 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIBAC: Towards Robust and Imperceptible Backdoor Attack against Compact DNN
Aug 22, 2022
Recently backdoor attack has become an emerging threat to the security of deep neural network (DNN) models. To date, most of the existing studies focus on backdoor attack against the uncompressed model; while the vulnerability of compressed DNNs, which are widely used in the practical applications, is little exploited yet. In this paper, we propose to study and develop Robust and Imperceptible Backdoor Attack against Compact DNN models (RIBAC). By performing systematic analysis and exploration on the important design knobs, we propose a framework that can learn the proper trigger patterns, model parameters and pruning masks in an efficient way. Thereby achieving high trigger stealthiness, high attack success rate and high model efficiency simultaneously. Extensive evaluations across different datasets, including the test against the state-of-the-art defense mechanisms, demonstrate the high robustness, stealthiness and model efficiency of RIBAC. Code is available at https://github.com/huyvnphan/ECCV2022-RIBAC
* Code is available at https://github.com/huyvnphan/ECCV2022-RIBAC
Polyphonic audio event detection: multi-label or multi-class multi-task classification problem?
Jan 29, 2022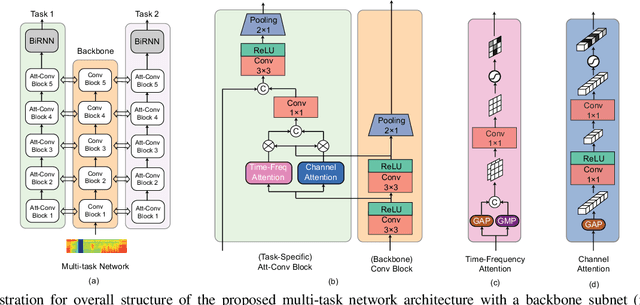
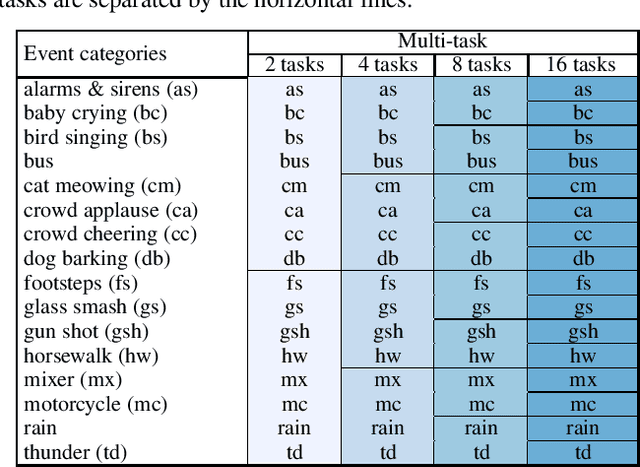
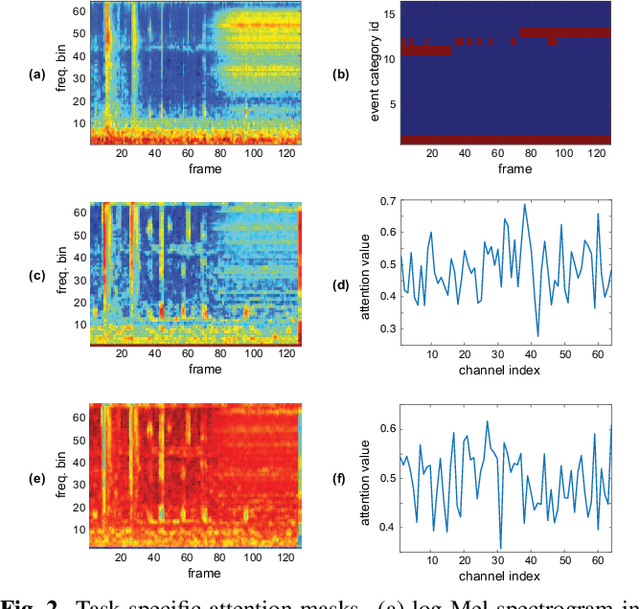
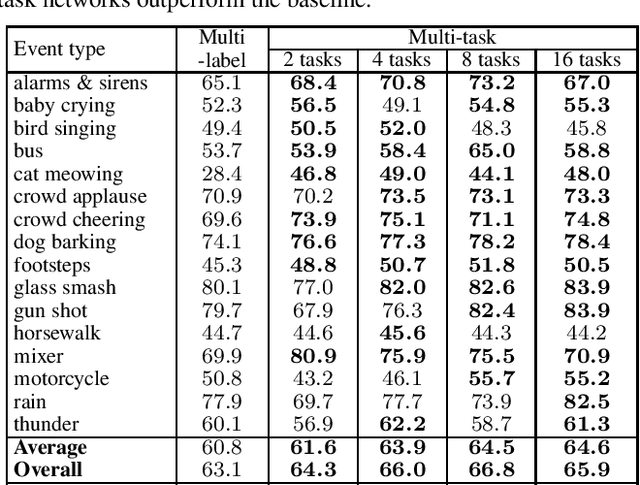
Polyphonic events are the main error source of audio event detection (AED) systems. In deep-learning context, the most common approach to deal with event overlaps is to treat the AED task as a multi-label classification problem. By doing this, we inherently consider multiple one-vs.-rest classification problems, which are jointly solved by a single (i.e. shared) network. In this work, to better handle polyphonic mixtures, we propose to frame the task as a multi-class classification problem by considering each possible label combination as one class. To circumvent the large number of arising classes due to combinatorial explosion, we divide the event categories into multiple groups and construct a multi-task problem in a divide-and-conquer fashion, where each of the tasks is a multi-class classification problem. A network architecture is then devised for multi-class multi-task modelling. The network is composed of a backbone subnet and multiple task-specific subnets. The task-specific subnets are designed to learn time-frequency and channel attention masks to extract features for the task at hand from the common feature maps learned by the backbone. Experiments on the TUT-SED-Synthetic-2016 with high degree of event overlap show that the proposed approach results in more favorable performance than the common multi-label approach.
