 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Tangent Kernel Empowered Federated Learning
Oct 07, 2021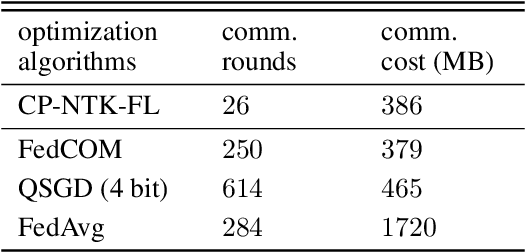
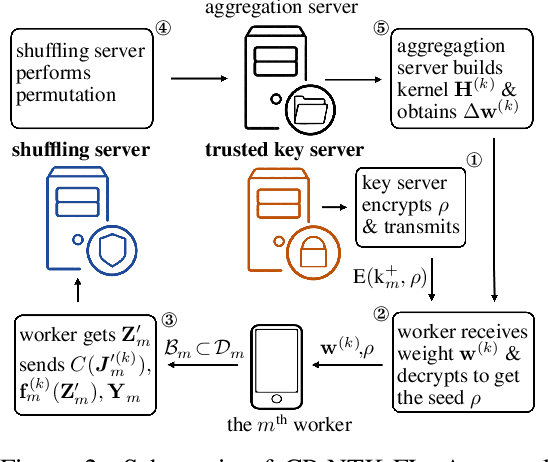
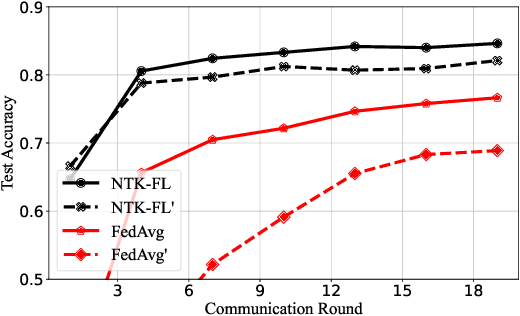
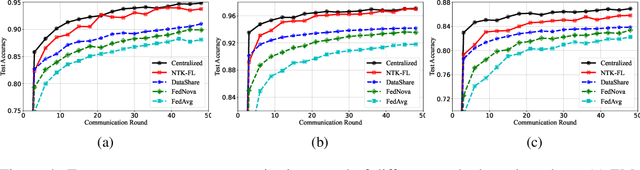
Federated learning (FL) is a privacy-preserving paradigm where multiple participants jointly solve a machine learning problem without sharing raw data. Unlike traditional distributed learning, a unique characteristic of FL is statistical heterogeneity, namely, data distributions across participants are different from each other. Meanwhile, recent advances in the interpretation of neural networks have seen a wide use of neural tangent kernel (NTK) for convergence and generalization analyses. In this paper, we propose a novel FL paradigm empowered by the NTK framework. The proposed paradigm addresses the challenge of statistical heterogeneity by transmitting update data that are more expressive than those of the traditional FL paradigms. Specifically, sample-wise Jacobian matrices, rather than model weights/gradients, are uploaded by participants. The server then constructs an empirical kernel matrix to update a global model without explicitly performing gradient descent. We further develop a variant with improved communication efficiency and enhanced privacy. Numerical results show that the proposed paradigm can achieve the same accuracy while reducing the number of communication rounds by an order of magnitude compared to federated averaging.
Federated Learning via Plurality Vote
Oct 06, 2021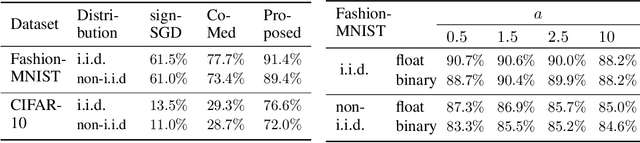
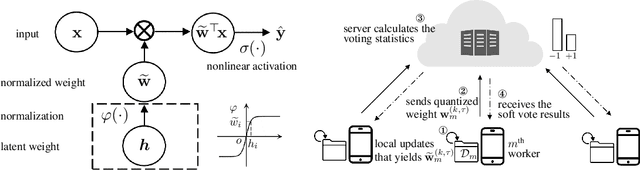

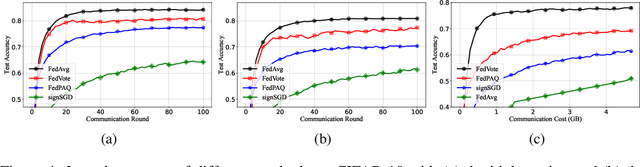
Federated learning allows collaborative workers to solve a machine learning problem while preserving data privacy. Recent studies have tackled various challenges in federated learning, but the joint optimization of communication overhead, learning reliability, and deployment efficiency is still an open problem. To this end, we propose a new scheme named federated learning via plurality vote (FedVote). In each communication round of FedVote, workers transmit binary or ternary weights to the server with low communication overhead. The model parameters are aggregated via weighted voting to enhance the resilience against Byzantine attacks. When deployed for inference, the model with binary or ternary weights is resource-friendly to edge devices. We show that our proposed method can reduce quantization error and converges faster compared with the methods directly quantizing the model updates.
