 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoLive: A Large-Scale Egocentric Dataset from Real-World Human Tasks
Apr 26, 2026The advancement of robot learning is currently hindered by the scarcity of large-scale, high-quality datasets. While established data collection methods such as teleoperation and universal manipulation interfaces dominate current datasets, they suffer from inherent limitations in scalability and real-world deployability. Human egocentric video collection, by contrast, has emerged as a promising approach to enable scalable, natural and in-the-wild data collection. As such, we present EgoLive, a large-scale, high-quality egocentric dataset designed explicitly for robot manipulation learning. EgoLive establishes three distinctive technical advantages over existing egocentric datasets: first, it represents the largest open-source annotated egocentric dataset focused on real-world task-oriented human routines to date; second, it delivers leading data quality via a customized head-mounted capture device and comprehensive high-precision multi-modal annotations; third, all data is collected exclusively in unconstrained real-world scenarios and encompasses vertical field human working data, including home service, retail, and other practical work scenarios, providing superior diversity and ecological validity. With the introduction of EgoLive, we aim to provide the research community with a scalable, high-quality dataset that accelerates breakthroughs in generalizable robotic models and facilitates the real-world deployment of robot systems.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
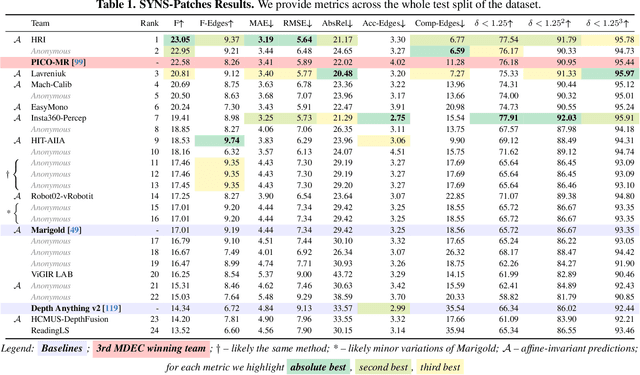
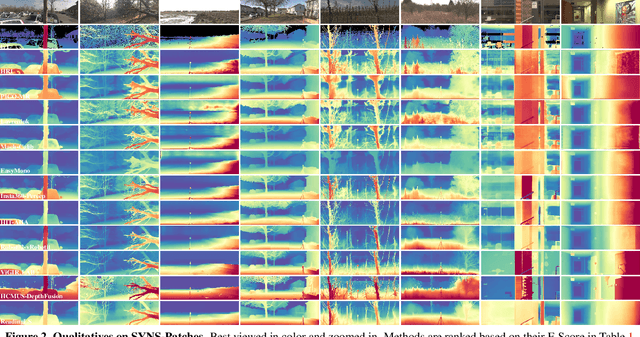
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
PR-GCN: A Deep Graph Convolutional Network with Point Refinement for 6D Pose Estimation
Aug 23, 2021
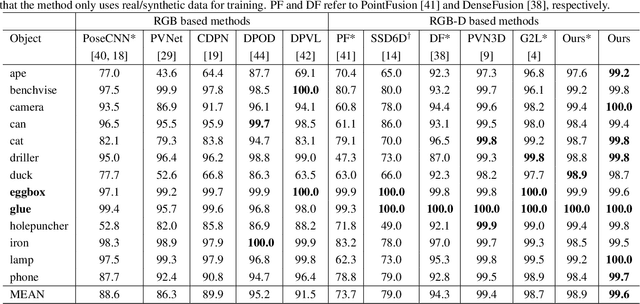
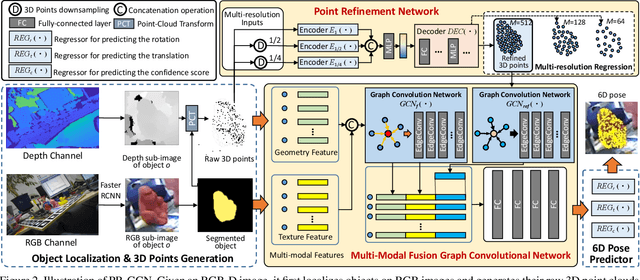
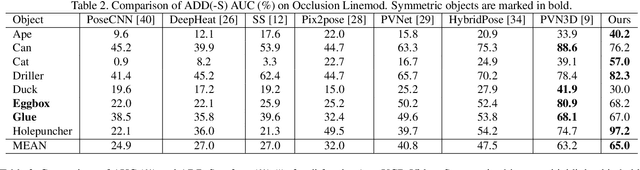
RGB-D based 6D pose estimation has recently achieved remarkable progress, but still suffers from two major limitations: (1) ineffective representation of depth data and (2) insufficient integration of different modalities. This paper proposes a novel deep learning approach, namely Graph Convolutional Network with Point Refinement (PR-GCN), to simultaneously address the issues above in a unified way. It first introduces the Point Refinement Network (PRN) to polish 3D point clouds, recovering missing parts with noise removed. Subsequently, the Multi-Modal Fusion Graph Convolutional Network (MMF-GCN) is presented to strengthen RGB-D combination, which captures geometry-aware inter-modality correlation through local information propagation in the graph convolutional network. Extensive experiments are conducted on three widely used benchmarks, and state-of-the-art performance is reached. Besides, it is also shown that the proposed PRN and MMF-GCN modules are well generalized to other frameworks.