 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional FDR Control for Sub-Gaussian Sparse GLMs
May 02, 2021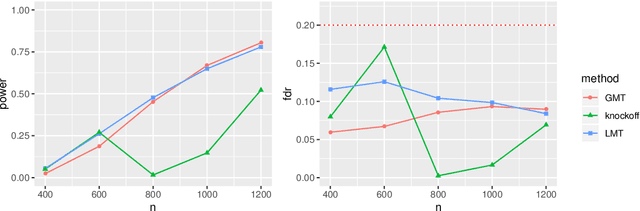
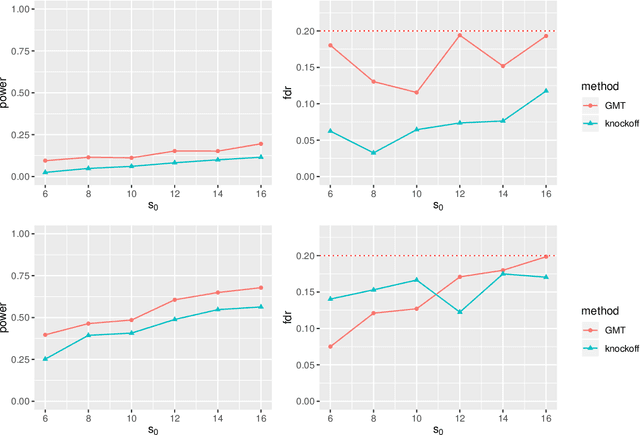
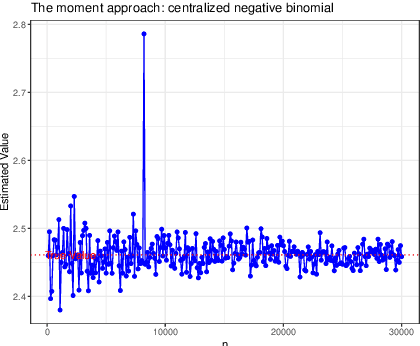
High-dimensional sparse generalized linear models (GLMs) have emerged in the setting that the number of samples and the dimension of variables are large, and even the dimension of variables grows faster than the number of samples. False discovery rate (FDR) control aims to identify some small number of statistically significantly nonzero results after getting the sparse penalized estimation of GLMs. Using the CLIME method for precision matrix estimations, we construct the debiased-Lasso estimator and prove the asymptotical normality by minimax-rate oracle inequalities for sparse GLMs. In practice, it is often needed to accurately judge each regression coefficient's positivity and negativity, which determines whether the predictor variable is positively or negatively related to the response variable conditionally on the rest variables. Using the debiased estimator, we establish multiple testing procedures. Under mild conditions, we show that the proposed debiased statistics can asymptotically control the directional (sign) FDR and directional false discovery variables at a pre-specified significance level. Moreover, it can be shown that our multiple testing procedure can approximately achieve a statistical power of 1. We also extend our methods to the two-sample problems and propose the two-sample test statistics. Under suitable conditions, we can asymptotically achieve directional FDR control and directional FDV control at the specified significance level for two-sample problems. Some numerical simulations have successfully verified the FDR control effects of our proposed testing procedures, which sometimes outperforms the classical knockoff method.
Sharper Sub-Weibull Concentrations: Non-asymptotic Bai-Yin Theorem
Feb 12, 2021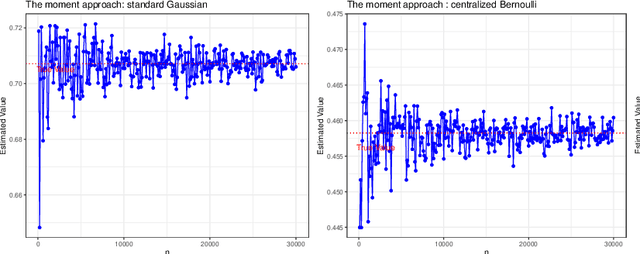
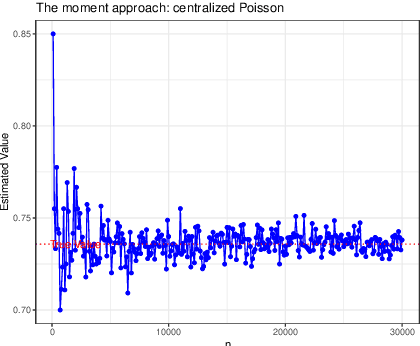
Arising in high-dimensional probability, non-asymptotic concentration inequalities play an essential role in the finite-sample theory of machine learning and high-dimensional statistics. In this article, we obtain a sharper and constants-specified concentration inequality for the summation of independent sub-Weibull random variables, which leads to a mixture of two tails: sub-Gaussian for small deviations and sub-Weibull for large deviations (from mean). These bounds improve existing bounds with sharper constants. In the application of random matrices, we derive non-asymptotic versions of Bai-Yin's theorem for sub-Weibull entries and it extends the previous result in terms of sub-Gaussian entries. In the application of negative binomial regressions, we gives the $\ell_2$-error of the estimated coefficients when covariate vector $X$ is sub-Weibull distributed with sparse structures, which is a new result for negative binomial regressions.
