 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Diffusion Models: Efficient Fine-Tuning and Post-Training of Interactive Diffusion Music Generators
May 21, 2026Interactive streaming music generation promises the use of generative models for live performance and co-creation that is impossible with offline models. However, SOTA models exist in the discrete-AR regime, requiring industrial levels of compute for both training and inference. In this work, we investigate whether audio diffusion models, with their wide support in the open-source community but non-streaming bidirectional nature, can be repurposed efficiently into interactive models accessible on consumer hardware. By taking a critical look at the modern pipeline for block-wise outpainting diffusion, we identify critical inefficiencies during inference that result in strictly worse computational efficiency than their discrete-AR counterparts. We propose Live Music Diffusion Models (LMDMs), a simple modification of the generative diffusion process that recovers, and then outperforms, the inference complexity of the discrete Live Music Models (LMMs) through block-wise KV Caching. Unlike LMMs, LMDMs further enable stable post-training alignment through our novel ARC-Forcing paradigm, reducing error accumulation without any explicit RL or reward models. We demonstrate the application of LMDMs in a number of creative domains, including text-conditioned generation, sketch-based music synthesis, and jamming. We finally show how LMDMs can be used as a generative instrument in a real artist-AI collaboration, utilizing LMDMs as a "generative delay" to transform musicians' improvisation live for variable timbral effects while running locally on a consumer gaming laptop.
Single-Shot HDR Recovery via a Video Diffusion Prior
May 12, 2026Recent generative methods for single-shot high dynamic range (HDR) image reconstruction show promising results, but often struggle with preserving fidelity to the input image. They require separate models to handle highlights and shadows, or sacrifice interpretability by directly predicting the final HDR image. We address these limitations by re-casting single-shot HDR reconstruction as conditional video generation and fusing the generated frames into an HDR image. We finetune a video diffusion model to generate an exposure bracket, conditioned on a low dynamic range (LDR) input. We fuse this image bracket using per-pixel weights predicted by a light-weight UNet. This formulation is simple, interpretable, and effective. Rather than directly hallucinating an HDR image, it explicitly reconstructs the intermediate exposure stack and fuses it into the final output. Our method eliminates the need for separate models across exposure regimes and produces HDR reconstructions with high input fidelity. On quantitative benchmarks, we outperform state-of-the-art generative baselines with comparable model capacity on several reconstruction metrics. Human evaluators further prefer our results in 72% of pairwise comparisons against existing methods. Finally, we show that this input-conditioned sequence generation and fusion framework extends beyond HDR to other image reconstruction tasks, such as all-in-focus image recovery from a single defocus-blurred input.
Leveraging 6DoF Pose Foundation Models For Mapping Marine Sediment Burial
Jun 12, 2025The burial state of anthropogenic objects on the seafloor provides insight into localized sedimentation dynamics and is also critical for assessing ecological risks, potential pollutant transport, and the viability of recovery or mitigation strategies for hazardous materials such as munitions. Accurate burial depth estimation from remote imagery remains difficult due to partial occlusion, poor visibility, and object degradation. This work introduces a computer vision pipeline, called PoseIDON, which combines deep foundation model features with multiview photogrammetry to estimate six degrees of freedom object pose and the orientation of the surrounding seafloor from ROV video. Burial depth is inferred by aligning CAD models of the objects with observed imagery and fitting a local planar approximation of the seafloor. The method is validated using footage of 54 objects, including barrels and munitions, recorded at a historic ocean dumpsite in the San Pedro Basin. The model achieves a mean burial depth error of approximately 10 centimeters and resolves spatial burial patterns that reflect underlying sediment transport processes. This approach enables scalable, non-invasive mapping of seafloor burial and supports environmental assessment at contaminated sites.
Repurposing Marigold for Zero-Shot Metric Depth Estimation via Defocus Blur Cues
May 23, 2025Recent monocular metric depth estimation (MMDE) methods have made notable progress towards zero-shot generalization. However, they still exhibit a significant performance drop on out-of-distribution datasets. We address this limitation by injecting defocus blur cues at inference time into Marigold, a \textit{pre-trained} diffusion model for zero-shot, scale-invariant monocular depth estimation (MDE). Our method effectively turns Marigold into a metric depth predictor in a training-free manner. To incorporate defocus cues, we capture two images with a small and a large aperture from the same viewpoint. To recover metric depth, we then optimize the metric depth scaling parameters and the noise latents of Marigold at inference time using gradients from a loss function based on the defocus-blur image formation model. We compare our method against existing state-of-the-art zero-shot MMDE methods on a self-collected real dataset, showing quantitative and qualitative improvements.
Volumetrically Consistent 3D Gaussian Rasterization
Dec 04, 2024



