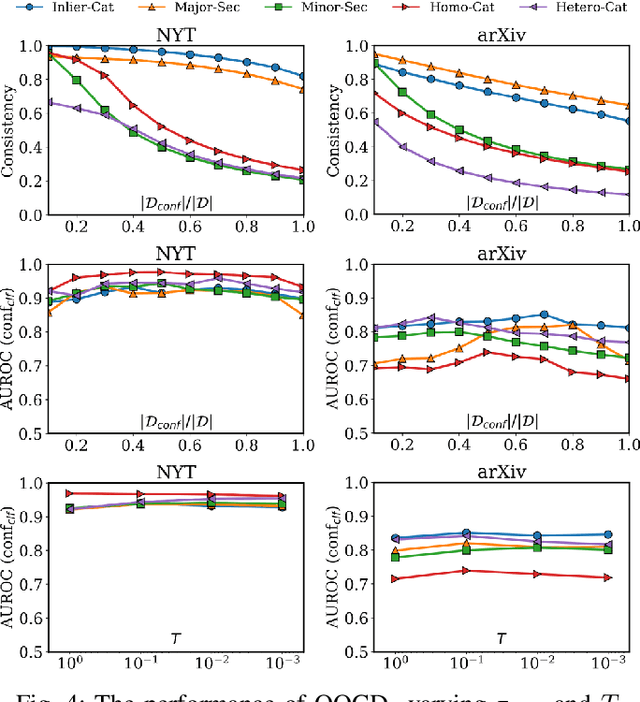
Identifying outlier documents, whose content is different from the majority of the documents in a corpus, has played an important role to manage a large text collection. However, due to the absence of explicit information about the inlier (or target) distribution, existing unsupervised outlier detectors are likely to make unreliable results depending on the density or diversity of the outliers in the corpus. To address this challenge, we introduce a new task referred to as out-of-category detection, which aims to distinguish the documents according to their semantic relevance to the inlier (or target) categories by using the category names as weak supervision. In practice, this task can be widely applicable in that it can flexibly designate the scope of target categories according to users' interests while requiring only the target-category names as minimum guidance. In this paper, we present an out-of-category detection framework, which effectively measures how confidently each document belongs to one of the target categories based on its category-specific relevance score. Our framework adopts a two-step approach; (i) it first generates the pseudo-category label of all unlabeled documents by exploiting the word-document similarity encoded in a text embedding space, then (ii) it trains a neural classifier by using the pseudo-labels in order to compute the confidence from its target-category prediction. The experiments on real-world datasets demonstrate that our framework achieves the best detection performance among all baseline methods in various scenarios specifying different target categories.