Feature matching as improved transfer learning technique for wearable EEG
Dec 29, 2021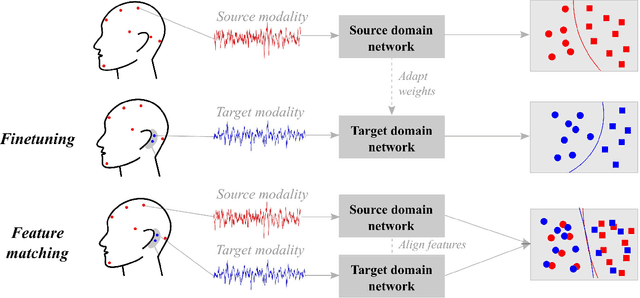
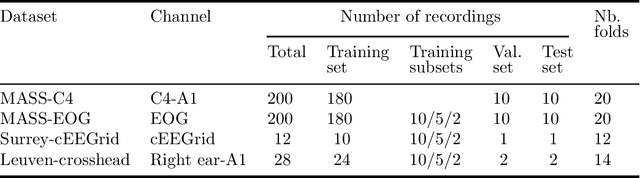
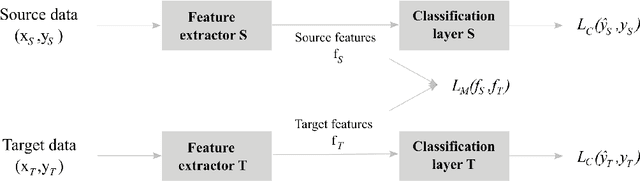
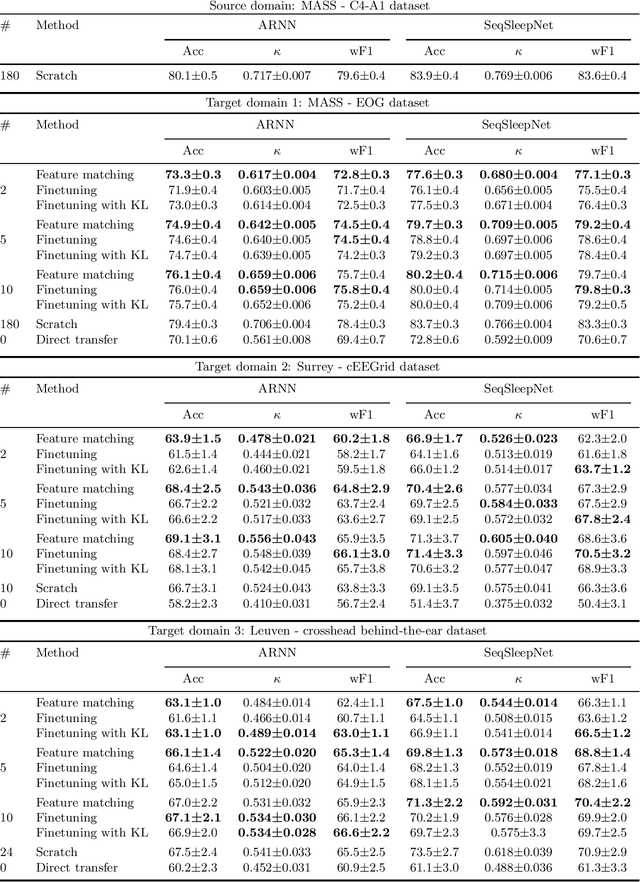
Objective: With the rapid rise of wearable sleep monitoring devices with non-conventional electrode configurations, there is a need for automated algorithms that can perform sleep staging on configurations with small amounts of labeled data. Transfer learning has the ability to adapt neural network weights from a source modality (e.g. standard electrode configuration) to a new target modality (e.g. non-conventional electrode configuration). Methods: We propose feature matching, a new transfer learning strategy as an alternative to the commonly used finetuning approach. This method consists of training a model with larger amounts of data from the source modality and few paired samples of source and target modality. For those paired samples, the model extracts features of the target modality, matching these to the features from the corresponding samples of the source modality. Results: We compare feature matching to finetuning for three different target domains, with two different neural network architectures, and with varying amounts of training data. Particularly on small cohorts (i.e. 2 - 5 labeled recordings in the non-conventional recording setting), feature matching systematically outperforms finetuning with mean relative differences in accuracy ranging from 0.4% to 4.7% for the different scenarios and datasets. Conclusion: Our findings suggest that feature matching outperforms finetuning as a transfer learning approach, especially in very low data regimes. Significance: As such, we conclude that feature matching is a promising new method for wearable sleep staging with novel devices.
