 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Collaborative Distillation for Recommender System
May 29, 2024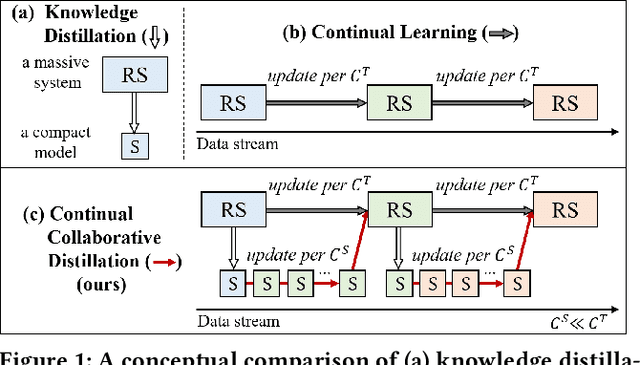
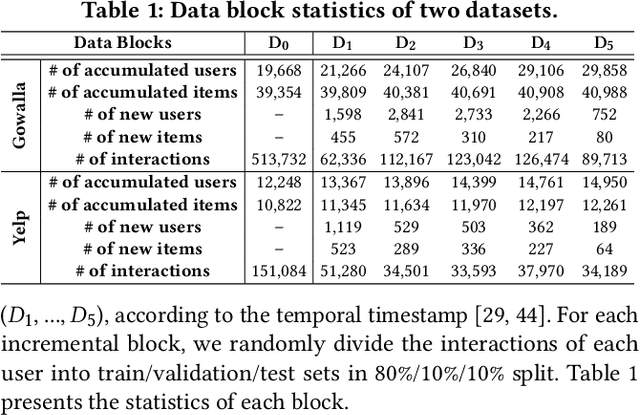
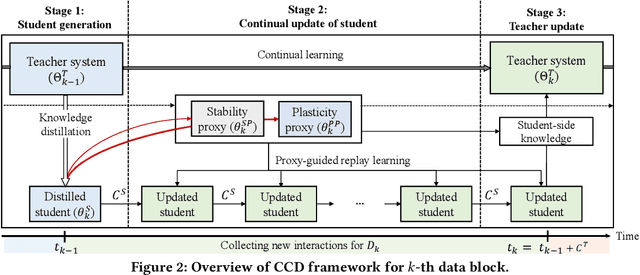
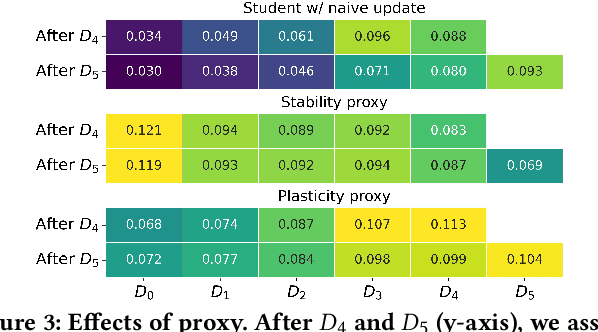
Knowledge distillation (KD) has emerged as a promising technique for addressing the computational challenges associated with deploying large-scale recommender systems. KD transfers the knowledge of a massive teacher system to a compact student model, to reduce the huge computational burdens for inference while retaining high accuracy. The existing KD studies primarily focus on one-time distillation in static environments, leaving a substantial gap in their applicability to real-world scenarios dealing with continuously incoming users, items, and their interactions. In this work, we delve into a systematic approach to operating the teacher-student KD in a non-stationary data stream. Our goal is to enable efficient deployment through a compact student, which preserves the high performance of the massive teacher, while effectively adapting to continuously incoming data. We propose Continual Collaborative Distillation (CCD) framework, where both the teacher and the student continually and collaboratively evolve along the data stream. CCD facilitates the student in effectively adapting to new data, while also enabling the teacher to fully leverage accumulated knowledge. We validate the effectiveness of CCD through extensive quantitative, ablative, and exploratory experiments on two real-world datasets. We expect this research direction to contribute to narrowing the gap between existing KD studies and practical applications, thereby enhancing the applicability of KD in real-world systems.