A Unified Light Framework for Real-time Fault Detection of Freight Train Images
Jan 31, 2021
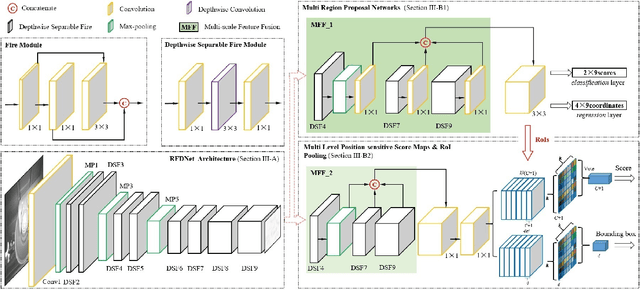


Real-time fault detection for freight trains plays a vital role in guaranteeing the security and optimal operation of railway transportation under stringent resource requirements. Despite the promising results for deep learning based approaches, the performance of these fault detectors on freight train images, are far from satisfactory in both accuracy and efficiency. This paper proposes a unified light framework to improve detection accuracy while supporting a real-time operation with a low resource requirement. We firstly design a novel lightweight backbone (RFDNet) to improve the accuracy and reduce computational cost. Then, we propose a multi region proposal network using multi-scale feature maps generated from RFDNet to improve the detection performance. Finally, we present multi level position-sensitive score maps and region of interest pooling to further improve accuracy with few redundant computations. Extensive experimental results on public benchmark datasets suggest that our RFDNet can significantly improve the performance of baseline network with higher accuracy and efficiency. Experiments on six fault datasets show that our method is capable of real-time detection at over 38 frames per second and achieves competitive accuracy and lower computation than the state-of-the-art detectors.
Concentration Inequalities for Statistical Inference
Nov 04, 2020This paper gives a review of concentration inequalities which are widely employed in analyzes of mathematical statistics in a wide range of settings, from distribution free to distribution dependent, from sub-Gaussian to sub-exponential, sub-Gamma, and sub-Weibull random variables, and from the mean to the maximum concentration. This review provides results in these settings with some fresh new results. Given the increasing popularity of high dimensional data and inference, results in the context of high-dimensional linear and Poisson regressions are also provided. We aim to illustrate the concentration inequalities with known constants and to improve existing bounds with sharper constants.
Non-asymptotic Optimal Prediction Error for RKHS-based Partially Functional Linear Models
Sep 10, 2020Under the framework of reproducing kernel Hilbert space (RKHS), we consider the penalized least-squares of the partially functional linear models (PFLM), whose predictor contains both functional and traditional multivariate part, and the multivariate part allows a divergent number of parameters. From the non-asymptotic point of view, we focus on the rate-optimal upper and lower bounds of the prediction error. An exact upper bound for the excess prediction risk is shown in a non-asymptotic form under a more general assumption known as the effective dimension to the model, by which we also show the prediction consistency when the number of multivariate covariates $p$ slightly increases with the sample size $n$. Our new finding implies a trade-off between the number of non-functional predictors and the effective dimension of the kernel principal components to ensure the prediction consistency in the increasing-dimensional setting. The analysis in our proof hinges on the spectral condition of the sandwich operator of the covariance operator and the reproducing kernel, and on the concentration inequalities for the random elements in Hilbert space. Finally, we derive the non-asymptotic minimax lower bound under the regularity assumption of Kullback-Leibler divergence of the models.