Experimental Study of Outdoor UAV Localization and Tracking using Passive RF Sensing
Sep 03, 2021

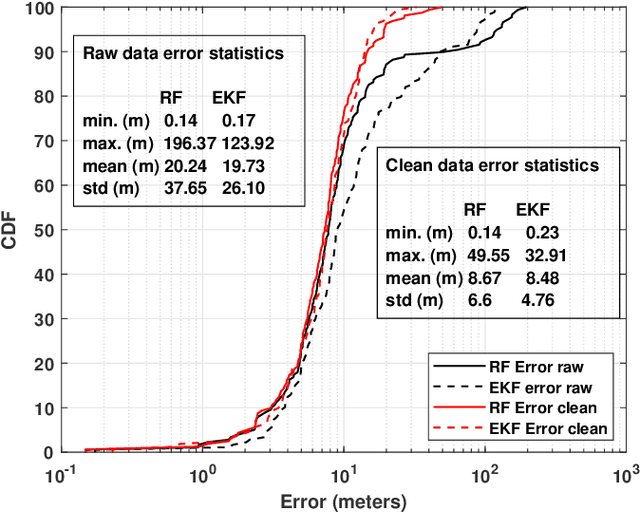
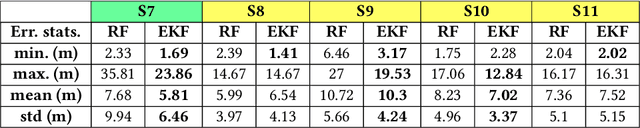
Extensive use of unmanned aerial vehicles (UAVs) is expected to raise privacy and security concerns among individuals and communities. In this context, the detection and localization of UAVs will be critical for maintaining safe and secure airspace in the future. In this work, Keysight N6854A radio frequency (RF) sensors are used to detect and locate a UAV by passively monitoring the signals emitted from the UAV. First, the Keysight sensor detects the UAV by comparing the received RF signature with various other UAVs' RF signatures in the Keysight database using an envelope detection algorithm. Afterward, time difference of arrival (TDoA) based localization is performed by a central controller using the sensor data, and the drone is localized with some error. To mitigate the localization error, implementation of an extended Kalman filter~(EKF) is proposed in this study. The performance of the proposed approach is evaluated on a realistic experimental dataset. EKF requires basic assumptions on the type of motion throughout the trajectory, i.e., the movement of the object is assumed to fit some motion model~(MM) such as constant velocity (CV), constant acceleration (CA), and constant turn (CT). In the experiments, an arbitrary trajectory is