SALSA-Lite: A Fast and Effective Feature for Polyphonic Sound Event Localization and Detection with Microphone Arrays
Nov 16, 2021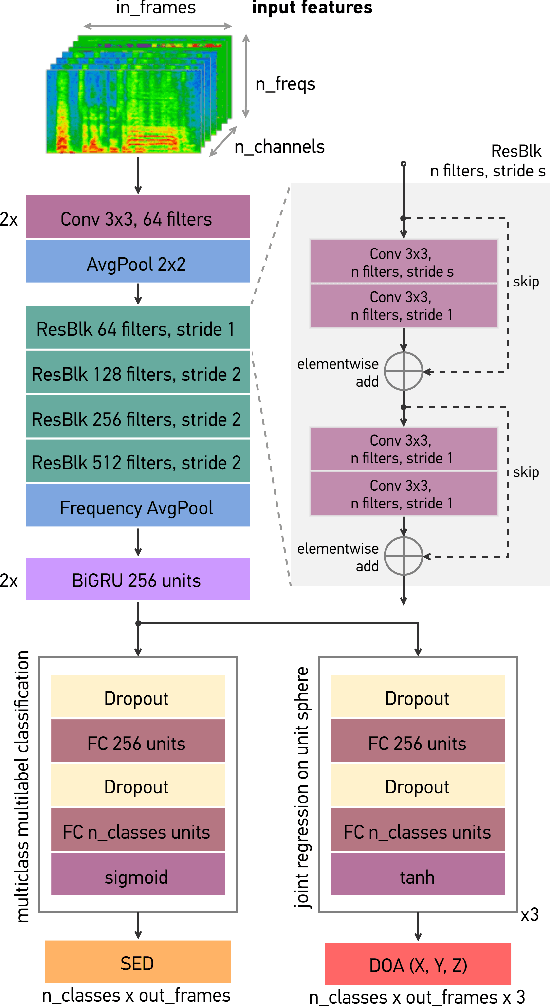
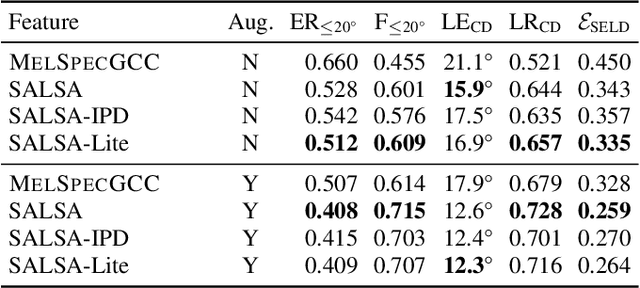
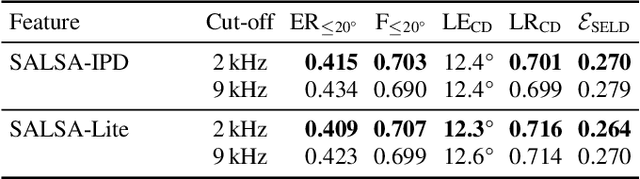
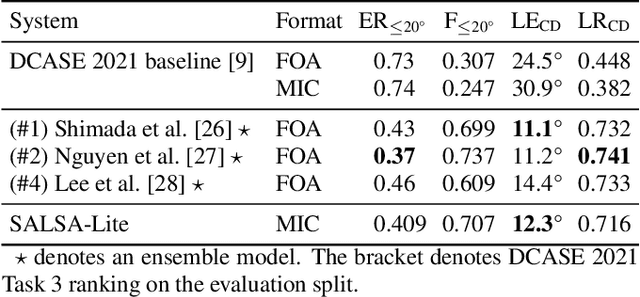
Polyphonic sound event localization and detection (SELD) has many practical applications in acoustic sensing and monitoring. However, the development of real-time SELD has been limited by the demanding computational requirement of most recent SELD systems. In this work, we introduce SALSA-Lite, a fast and effective feature for polyphonic SELD using microphone array inputs. SALSA-Lite is a lightweight variation of a previously proposed SALSA feature for polyphonic SELD. SALSA, which stands for Spatial Cue-Augmented Log-Spectrogram, consists of multichannel log-spectrograms stacked channelwise with the normalized principal eigenvectors of the spectrotemporally corresponding spatial covariance matrices. In contrast to SALSA, which uses eigenvector-based spatial features, SALSA-Lite uses normalized inter-channel phase differences as spatial features, allowing a 30-fold speedup compared to the original SALSA feature. Experimental results on the TAU-NIGENS Spatial Sound Events 2021 dataset showed that the SALSA-Lite feature achieved competitive performance compared to the full SALSA feature, and significantly outperformed the traditional feature set of multichannel log-mel spectrograms with generalized cross-correlation spectra. Specifically, using SALSA-Lite features increased localization-dependent F1 score and class-dependent localization recall by 15% and 5%, respectively, compared to using multichannel log-mel spectrograms with generalized cross-correlation spectra.