Rectifying Demonstration Shortcut in In-Context Learning
Mar 29, 2024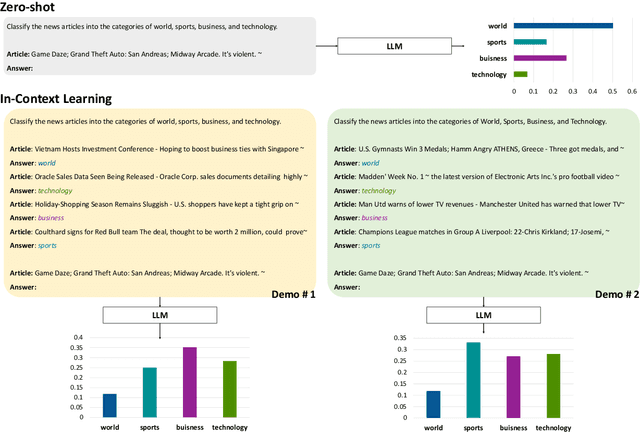
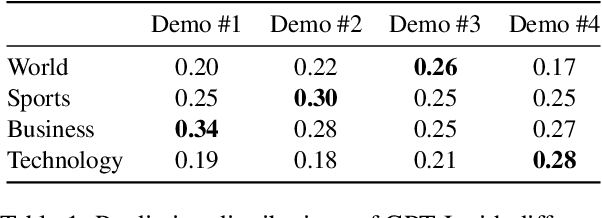
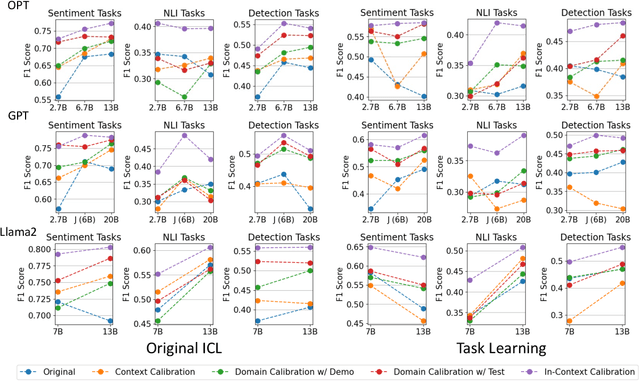

Large language models (LLMs) are able to solve various tasks with only a few demonstrations utilizing their in-context learning (ICL) abilities. However, LLMs often rely on their pre-trained semantic priors of demonstrations rather than on the input-label relationships to proceed with ICL prediction. In this work, we term this phenomenon as the 'Demonstration Shortcut'. While previous works have primarily focused on improving ICL prediction results for predefined tasks, we aim to rectify the Demonstration Shortcut, thereby enabling the LLM to effectively learn new input-label relationships from demonstrations. To achieve this, we introduce In-Context Calibration, a demonstration-aware calibration method. We evaluate the effectiveness of the proposed method in two settings: (1) the Original ICL Task using the standard label space and (2) the Task Learning setting, where the label space is replaced with semantically unrelated tokens. In both settings, In-Context Calibration demonstrates substantial improvements, with results generalized across three LLM families (OPT, GPT, and Llama2) under various configurations.
Multi-Domain Recommendation to Attract Users via Domain Preference Modeling
Mar 26, 2024Recently, web platforms have been operating various service domains simultaneously. Targeting a platform that operates multiple service domains, we introduce a new task, Multi-Domain Recommendation to Attract Users (MDRAU), which recommends items from multiple ``unseen'' domains with which each user has not interacted yet, by using knowledge from the user's ``seen'' domains. In this paper, we point out two challenges of MDRAU task. First, there are numerous possible combinations of mappings from seen to unseen domains because users have usually interacted with a different subset of service domains. Second, a user might have different preferences for each of the target unseen domains, which requires that recommendations reflect the user's preferences on domains as well as items. To tackle these challenges, we propose DRIP framework that models users' preferences at two levels (i.e., domain and item) and learns various seen-unseen domain mappings in a unified way with masked domain modeling. Our extensive experiments demonstrate the effectiveness of DRIP in MDRAU task and its ability to capture users' domain-level preferences.
