 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Positional Leakage in 3D Masked Autoencoders for Robust Representation Learning
Jun 30, 2026Masked autoencoding has emerged as a prominent paradigm for self-supervised learning on 3D point clouds, achieving competitive performance across downstream tasks. Unlike its 2D counterpart, 3D masked autoencoding directly reconstructs spatial coordinates, making it inherently susceptible to positional leakage. In this work, we identify that the decoder in existing 3D MAE frameworks tends to over-rely on positional information, which weakens semantic representation learning and leads to suboptimal feature quality. To address this issue, we propose MPL-MAE, a masked point learning framework that mitigates positional over-reliance while enhancing the utilization of encoder features. Specifically, we introduce a recalibrated positional embedding module that suppresses metric-dominant coordinate signals while preserving geometric topology, together with a gated positional interface module that dynamically regulates positional injection during reconstruction. These designs promote a more balanced interaction between spatial priors and semantic features, yielding robust and informative representations. Extensive experiments across downstream tasks demonstrate that MPL-MAE consistently achieves competitive performance, validating its effectiveness. Code is available at https://github.com/yanx57/MPL-MAE.
EgoMind: Activating Spatial Cognition through Linguistic Reasoning in MLLMs
Apr 01, 2026Multimodal large language models (MLLMs) are increasingly being applied to spatial cognition tasks, where they are expected to understand and interact with complex environments. Most existing works improve spatial reasoning by introducing 3D priors or geometric supervision, which enhances performance but incurs substantial data preparation and alignment costs. In contrast, purely 2D approaches often struggle with multi-frame spatial reasoning due to their limited ability to capture cross-frame spatial relationships. To address these limitations, we propose EgoMind, a Chain-of-Thought framework that enables geometry-free spatial reasoning through Role-Play Caption, which jointly constructs a coherent linguistic scene graph across frames, and Progressive Spatial Analysis, which progressively reasons toward task-specific questions. With only 5K auto-generated SFT samples and 20K RL samples, EgoMind achieves competitive results on VSI-Bench, SPAR-Bench, SITE-Bench, and SPBench, demonstrating its effectiveness in strengthening the spatial reasoning capabilities of MLLMs and highlighting the potential of linguistic reasoning for spatial cognition. Code and data are released at https://github.com/Hyggge/EgoMind.
CoVFT: Context-aware Visual Fine-tuning for Multimodal Large Language Models
Mar 22, 2026Multimodal large language models (MLLMs) achieve remarkable progress in cross-modal perception and reasoning, yet a fundamental question remains unresolved: should the vision encoder be fine-tuned or frozen? Despite the success of models such as LLaVA and Qwen-VL, inconsistent design choices and heterogeneous training setups hinder a unified understanding of visual fine-tuning (VFT) in MLLMs. Through a configuration-aligned benchmark, we find that existing VFT methods fail to consistently outperform the frozen baseline across multimodal tasks. Our analysis suggests that this instability arises from visual preference conflicts, where the context-agnostic nature of vision encoders induces divergent parameter updates under diverse multimodal context. To address this issue, we propose the Context-aware Visual Fine-tuning (CoVFT) framework, which explicitly incorporates multimodal context into visual adaptation. By integrating a Context Vector Extraction (CVE) and a Contextual Mixture-of-Experts (CoMoE) module, CoVFT decomposes conflicting optimization signals and enables stable, context-sensitive visual updates. Extensive experiments on 12 multimodal benchmarks demonstrate that CoVFT achieves state-of-the-art performance with superior stability. Notably, fine-tuning a 7B MLLM with CoVFT surpasses the average performance of its 13B counterpart, revealing substantial untapped potential in visual encoder optimization within MLLMs.
Multi-modal Relation Distillation for Unified 3D Representation Learning
Jul 19, 2024



Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning heterogeneous features across 3D shapes and their corresponding 2D images and language descriptions. However, current straightforward solutions often overlook intricate structural relations among samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pre-training framework, which is designed to effectively distill reputable large Vision-Language Models (VLM) into 3D backbones. MRD aims to capture both intra-relations within each modality as well as cross-relations between different modalities and produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering new state-of-the-art performance.