Automatic Sleep Staging: Recent Development, Challenges, and Future Directions
Nov 03, 2021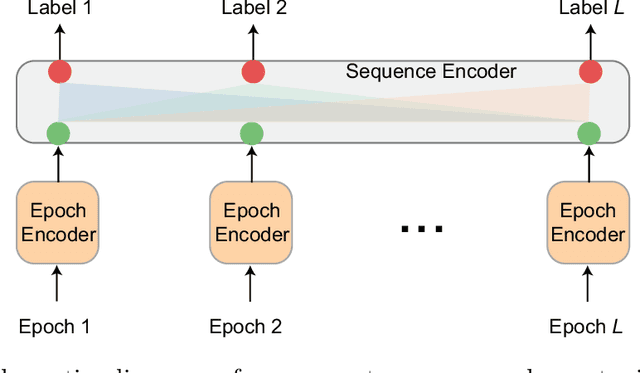
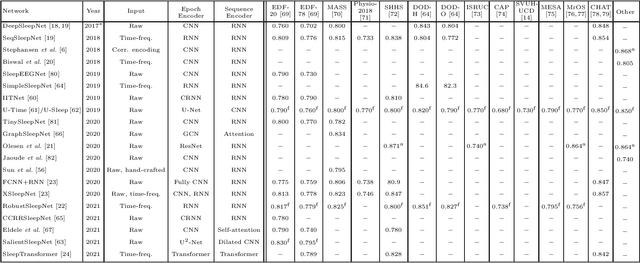
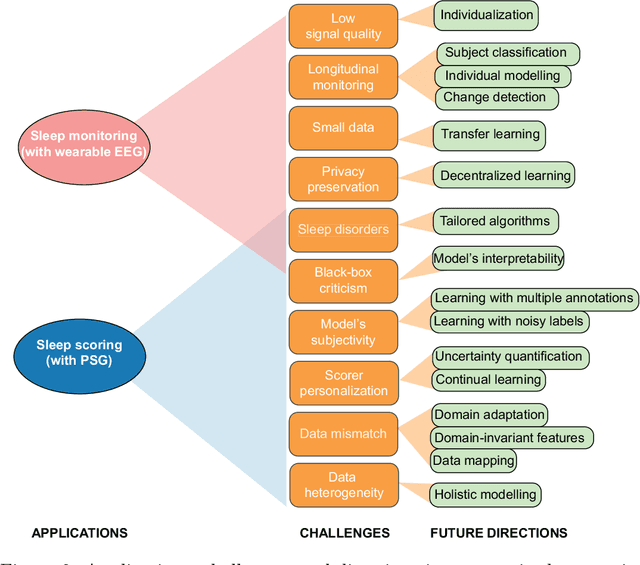
Modern deep learning holds a great potential to transform clinical practice on human sleep. Teaching a machine to carry out routine tasks would be a tremendous reduction in workload for clinicians. Sleep staging, a fundamental step in sleep practice, is a suitable task for this and will be the focus in this article. Recently, automatic sleep staging systems have been trained to mimic manual scoring, leading to similar performance to human sleep experts, at least on scoring of healthy subjects. Despite tremendous progress, we have not seen automatic sleep scoring adopted widely in clinical environments. This review aims to give a shared view of the authors on the most recent state-of-the-art development in automatic sleep staging, the challenges that still need to be addressed, and the future directions for automatic sleep scoring to achieve clinical value.
