 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025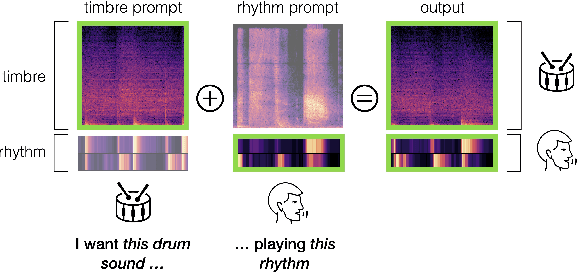
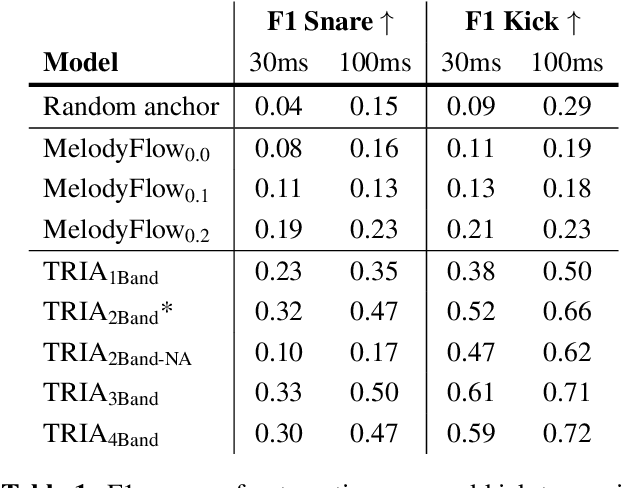
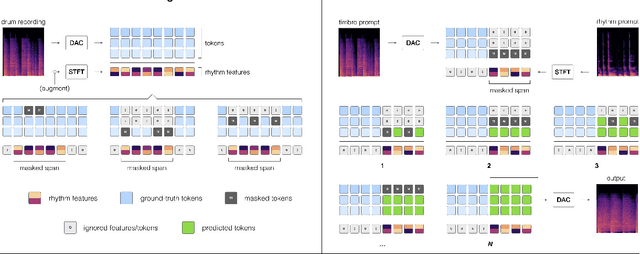
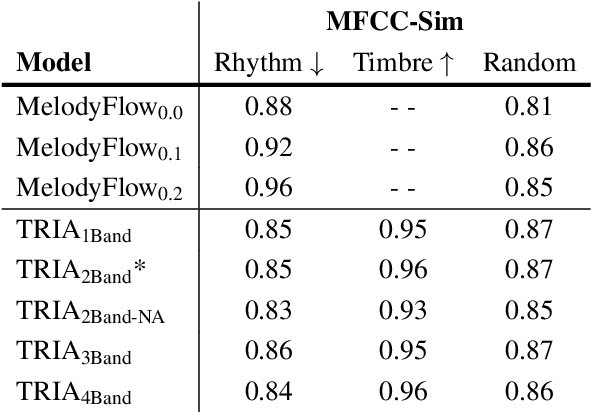
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
Sound Check: Auditing Audio Datasets
Oct 17, 2024



Generative audio models are rapidly advancing in both capabilities and public utilization -- several powerful generative audio models have readily available open weights, and some tech companies have released high quality generative audio products. Yet, while prior work has enumerated many ethical issues stemming from the data on which generative visual and textual models have been trained, we have little understanding of similar issues with generative audio datasets, including those related to bias, toxicity, and intellectual property. To bridge this gap, we conducted a literature review of hundreds of audio datasets and selected seven of the most prominent to audit in more detail. We found that these datasets are biased against women, contain toxic stereotypes about marginalized communities, and contain significant amounts of copyrighted work. To enable artists to see if they are in popular audio datasets and facilitate exploration of the contents of these datasets, we developed a web tool audio datasets exploration tool at https://audio-audit.vercel.app.
Text2FX: Harnessing CLAP Embeddings for Text-Guided Audio Effects
Sep 27, 2024



This work introduces Text2FX, a method that leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., "make this sound in-your-face and bold"). Text2FX operates without retraining any models, relying instead on single-instance optimization within the existing embedding space. We show that CLAP encodes valuable information for controlling audio effects and propose two optimization approaches using CLAP to map text to audio effect parameters. While we demonstrate with CLAP, this approach is applicable to any shared text-audio embedding space. Similarly, while we demonstrate with equalization and reverberation, any differentiable audio effect may be controlled. We conduct a listener study with diverse text prompts and source audio to evaluate the quality and alignment of these methods with human perception.