followed, therefore it is not feasible to fit the whole trajectory into a single MM. Consequently, the trajectory is segmented into sub-parts and a different MM is assumed in each segment while building the EKF model. Simulation results demonstrate an improvement in error statistics when EKF is used if the MM assumption aligns with the real motion.
60 GHz Outdoor Propagation Measurements and Analysis Using Facebook Terragraph Radios
Sep 02, 2021
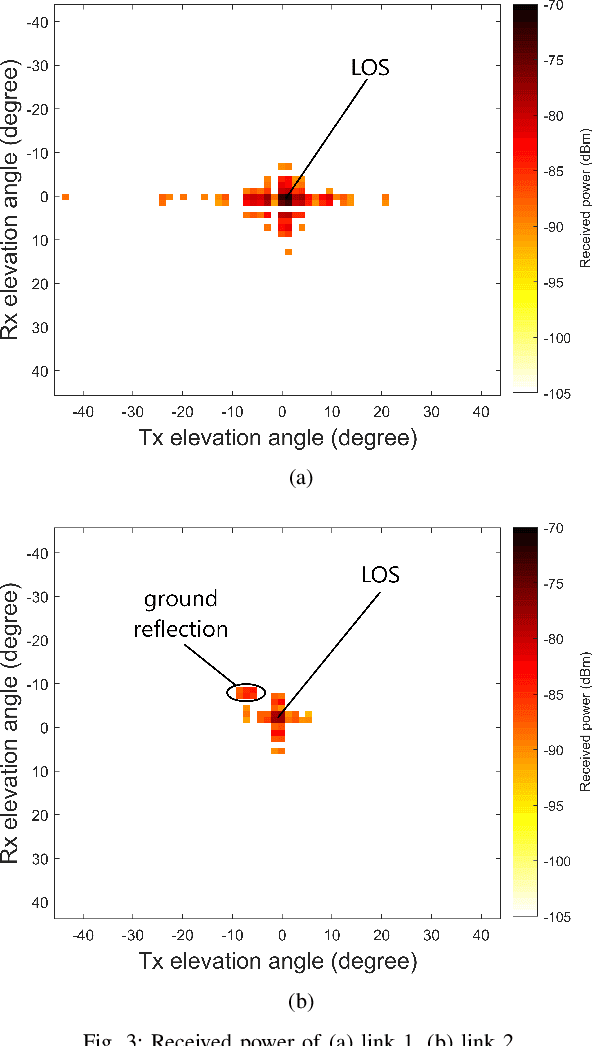
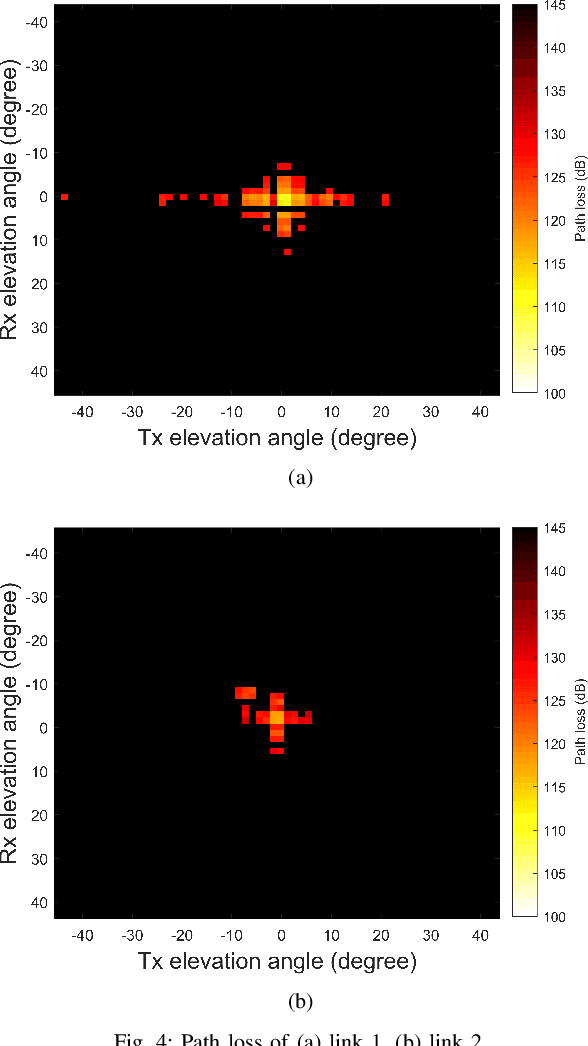
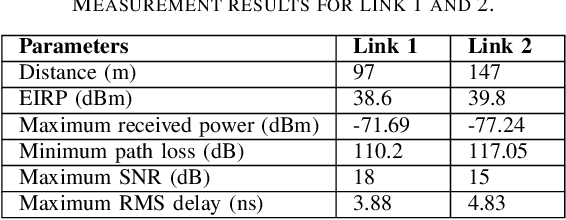
The high attenuation of millimeter-wave (mmWave) would significantly reduce the coverage areas, and hence it is critical to study the propagation characteristics of mmWave in multiple deployment scenarios. In this work, we investigated the propagation and scattering behavior of 60 GHz mmWave signals in outdoor environments at a travel distance of 98 m for an aerial link (rooftop to rooftop), and 147 m for a ground link (light-pole to light-pole). Measurements were carried out using Facebook Terragraph (TG) radios. Results include received power, path loss, signal-to-noise ratio (SNR), and root mean square (RMS) delay spread for all beamforming directions supported by the antenna array. Strong line-of-sight (LOS) propagation exists in both links. We also observed rich multipath components (MPCs) due to edge scatterings in the aerial link, while only LOS and ground reflection MPCs in the other link.