CHIP: CHannel Independence-based Pruning for Compact Neural Networks
Oct 26, 2021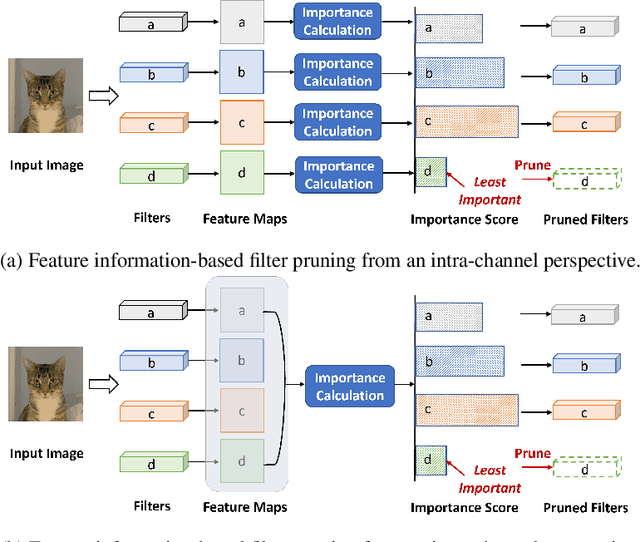
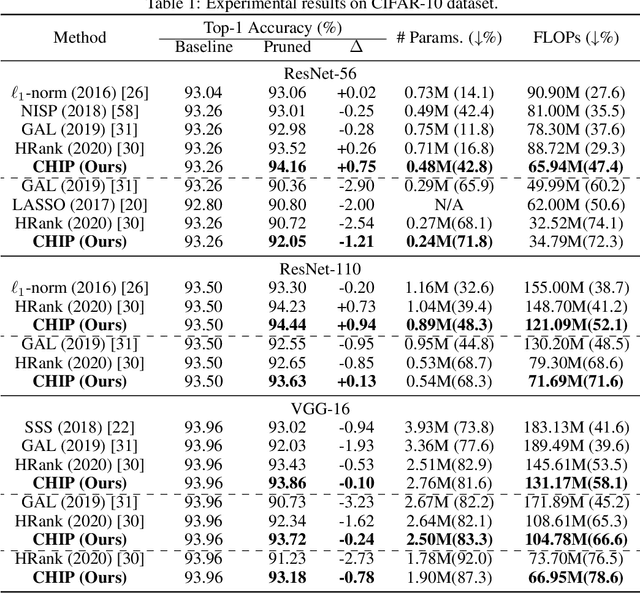
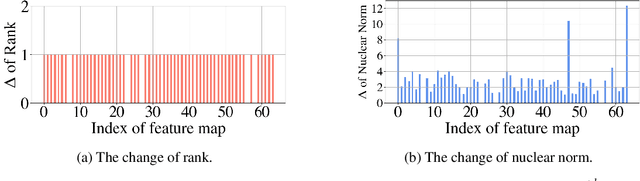
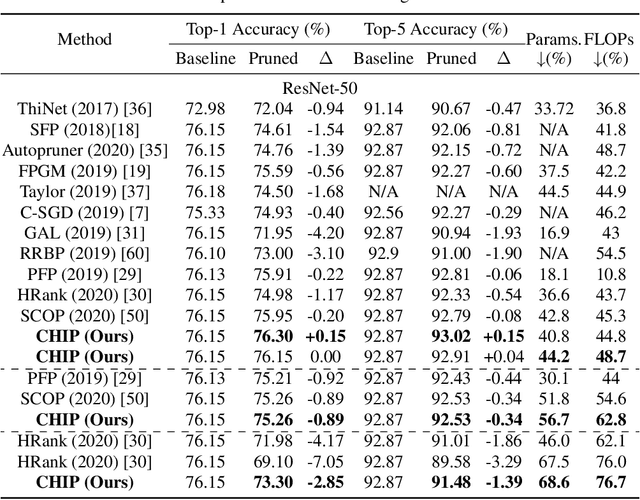
Filter pruning has been widely used for neural network compression because of its enabled practical acceleration. To date, most of the existing filter pruning works explore the importance of filters via using intra-channel information. In this paper, starting from an inter-channel perspective, we propose to perform efficient filter pruning using Channel Independence, a metric that measures the correlations among different feature maps. The less independent feature map is interpreted as containing less useful information$/$knowledge, and hence its corresponding filter can be pruned without affecting model capacity. We systematically investigate the quantification metric, measuring scheme and sensitiveness$/$reliability of channel independence in the context of filter pruning. Our evaluation results for different models on various datasets show the superior performance of our approach. Notably, on CIFAR-10 dataset our solution can bring $0.75\%$ and $0.94\%$ accuracy increase over baseline ResNet-56 and ResNet-110 models, respectively, and meanwhile the model size and FLOPs are reduced by $42.8\%$ and $47.4\%$ (for ResNet-56) and $48.3\%$ and $52.1\%$ (for ResNet-110), respectively. On ImageNet dataset, our approach can achieve $40.8\%$ and $44.8\%$ storage and computation reductions, respectively, with $0.15\%$ accuracy increase over the baseline ResNet-50 model. The code is available at https://github.com/Eclipsess/CHIP_NeurIPS2021.