Exploring Language Model's Code Generation Ability with Auxiliary Functions
Mar 15, 2024



Auxiliary function is a helpful component to improve language model's code generation ability. However, a systematic exploration of how they affect has yet to be done. In this work, we comprehensively evaluate the ability to utilize auxiliary functions encoded in recent code-pretrained language models. First, we construct a human-crafted evaluation set, called HumanExtension, which contains examples of two functions where one function assists the other. With HumanExtension, we design several experiments to examine their ability in a multifaceted way. Our evaluation processes enable a comprehensive understanding of including auxiliary functions in the prompt in terms of effectiveness and robustness. An additional implementation style analysis captures the models' various implementation patterns when they access the auxiliary function. Through this analysis, we discover the models' promising ability to utilize auxiliary functions including their self-improving behavior by implementing the two functions step-by-step. However, our analysis also reveals the model's underutilized behavior to call the auxiliary function, suggesting the future direction to enhance their implementation by eliciting the auxiliary function call ability encoded in the models. We release our code and dataset to facilitate this research direction.
Improving Matrix Completion by Exploiting Rating Ordinality in Graph Neural Networks
Mar 07, 2024Matrix completion is an important area of research in recommender systems. Recent methods view a rating matrix as a user-item bi-partite graph with labeled edges denoting observed ratings and predict the edges between the user and item nodes by using the graph neural network (GNN). Despite their effectiveness, they treat each rating type as an independent relation type and thus cannot sufficiently consider the ordinal nature of the ratings. In this paper, we explore a new approach to exploit rating ordinality for GNN, which has not been studied well in the literature. We introduce a new method, called ROGMC, to leverage Rating Ordinality in GNN-based Matrix Completion. It uses cumulative preference propagation to directly incorporate rating ordinality in GNN's message passing, allowing for users' stronger preferences to be more emphasized based on inherent orders of rating types. This process is complemented by interest regularization which facilitates preference learning using the underlying interest information. Our extensive experiments show that ROGMC consistently outperforms the existing strategies of using rating types for GNN. We expect that our attempt to explore the feasibility of utilizing rating ordinality for GNN may stimulate further research in this direction.
Improving Retrieval in Theme-specific Applications using a Corpus Topical Taxonomy
Mar 07, 2024Document retrieval has greatly benefited from the advancements of large-scale pre-trained language models (PLMs). However, their effectiveness is often limited in theme-specific applications for specialized areas or industries, due to unique terminologies, incomplete contexts of user queries, and specialized search intents. To capture the theme-specific information and improve retrieval, we propose to use a corpus topical taxonomy, which outlines the latent topic structure of the corpus while reflecting user-interested aspects. We introduce ToTER (Topical Taxonomy Enhanced Retrieval) framework, which identifies the central topics of queries and documents with the guidance of the taxonomy, and exploits their topical relatedness to supplement missing contexts. As a plug-and-play framework, ToTER can be flexibly employed to enhance various PLM-based retrievers. Through extensive quantitative, ablative, and exploratory experiments on two real-world datasets, we ascertain the benefits of using topical taxonomy for retrieval in theme-specific applications and demonstrate the effectiveness of ToTER.