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Sep 06, 2020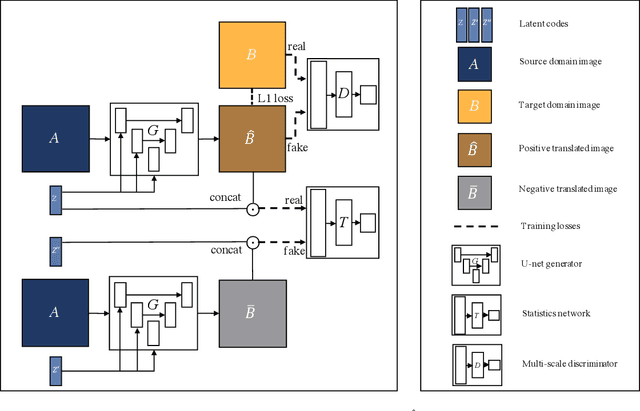
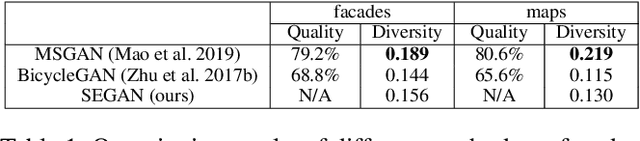

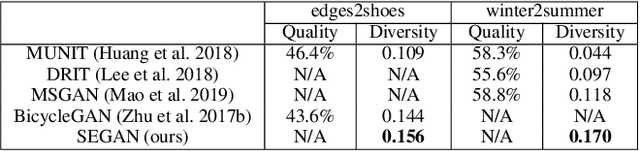
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.
Weighted Lasso Estimates for Sparse Logistic Regression: Non-asymptotic Properties with Measurement Error
Jun 11, 2020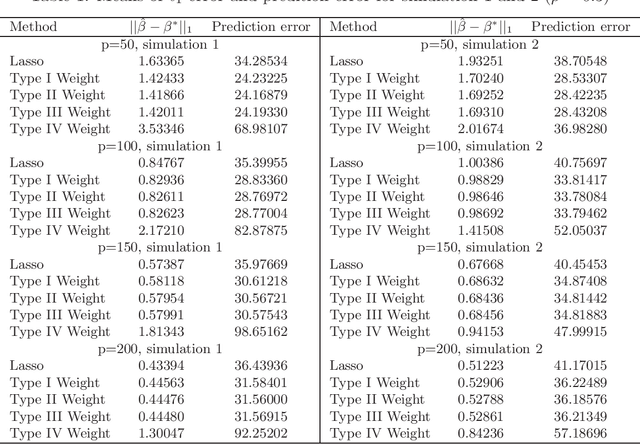
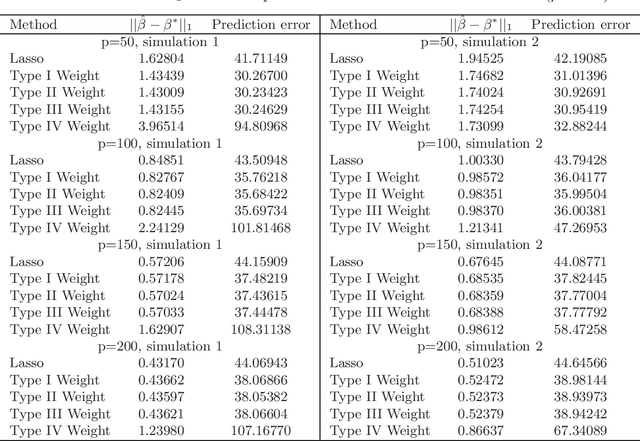
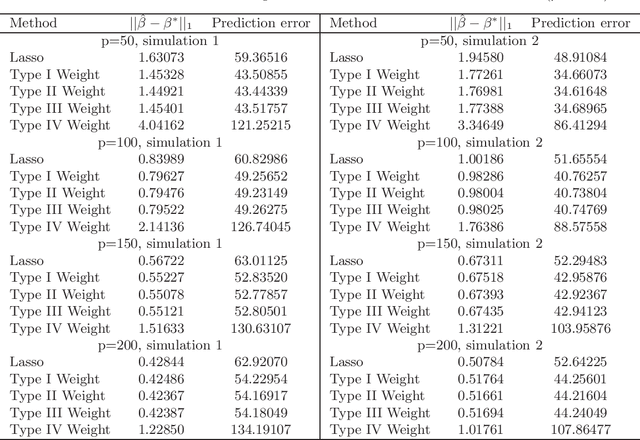
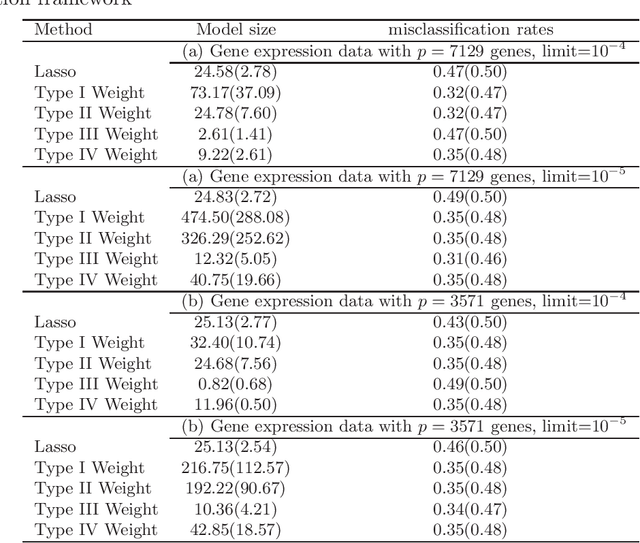
When we are interested in high-dimensional system and focus on classification performance, the $\ell_{1}$-penalized logistic regression is becoming important and popular. However, the Lasso estimates could be problematic when penalties of different coefficients are all the same and not related to the data. We proposed two types of weighted Lasso estimates depending on covariates by the McDiarmid inequality. Given sample size $n$ and dimension of covariates $p$, the finite sample behavior of our proposed methods with a diverging number of predictors is illustrated by non-asymptotic oracle inequalities such as $\ell_{1}$-estimation error and squared prediction error of the unknown parameters. We compare the performance of our methods with former weighted estimates on simulated data, then apply these methods to do real data analysis.