Neural Synthesis of Footsteps Sound Effects with Generative Adversarial Networks
Oct 18, 2021

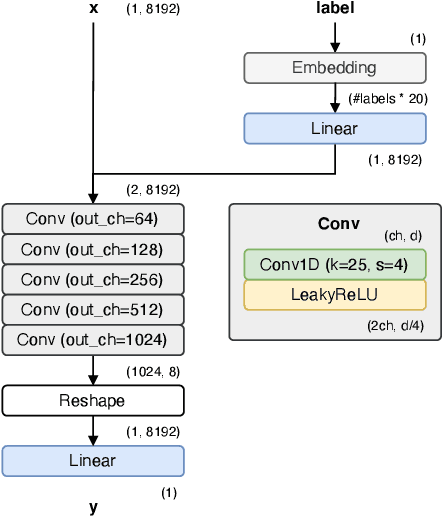
Footsteps are among the most ubiquitous sound effects in multimedia applications. There is substantial research into understanding the acoustic features and developing synthesis models for footstep sound effects. In this paper, we present a first attempt at adopting neural synthesis for this task. We implemented two GAN-based architectures and compared the results with real recordings as well as six traditional sound synthesis methods. Our architectures reached realism scores as high as recorded samples, showing encouraging results for the task at hand.
Pediatric Automatic Sleep Staging: A comparative study of state-of-the-art deep learning methods
Aug 23, 2021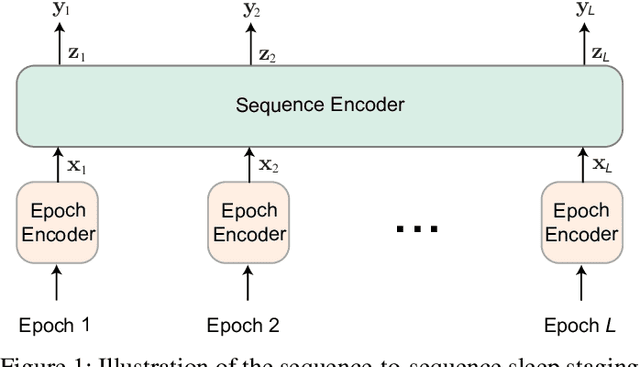
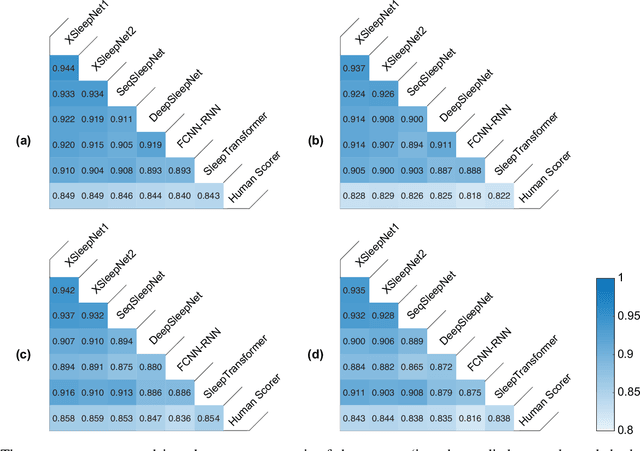
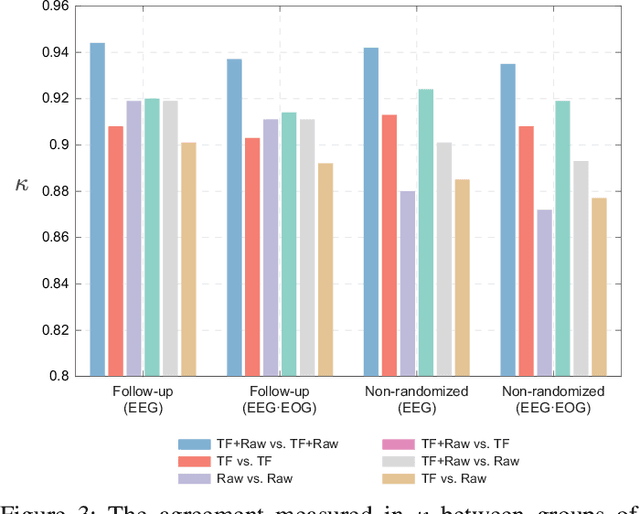
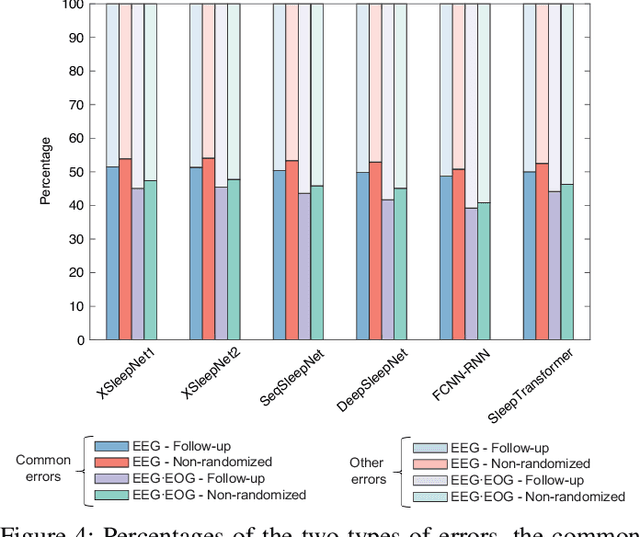
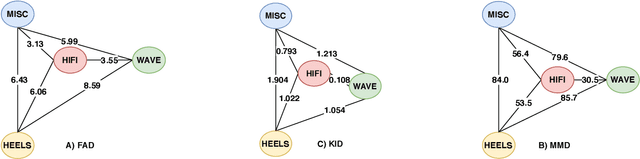
Despite the tremendous progress recently made towards automatic sleep staging in adults, it is currently known if the most advanced algorithms generalize to the pediatric population, which displays distinctive characteristics in overnight polysomnography (PSG). To answer the question, in this work, we conduct a large-scale comparative study on the state-of-the-art deep learning methods for pediatric automatic sleep staging. A selection of six different deep neural networks with diverging features are adopted to evaluate a sample of more than 1,200 children across a wide spectrum of obstructive sleep apnea (OSA) severity. Our experimental results show that the performance of automated pediatric sleep staging when evaluated on new subjects is equivalent to the expert-level