 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVFT: Context-aware Visual Fine-tuning for Multimodal Large Language Models
Mar 22, 2026Multimodal large language models (MLLMs) achieve remarkable progress in cross-modal perception and reasoning, yet a fundamental question remains unresolved: should the vision encoder be fine-tuned or frozen? Despite the success of models such as LLaVA and Qwen-VL, inconsistent design choices and heterogeneous training setups hinder a unified understanding of visual fine-tuning (VFT) in MLLMs. Through a configuration-aligned benchmark, we find that existing VFT methods fail to consistently outperform the frozen baseline across multimodal tasks. Our analysis suggests that this instability arises from visual preference conflicts, where the context-agnostic nature of vision encoders induces divergent parameter updates under diverse multimodal context. To address this issue, we propose the Context-aware Visual Fine-tuning (CoVFT) framework, which explicitly incorporates multimodal context into visual adaptation. By integrating a Context Vector Extraction (CVE) and a Contextual Mixture-of-Experts (CoMoE) module, CoVFT decomposes conflicting optimization signals and enables stable, context-sensitive visual updates. Extensive experiments on 12 multimodal benchmarks demonstrate that CoVFT achieves state-of-the-art performance with superior stability. Notably, fine-tuning a 7B MLLM with CoVFT surpasses the average performance of its 13B counterpart, revealing substantial untapped potential in visual encoder optimization within MLLMs.
A multimodal vision foundation model for generalizable knee pathology
Jan 26, 2026Musculoskeletal disorders represent a leading cause of global disability, creating an urgent demand for precise interpretation of medical imaging. Current artificial intelligence (AI) approaches in orthopedics predominantly rely on task-specific, supervised learning paradigms. These methods are inherently fragmented, require extensive annotated datasets, and often lack generalizability across different modalities and clinical scenarios. The development of foundation models in this field has been constrained by the scarcity of large-scale, curated, and open-source musculoskeletal datasets. To address these challenges, we introduce OrthoFoundation, a multimodal vision foundation model optimized for musculoskeletal pathology. We constructed a pre-training dataset of 1.2 million unlabeled knee X-ray and MRI images from internal and public databases. Utilizing a Dinov3 backbone, the model was trained via self-supervised contrastive learning to capture robust radiological representations. OrthoFoundation achieves state-of-the-art (SOTA) performance across 14 downstream tasks. It attained superior accuracy in X-ray osteoarthritis diagnosis and ranked first in MRI structural injury detection. The model demonstrated remarkable label efficiency, matching supervised baselines using only 50% of labeled data. Furthermore, despite being pre-trained on knee images, OrthoFoundation exhibited exceptional cross-anatomy generalization to the hip, shoulder, and ankle. OrthoFoundation represents a significant advancement toward general-purpose AI for musculoskeletal imaging. By learning fundamental, joint-agnostic radiological semantics from large-scale multimodal data, it overcomes the limitations of conventional models, which provides a robust framework for reducing annotation burdens and enhancing diagnostic accuracy in clinical practice.
Crowd-SAM: SAM as a Smart Annotator for Object Detection in Crowded Scenes
Jul 16, 2024



In computer vision, object detection is an important task that finds its application in many scenarios. However, obtaining extensive labels can be challenging, especially in crowded scenes. Recently, the Segment Anything Model (SAM) has been proposed as a powerful zero-shot segmenter, offering a novel approach to instance segmentation tasks. However, the accuracy and efficiency of SAM and its variants are often compromised when handling objects in crowded and occluded scenes. In this paper, we introduce Crowd-SAM, a SAM-based framework designed to enhance SAM's performance in crowded and occluded scenes with the cost of few learnable parameters and minimal labeled images. We introduce an efficient prompt sampler (EPS) and a part-whole discrimination network (PWD-Net), enhancing mask selection and accuracy in crowded scenes. Despite its simplicity, Crowd-SAM rivals state-of-the-art (SOTA) fully-supervised object detection methods on several benchmarks including CrowdHuman and CityPersons. Our code is available at https://github.com/FelixCaae/CrowdSAM.
Deep Common Feature Mining for Efficient Video Semantic Segmentation
Mar 05, 2024Recent advancements in video semantic segmentation have made substantial progress by exploiting temporal correlations. Nevertheless, persistent challenges, including redundant computation and the reliability of the feature propagation process, underscore the need for further innovation. In response, we present Deep Common Feature Mining (DCFM), a novel approach strategically designed to address these challenges by leveraging the concept of feature sharing. DCFM explicitly decomposes features into two complementary components. The common representation extracted from a key-frame furnishes essential high-level information to neighboring non-key frames, allowing for direct re-utilization without feature propagation. Simultaneously, the independent feature, derived from each video frame, captures rapidly changing information, providing frame-specific clues crucial for segmentation. To achieve such decomposition, we employ a symmetric training strategy tailored for sparsely annotated data, empowering the backbone to learn a robust high-level representation enriched with common information. Additionally, we incorporate a self-supervised loss function to reinforce intra-class feature similarity and enhance temporal consistency. Experimental evaluations on the VSPW and Cityscapes datasets demonstrate the effectiveness of our method, showing a superior balance between accuracy and efficiency.
Checkerboard Context Model for Efficient Learned Image Compression
Apr 01, 2021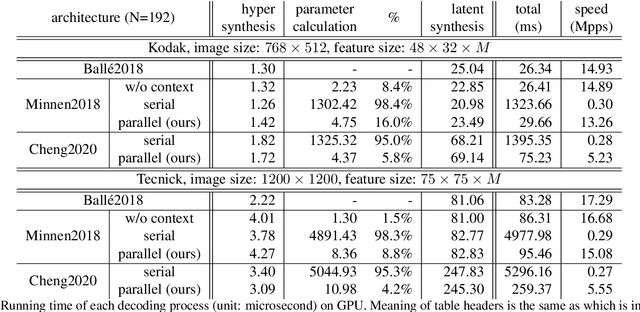

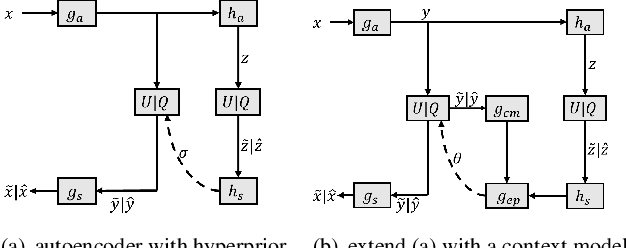

For learned image compression, the autoregressive context model is proved effective in improving the rate-distortion (RD) performance. Because it helps remove spatial redundancies among latent representations. However, the decoding process must be done in a strict scan order, which breaks the parallelization. We propose a parallelizable checkerboard context model (CCM) to solve the problem. Our two-pass checkerboard context calculation eliminates such limitations on spatial locations by re-organizing the decoding order. Speeding up the decoding process more than 40 times in our experiments, it achieves significantly improved computational efficiency with almost the same rate-distortion performance. To the best of our knowledge, this is the first exploration on parallelization-friendly spatial context model for learned image compression.