KoDialogBench: Evaluating Conversational Understanding of Language Models with Korean Dialogue Benchmark
Feb 27, 2024As language models are often deployed as chatbot assistants, it becomes a virtue for models to engage in conversations in a user's first language. While these models are trained on a wide range of languages, a comprehensive evaluation of their proficiency in low-resource languages such as Korean has been lacking. In this work, we introduce KoDialogBench, a benchmark designed to assess language models' conversational capabilities in Korean. To this end, we collect native Korean dialogues on daily topics from public sources, or translate dialogues from other languages. We then structure these conversations into diverse test datasets, spanning from dialogue comprehension to response selection tasks. Leveraging the proposed benchmark, we conduct extensive evaluations and analyses of various language models to measure a foundational understanding of Korean dialogues. Experimental results indicate that there exists significant room for improvement in models' conversation skills. Furthermore, our in-depth comparisons across different language models highlight the effectiveness of recent training techniques in enhancing conversational proficiency. We anticipate that KoDialogBench will promote the progress towards conversation-aware Korean language models.
Doubly Calibrated Estimator for Recommendation on Data Missing Not At Random
Feb 26, 2024Recommender systems often suffer from selection bias as users tend to rate their preferred items. The datasets collected under such conditions exhibit entries missing not at random and thus are not randomized-controlled trials representing the target population. To address this challenge, a doubly robust estimator and its enhanced variants have been proposed as they ensure unbiasedness when accurate imputed errors or predicted propensities are provided. However, we argue that existing estimators rely on miscalibrated imputed errors and propensity scores as they depend on rudimentary models for estimation. We provide theoretical insights into how miscalibrated imputation and propensity models may limit the effectiveness of doubly robust estimators and validate our theorems using real-world datasets. On this basis, we propose a Doubly Calibrated Estimator that involves the calibration of both the imputation and propensity models. To achieve this, we introduce calibration experts that consider different logit distributions across users. Moreover, we devise a tri-level joint learning framework, allowing the simultaneous optimization of calibration experts alongside prediction and imputation models. Through extensive experiments on real-world datasets, we demonstrate the superiority of the Doubly Calibrated Estimator in the context of debiased recommendation tasks.
Deep Rating Elicitation for New Users in Collaborative Filtering
Feb 26, 2024



Recent recommender systems started to use rating elicitation, which asks new users to rate a small seed itemset for inferring their preferences, to improve the quality of initial recommendations. The key challenge of the rating elicitation is to choose the seed items which can best infer the new users' preference. This paper proposes a novel end-to-end Deep learning framework for Rating Elicitation (DRE), that chooses all the seed items at a time with consideration of the non-linear interactions. To this end, it first defines categorical distributions to sample seed items from the entire itemset, then it trains both the categorical distributions and a neural reconstruction network to infer users' preferences on the remaining items from CF information of the sampled seed items. Through the end-to-end training, the categorical distributions are learned to select the most representative seed items while reflecting the complex non-linear interactions. Experimental results show that DRE outperforms the state-of-the-art approaches in the recommendation quality by accurately inferring the new users' preferences and its seed itemset better represents the latent space than the seed itemset obtained by the other methods.
Top-Personalized-K Recommendation
Feb 26, 2024The conventional top-K recommendation, which presents the top-K items with the highest ranking scores, is a common practice for generating personalized ranking lists. However, is this fixed-size top-K recommendation the optimal approach for every user's satisfaction? Not necessarily. We point out that providing fixed-size recommendations without taking into account user utility can be suboptimal, as it may unavoidably include irrelevant items or limit the exposure to relevant ones. To address this issue, we introduce Top-Personalized-K Recommendation, a new recommendation task aimed at generating a personalized-sized ranking list to maximize individual user satisfaction. As a solution to the proposed task, we develop a model-agnostic framework named PerK. PerK estimates the expected user utility by leveraging calibrated interaction probabilities, subsequently selecting the recommendation size that maximizes this expected utility. Through extensive experiments on real-world datasets, we demonstrate the superiority of PerK in Top-Personalized-K recommendation task. We expect that Top-Personalized-K recommendation has the potential to offer enhanced solutions for various real-world recommendation scenarios, based on its great compatibility with existing models.