one reported on adults, reaching an overall accuracy of 87.0%, a Cohen's kappa of 0.829, and a macro F1-score of 83.5% in case of single-channel EEG. The performance is further improved when dual-channel EEG$\cdot$EOG are used, reaching an accuracy of 88.2%, a Cohen's kappa of 0.844, and a macro F1-score of 85.1%. The results also show that the studied algorithms are robust to concept drift when the training and test data were recorded 7-months apart. Detailed analyses further demonstrate "almost perfect" agreement between the automatic scorers to one another and their similar behavioral patterns on the staging errors.
SleepTransformer: Automatic Sleep Staging with Interpretability and Uncertainty Quantification
May 23, 2021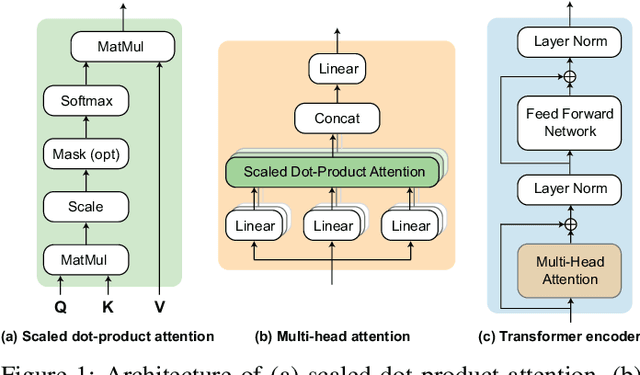
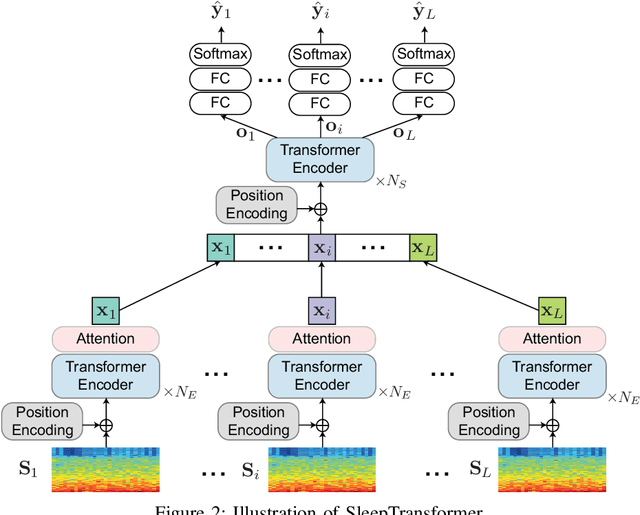
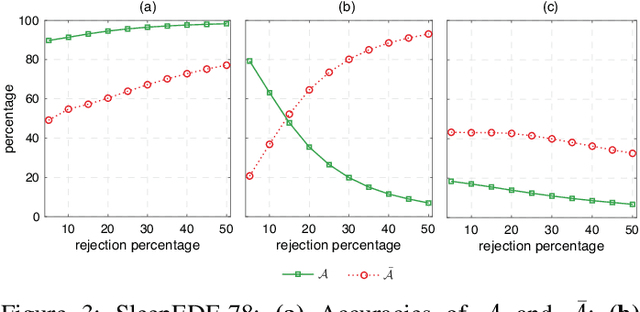
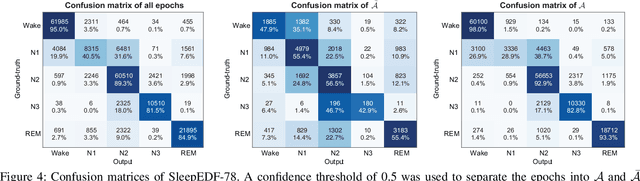
Black-box skepticism is one of the main hindrances impeding deep-learning-based automatic sleep scoring from being used in clinical environments. Towards interpretability, this work proposes a sequence-to-sequence sleep-staging model, namely SleepTransformer. It is based on the transformer backbone whose self-attention scores offer interpretability of the model's decisions at both the epoch and sequence level. At the epoch level, the attention scores can be encoded as a heat map to highlight sleep-relevant features captured from the input EEG signal. At the sequence level, the attention scores are visualized as the influence of different neighboring epochs in an input sequence (i.e. the context) to recognition of a target epoch, mimicking the way manual scoring is done by human experts. We further propose a simple yet efficient method to quantify uncertainty in the