Channel Rank Improvement in Urban Drone Corridors Using Passive Intelligent Reflectors
Aug 04, 2021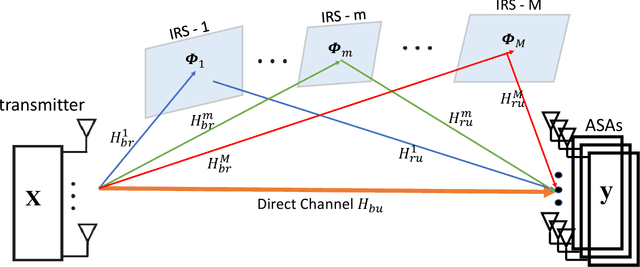
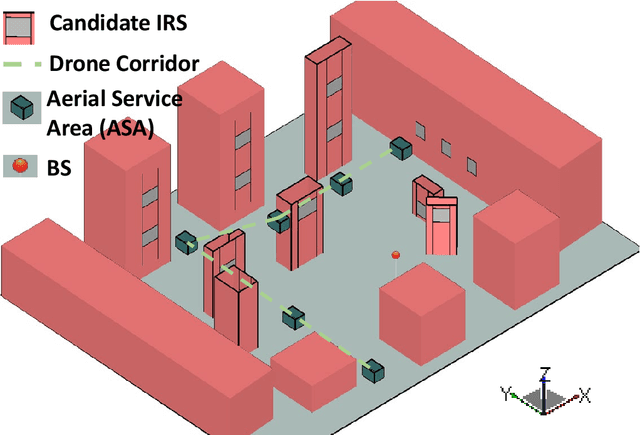
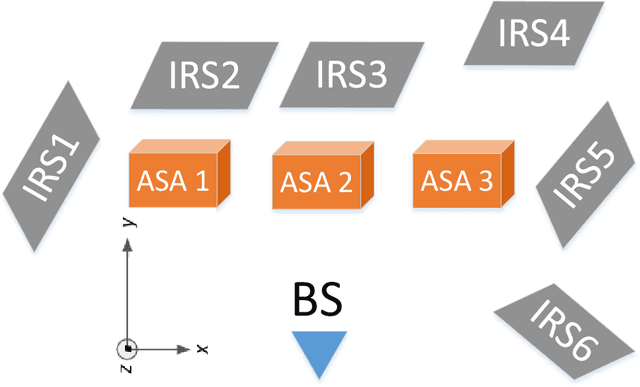
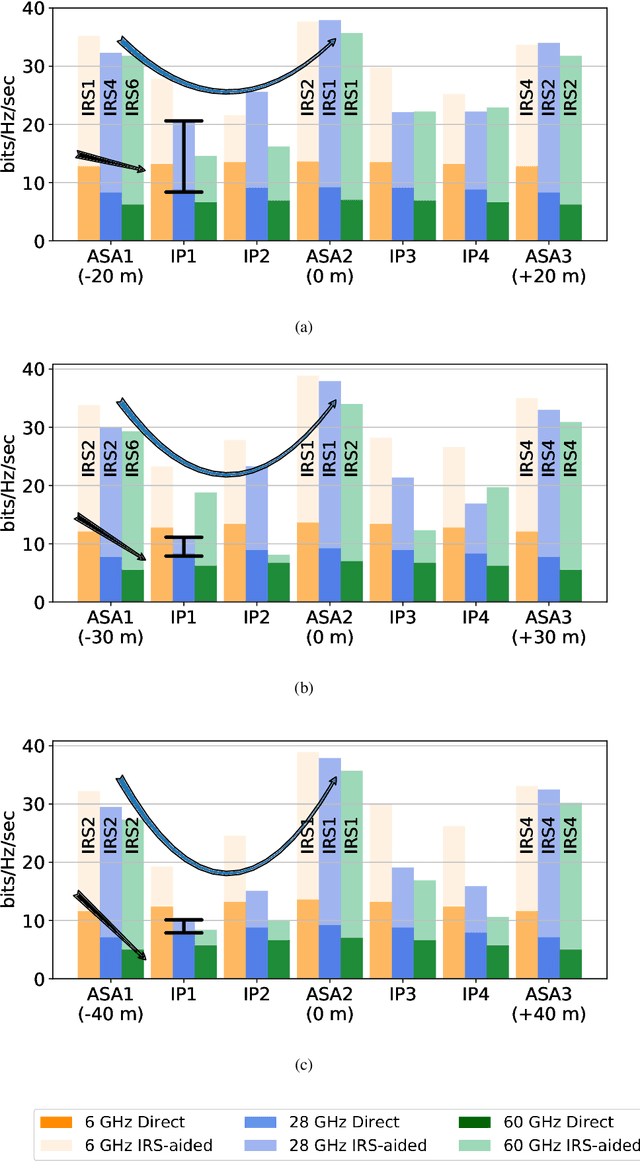
Multiple-input multiple-output (MIMO) techniques can help in scaling the achievable air-to-ground (A2G) channel capacity while communicating with drones. However, spatial multiplexing with drones suffers from rank deficient channels due to the unobstructed line-of-sight (LoS), especially in millimeter-wave (mmWave) frequencies that use narrow beams. One possible solution is utilizing low-cost and low-complexity metamaterial-based intelligent reflecting surfaces (IRS) to enrich the multipath environment, taking into account that the drones are restricted to fly only within well-defined drone corridors. A hurdle with this solution is placing the IRSs optimally. In this study, we propose an approach for IRS placement with a goal to improve the spatial multiplexing gains, and hence to maximize the average channel capacity in a predefined drone corridor. Our results at 6 GHz, 28 GHz and 60 GHz show that the proposed approach increases the average rates for all frequency bands for a given drone corridor, when compared with the environment where there are no IRSs present, and IRS-aided channels perform close to each other at sub-6 and mmWave bands.