Recently, 3D Gaussian Splatting (3DGS) has enabled photorealistic view synthesis at high inference speeds. However, its splatting-based rendering model makes several approximations to the rendering equation, reducing physical accuracy. We show that splatting and its approximations are unnecessary, even within a rasterizer; we instead volumetrically integrate 3D Gaussians directly to compute the transmittance across them analytically. We use this analytic transmittance to derive more physically-accurate alpha values than 3DGS, which can directly be used within their framework. The result is a method that more closely follows the volume rendering equation (similar to ray-tracing) while enjoying the speed benefits of rasterization. Our method represents opaque surfaces with higher accuracy and fewer points than 3DGS. This enables it to outperform 3DGS for view synthesis (measured in SSIM and LPIPS). Being volumetrically consistent also enables our method to work out of the box for tomography. We match the state-of-the-art 3DGS-based tomography method with fewer points. Being volumetrically consistent also enables our method to work out of the box for tomography. We match the state-of-the-art 3DGS-based tomography method with fewer points.
Pose Estimation of Buried Deep-Sea Objects using 3D Vision Deep Learning Models
Oct 01, 2024


We present an approach for pose and burial fraction estimation of debris field barrels found on the seabed in the Southern California San Pedro Basin. Our computational workflow leverages recent advances in foundation models for segmentation and a vision transformer-based approach to estimate the point cloud which defines the geometry of the barrel. We propose BarrelNet for estimating the 6-DOF pose and radius of buried barrels from the barrel point clouds as input. We train BarrelNet using synthetically generated barrel point clouds, and qualitatively demonstrate the potential of our approach using remotely operated vehicle (ROV) video footage of barrels found at a historic dump site. We compare our method to a traditional least squares fitting approach and show significant improvement according to our defined benchmarks.
Visual Physics: Discovering Physical Laws from Videos
Nov 27, 2019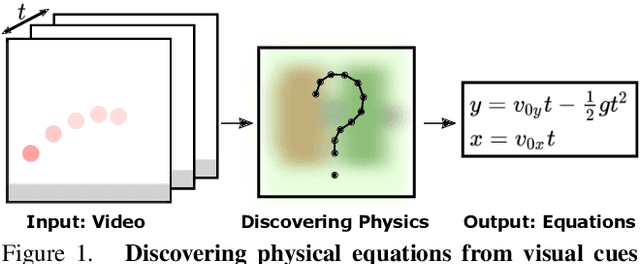

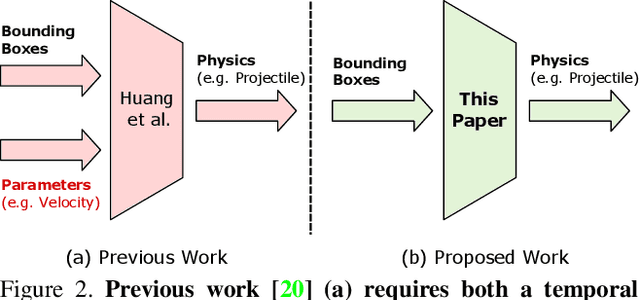
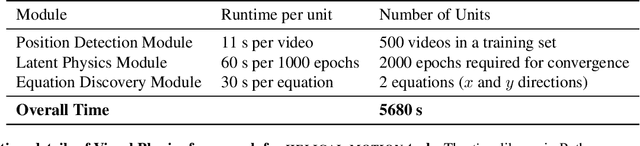
In this paper, we teach a machine to discover the laws of physics from video streams. We assume no prior knowledge of physics, beyond a temporal stream of bounding boxes. The problem is very difficult because a machine must learn not only a governing equation (e.g. projectile motion) but also the existence of governing parameters (e.g. velocities). We evaluate our ability to discover physical laws on videos of elementary physical phenomena, such as projectile motion or circular motion. These elementary tasks have textbook governing equations and enable ground truth verification of our approach.