model's decisions. The method, which is based on entropy, can serve as a metric for deferring low-confidence epochs to a human expert for further inspection. Additionally, we demonstrate that the proposed SleepTransformer outperforms existing methods at a lower computational cost and achieves state-of-the-art performance on two experimental databases of different sizes.
Multi-view Audio and Music Classification
Mar 03, 2021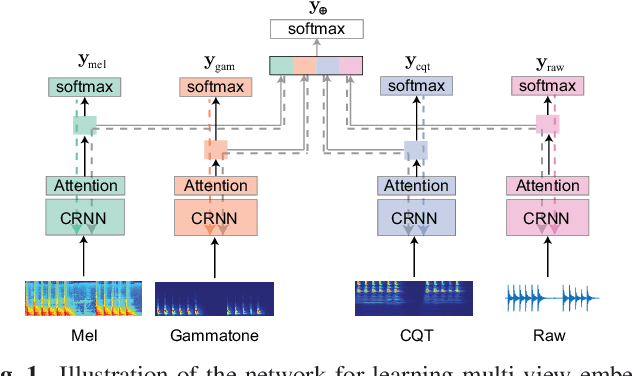
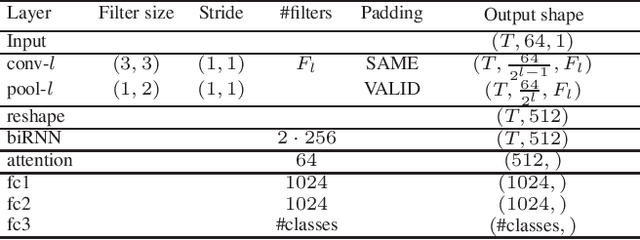
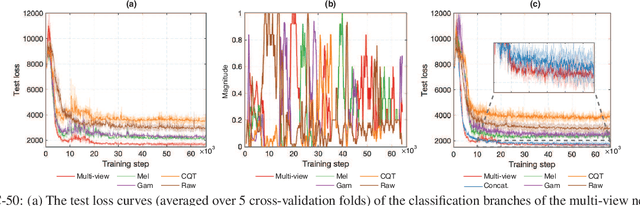
We propose in this work a multi-view learning approach for audio and music classification. Considering four typical low-level representations (i.e. different views) commonly used for audio and music recognition tasks, the proposed multi-view network consists of four subnetworks, each handling one input types. The learned embedding in the subnetworks are then concatenated to form the multi-view embedding for classification similar to a simple concatenation network. However, apart from the joint classification branch, the network also maintains four classification branches on the single-view embedding of the subnetworks. A novel method is then proposed to keep track of the learning behavior on the classification branches and adapt their weights to proportionally blend their gradients for network training. The weights are adapted in such a way that learning on a branch that is generalizing well will be encouraged whereas learning on a branch that is overfitting will be slowed down. Experiments on three different audio and music classification tasks show that the proposed multi-view network not only outperforms the single-view baselines but also is superior to the multi-view baselines based on concatenation and late fusion.