Communication-Efficient Federated Learning via Predictive Coding
Aug 02, 2021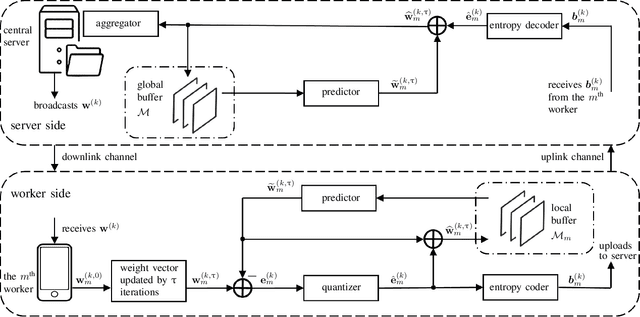
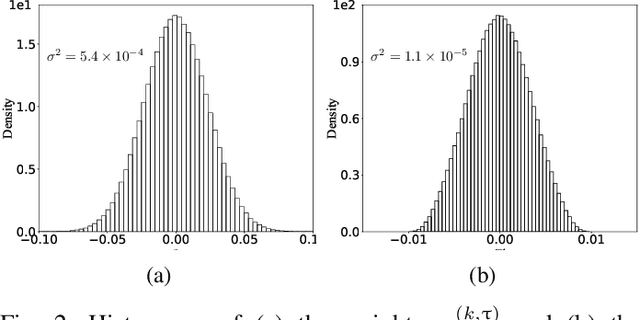
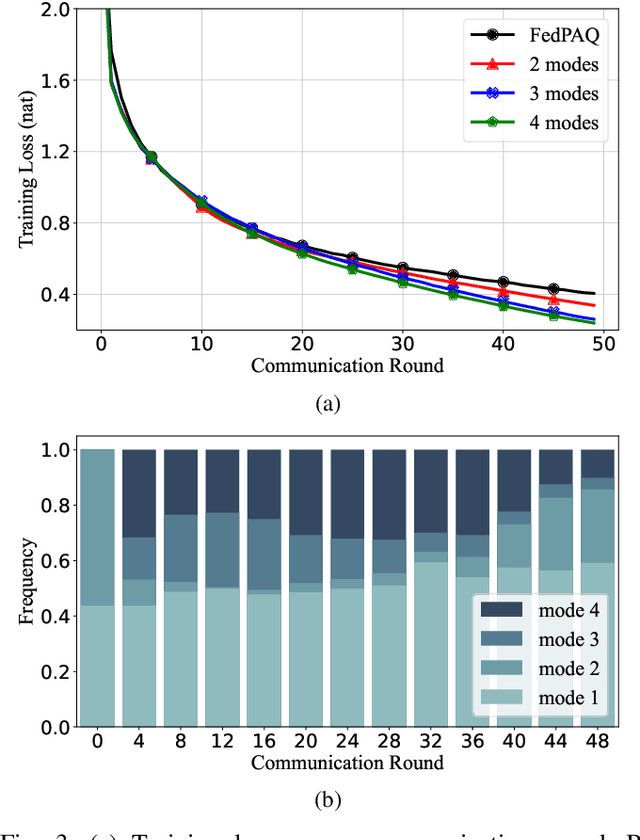
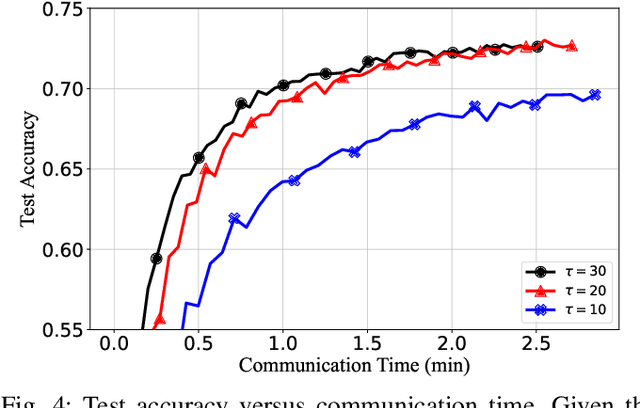
Federated learning can enable remote workers to collaboratively train a shared machine learning model while allowing training data to be kept locally. In the use case of wireless mobile devices, the communication overhead is a critical bottleneck due to limited power and bandwidth. Prior work has utilized various data compression tools such as quantization and sparsification to reduce the overhead. In this paper, we propose a predictive coding based communication scheme for federated learning. The scheme has shared prediction functions among all devices and allows each worker to transmit a compressed residual vector derived from the reference. In each communication round, we select the predictor and quantizer based on the rate-distortion cost, and further reduce the redundancy with entropy coding. Extensive simulations reveal that the communication cost can be reduced up to 99% with even better learning performance when compared with other baseline methods.
Adversarial training may be a double-edged sword
Jul 24, 2021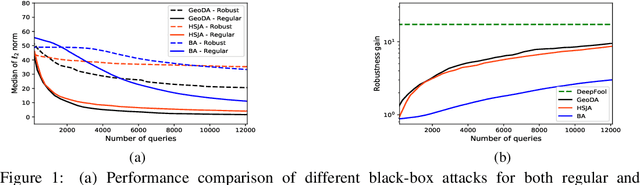

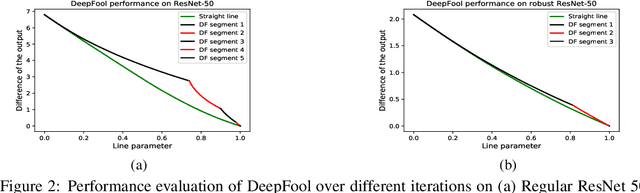
Adversarial training has been shown as an effective approach to improve the robustness of image classifiers against white-box attacks. However, its effectiveness against black-box attacks is more nuanced. In this work, we demonstrate that some geometric consequences of adversarial training on the decision boundary of deep networks give an edge to certain types of black-box attacks. In particular, we define a metric called robustness gain to show that while adversarial training is an effective method to dramatically improve the robustness in white-box scenarios, it may not provide such a good robustness gain against the more realistic decision-based black-box attacks. Moreover, we show that even the minimal perturbation white-box attacks can converge faster against adversarially-trained neural networks compared to the regular ones.