iDARTS: Improving DARTS by Node Normalization and Decorrelation Discretization
Aug 25, 2021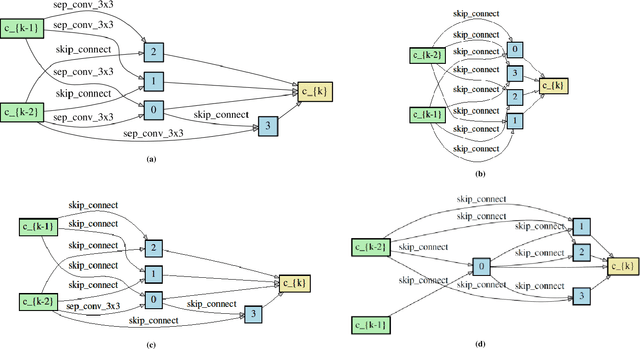

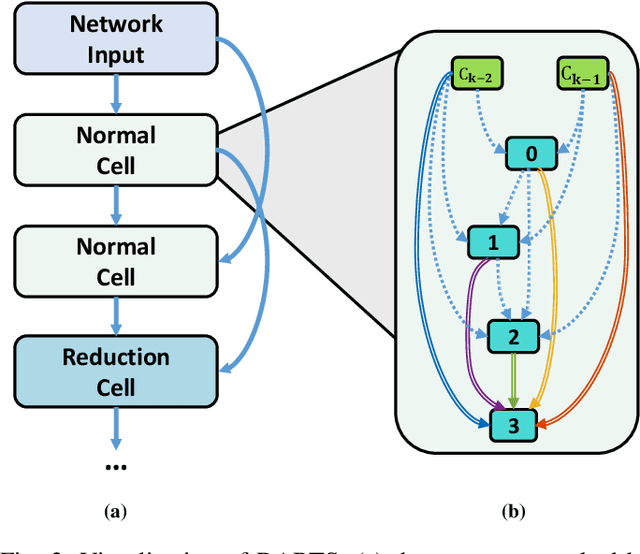
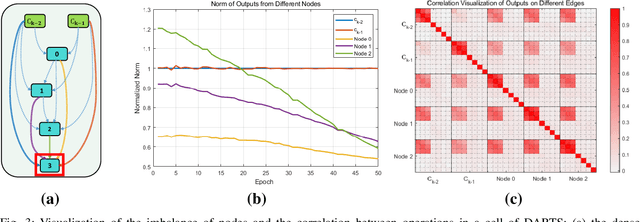
Differentiable ARchiTecture Search (DARTS) uses a continuous relaxation of network representation and dramatically accelerates Neural Architecture Search (NAS) by almost thousands of times in GPU-day. However, the searching process of DARTS is unstable, which suffers severe degradation when training epochs become large, thus limiting its application. In this paper, we claim that this degradation issue is caused by the imbalanced norms between different nodes and the highly correlated outputs from various operations. We then propose an improved version of DARTS, namely iDARTS, to deal with the two problems. In the training phase, it introduces node normalization to maintain the norm balance. In the discretization phase, the continuous architecture is approximated based on the similarity between the outputs of the node and the decorrelated operations rather than the values of the architecture parameters. Extensive evaluation is conducted on CIFAR-10 and ImageNet, and the error rates of 2.25\% and 24.7\% are reported within 0.2 and 1.9 GPU-day for architecture search respectively, which shows its effectiveness. Additional analysis also reveals that iDARTS has the advantage in robustness and generalization over other DARTS-based counterparts.
PR-GCN: A Deep Graph Convolutional Network with Point Refinement for 6D Pose Estimation
Aug 23, 2021
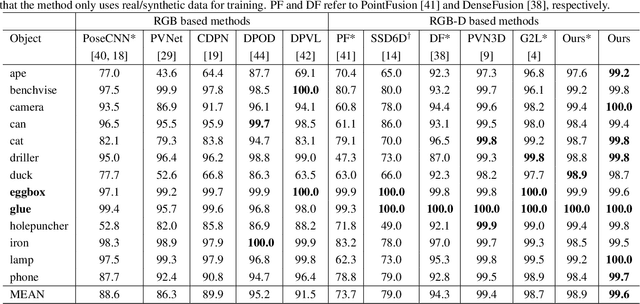
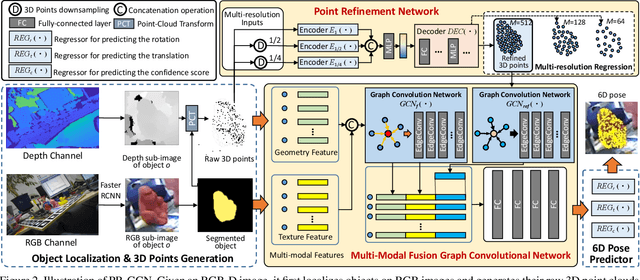
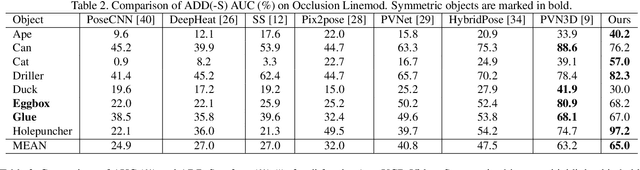
RGB-D based 6D pose estimation has recently achieved remarkable progress, but still suffers from two major limitations: (1) ineffective representation of depth data and (2) insufficient integration of different modalities. This paper proposes a novel deep learning approach, namely Graph Convolutional Network with Point Refinement (PR-GCN), to simultaneously address the issues above in a unified way. It first introduces the Point Refinement Network (PRN) to polish 3D point clouds, recovering missing parts with noise removed. Subsequently, the Multi-Modal Fusion Graph Convolutional Network (MMF-GCN) is presented to strengthen RGB-D combination, which captures geometry-aware inter-modality correlation through local information propagation in the graph convolutional network. Extensive experiments are conducted on three widely used benchmarks, and state-of-the-art performance is reached. Besides, it is also shown that the proposed PRN and MMF-GCN modules are well generalized to other frameworks.