Optimal Distributed Subsampling for Maximum Quasi-Likelihood Estimators with Massive Data
May 21, 2020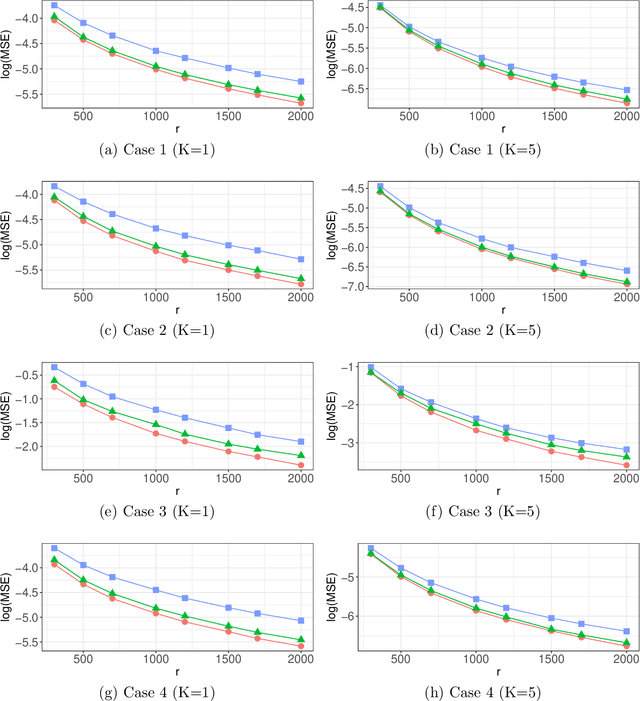
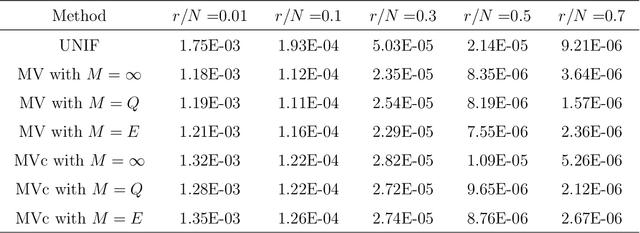
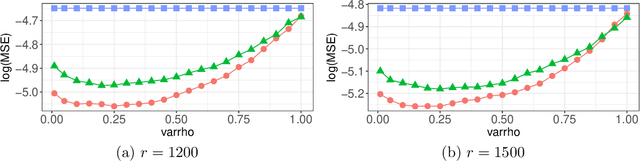
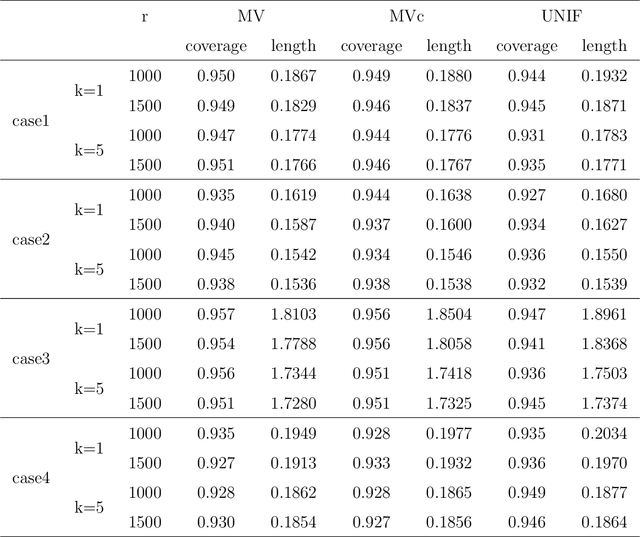
Nonuniform subsampling methods are effective to reduce computational burden and maintain estimation efficiency for massive data. Existing methods mostly focus on subsampling with replacement due to its high computational efficiency. If the data volume is so large that nonuniform subsampling probabilities cannot be calculated all at once, then subsampling with replacement is infeasible to implement. This paper solves this problem using Poisson subsampling. We first derive optimal Poisson subsampling probabilities in the context of quasi-likelihood estimation under the A- and L-optimality criteria. For a practically implementable algorithm with approximated optimal subsampling probabilities, we establish the consistency and asymptotic normality of the resultant estimators. To deal with the situation that the full data are stored in different blocks or at multiple locations, we develop a distributed subsampling framework, in which statistics are computed simultaneously on smaller partitions of the full data. Asymptotic properties of the resultant aggregated estimator are investigated. We illustrate and evaluate the proposed strategies through numerical experiments on simulated and real data sets.