Base Station Antenna Uptilt Optimization for Cellular-Connected Drone Corridors
Jul 02, 2021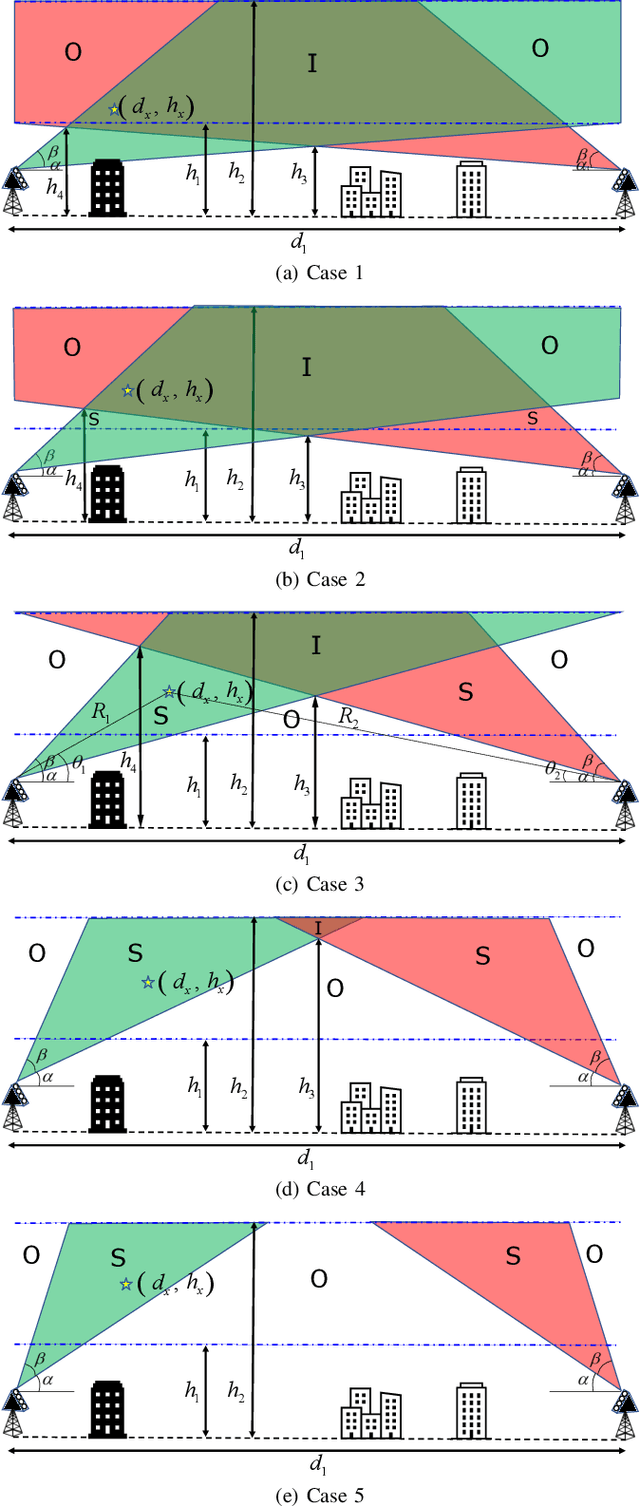
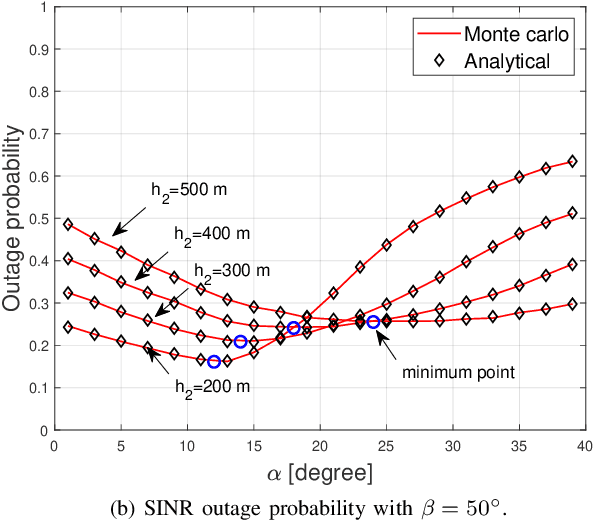
The concept of drone corridors is recently getting more attention to enable connected, safe, and secure flight zones in the national airspace. To support beyond visual line of sight (BVLOS) operations of aerial vehicles in a drone corridor, cellular base stations (BSs) serve as a convenient infrastructure, since such BSs are widely deployed to provide seamless wireless coverage. However, antennas in the existing cellular networks are down-tilted to optimally serve their ground users, which results in coverage holes if they are also used to serve drones. In this letter, we consider the use of additional uptilted antennas at cellular BSs and optimize the uptilt angle to minimize outage probability for a given drone corridor. Our numerical results show how the beamwidth and the maximum drone corridor height affect the optimal value of the antenna uptilt angle.
