 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Diffusion Models: Efficient Fine-Tuning and Post-Training of Interactive Diffusion Music Generators
May 21, 2026Interactive streaming music generation promises the use of generative models for live performance and co-creation that is impossible with offline models. However, SOTA models exist in the discrete-AR regime, requiring industrial levels of compute for both training and inference. In this work, we investigate whether audio diffusion models, with their wide support in the open-source community but non-streaming bidirectional nature, can be repurposed efficiently into interactive models accessible on consumer hardware. By taking a critical look at the modern pipeline for block-wise outpainting diffusion, we identify critical inefficiencies during inference that result in strictly worse computational efficiency than their discrete-AR counterparts. We propose Live Music Diffusion Models (LMDMs), a simple modification of the generative diffusion process that recovers, and then outperforms, the inference complexity of the discrete Live Music Models (LMMs) through block-wise KV Caching. Unlike LMMs, LMDMs further enable stable post-training alignment through our novel ARC-Forcing paradigm, reducing error accumulation without any explicit RL or reward models. We demonstrate the application of LMDMs in a number of creative domains, including text-conditioned generation, sketch-based music synthesis, and jamming. We finally show how LMDMs can be used as a generative instrument in a real artist-AI collaboration, utilizing LMDMs as a "generative delay" to transform musicians' improvisation live for variable timbral effects while running locally on a consumer gaming laptop.
The Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025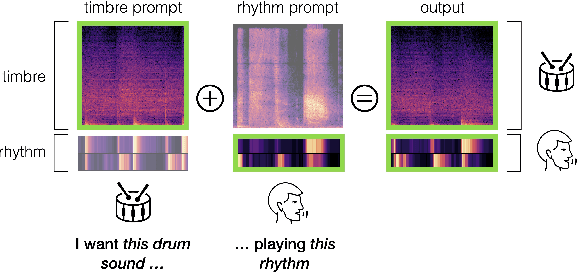
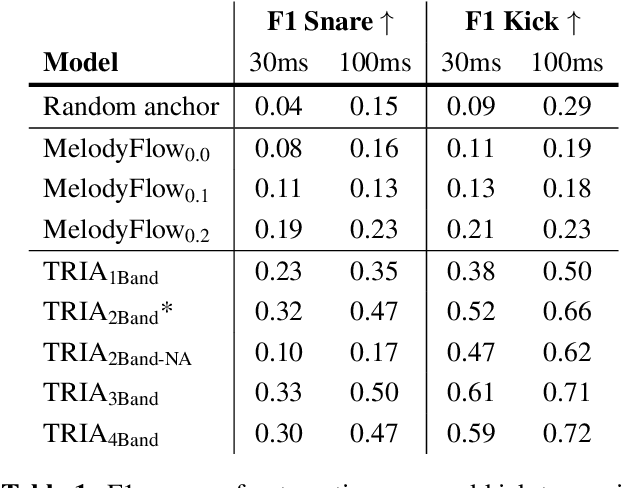
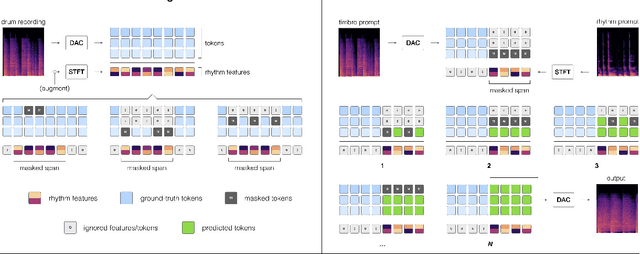
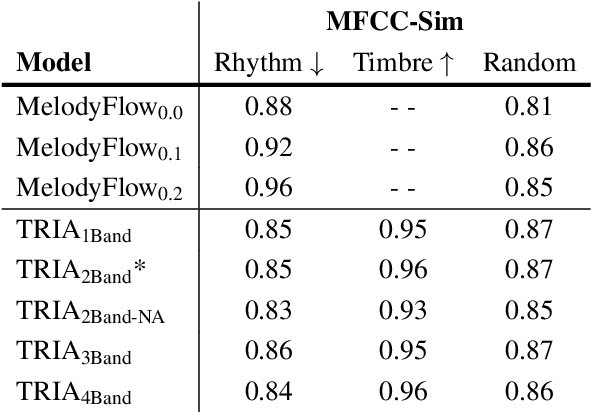
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
Sketch2Sound: Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
Dec 11, 2024


We present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e.,~a vocal imitation or a reference sound-shape). Sketch2Sound can be implemented on top of any text-to-audio latent diffusion transformer (DiT), and requires only 40k steps of fine-tuning and a single linear layer per control, making it more lightweight than existing methods like ControlNet. To synthesize from sketchlike sonic imitations, we propose applying random median filters to the control signals during training, allowing Sketch2Sound to be prompted using controls with flexible levels of temporal specificity. We show that Sketch2Sound can synthesize sounds that follow the gist of input controls from a vocal imitation while retaining the adherence to an input text prompt and audio quality compared to a text-only baseline. Sketch2Sound allows sound artists to create sounds with the semantic flexibility of text prompts and the expressivity and precision of a sonic gesture or vocal imitation. Sound examples are available at https://hugofloresgarcia.art/sketch2sound/.