Sparse Density Estimation with Measurement Errors
Nov 14, 2019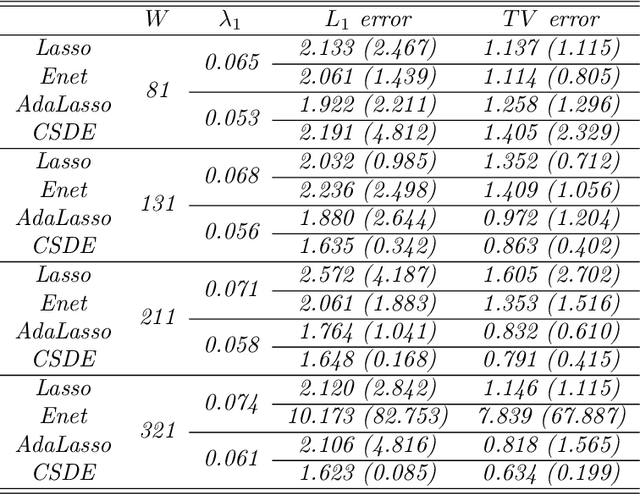
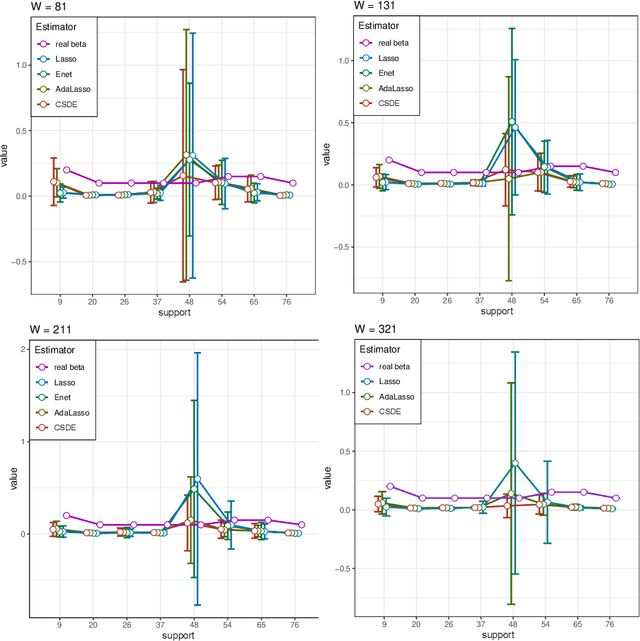
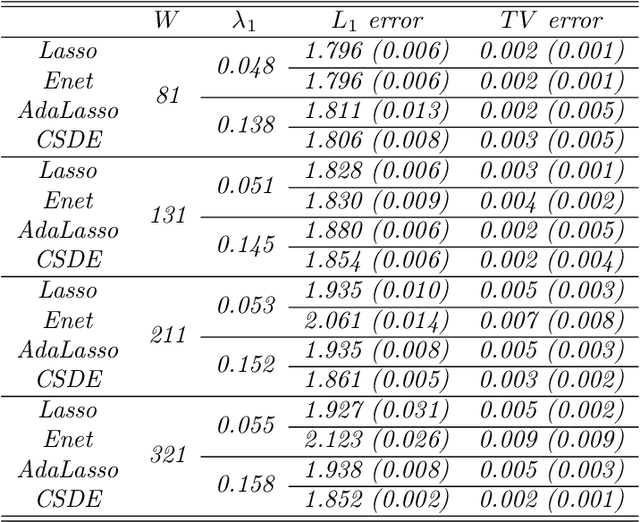
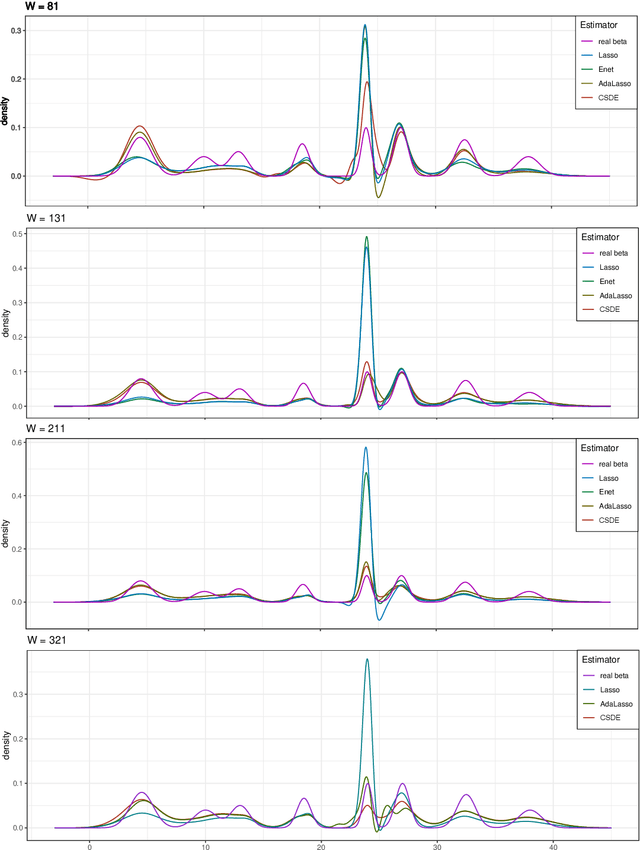
This paper aims to build an estimate of an unknown density of the data with measurement error as a linear combination of functions of a dictionary. Inspired by penalization approach, we propose the weighted Elastic-net penalized minimal $L_2$-distance method for sparse coefficients estimation, where the weights adaptively coming from sharp concentration inequalities. The optimal weighted tuning parameters are obtained by the first-order conditions holding with high-probability. Under local coherence or minimal eigenvalue assumptions, non-asymptotical oracle inequalities are derived. These theoretical results are transposed to obtain the support recovery with high-probability. Then, the issue of calibrating these procedures is studied by some numerical experiments for discrete and continuous distributions, it shows the significant improvement obtained by our procedure when compared with other conventional approaches. Finally, the application is performed for a meteorology data set. It shows that our method has potency and superiority of detecting the shape of multi-mode density compared with other conventional approaches.
Elastic-net regularized High-dimensional Negative Binomial Regression: Consistency and Weak Signals Detection
Jan 26, 2018We study sparse high-dimensional negative binomial regression problem for count data regression by showing non-asymptotic merits of the Elastic-net regularized estimator. With the KKT conditions, we derive two types of non-asymptotic oracle inequalities for the elastic net estimates of negative binomial regression by utilizing Compatibility factor and Stabil Condition, respectively. Based on oracle inequalities we proposed, we firstly show the sign consistency property of the Elastic-net estimators provided that the non-zero components in sparse true vector are large than a proper choice of the weakest signal detection threshold, and the second application is that we give an oracle inequality for bounding the grouping effect with high probability, thirdly, under some assumptions of design matrix, we can recover the true variable set with high probability if the weakest signal detection threshold is large than 3 times the value of turning parameter, at last, we briefly discuss the de-biased Elastic-net estimator.