Precoder Design for Physical-Layer Security and Authentication in Massive MIMO UAV Communications
Jul 02, 2021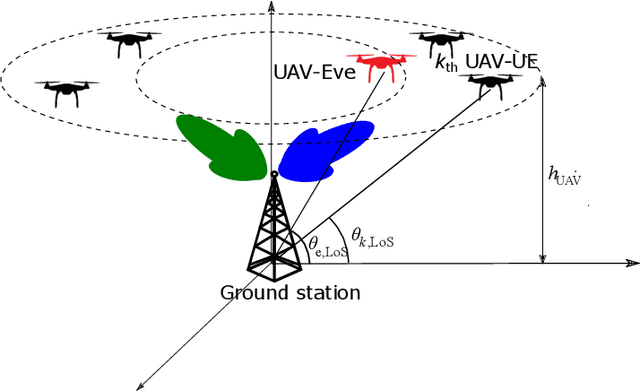
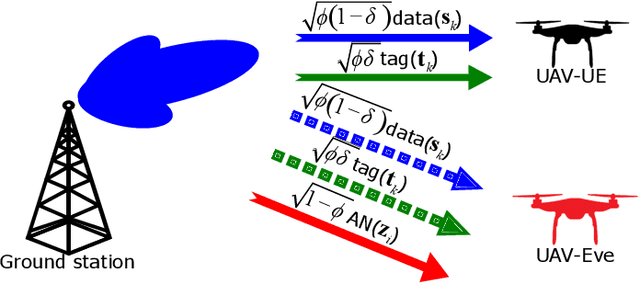
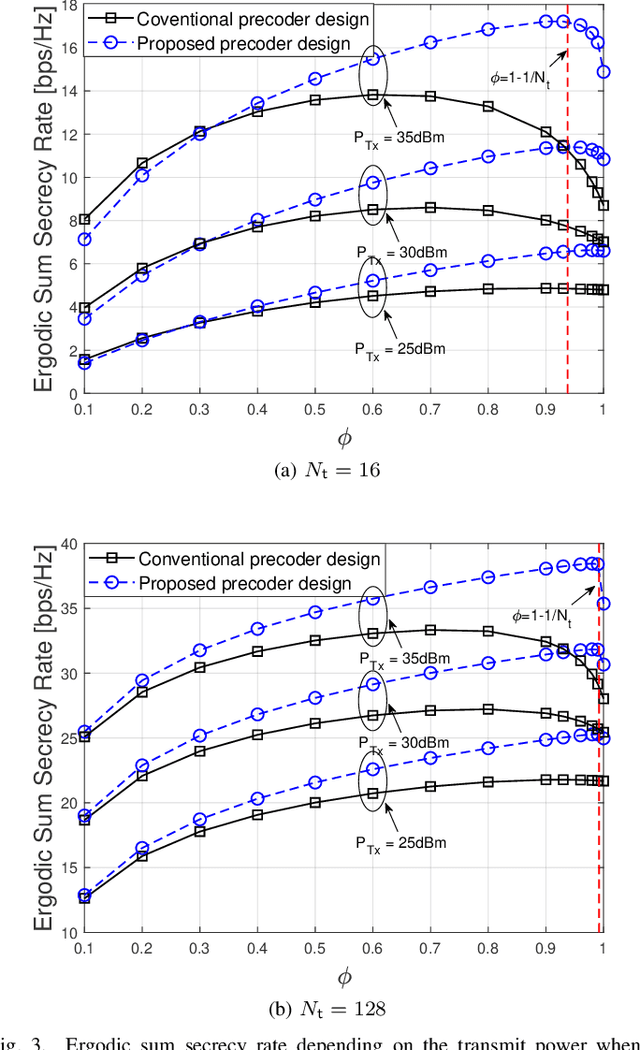
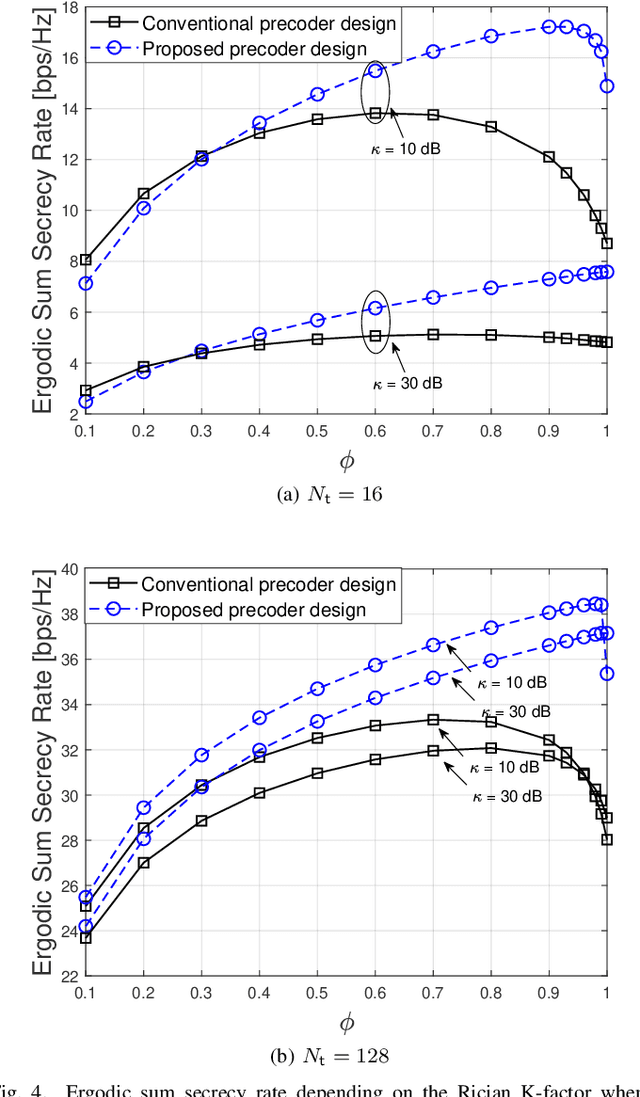
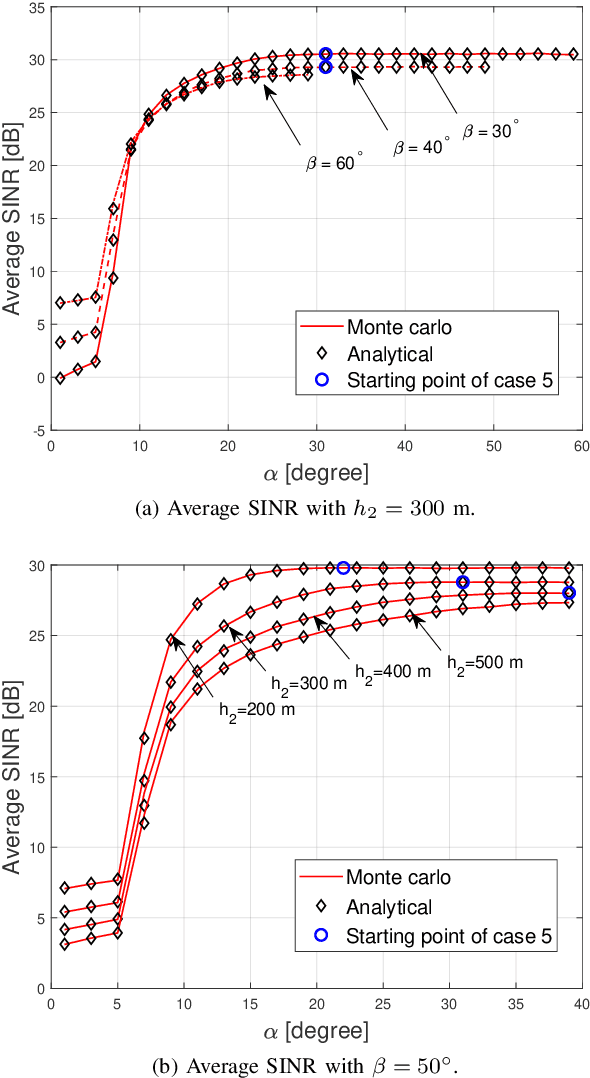
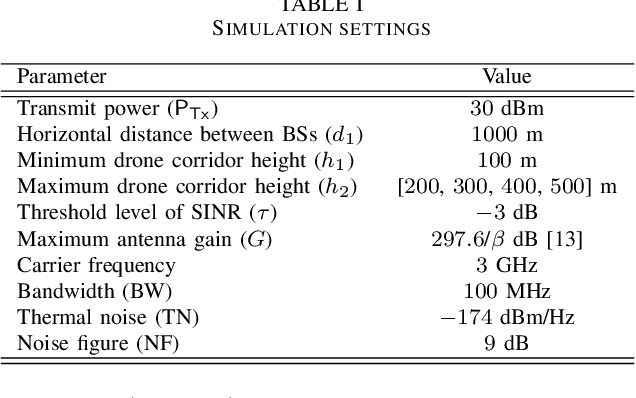
Supporting reliable and seamless wireless connectivity for unmanned aerial vehicles (UAVs) has recently become a critical requirement to enable various different use cases of UAVs. Due to their widespread deployment footprint, cellular networks can support beyond visual line of sight (BVLOS) communications for UAVs. In this paper, we consider cellular connected UAVs (C-UAVs) that are served by massive multiple-input-multiple-output (MIMO) links to extend coverage range, while also improving physical layer security and authentication. We consider Rician channel and propose a novel linear precoder design for transmitting data and artificial noise (AN). We derive the closed-form expression of the ergodic secrecy rate of C-UAVs for both conventional and proposed precoder designs. In addition, we obtain the optimal power splitting factor that divides the power between data and AN by asymptotic analysis. Then, we apply the proposed precoder design in the fingerprint embedding authentication framework, where the goal is to minimize the probability of detection of the authentication tag at an eavesdropper. In simulation results, we show the superiority of the proposed precoder in both secrecy rate and the authentication probability considering moderate and large number of antenna massive MIMO scenarios.
Decentralized Inference with Graph Neural Networks in Wireless Communication Systems
Apr 19, 2021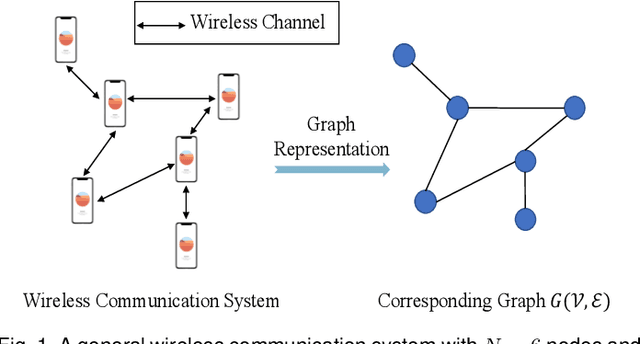
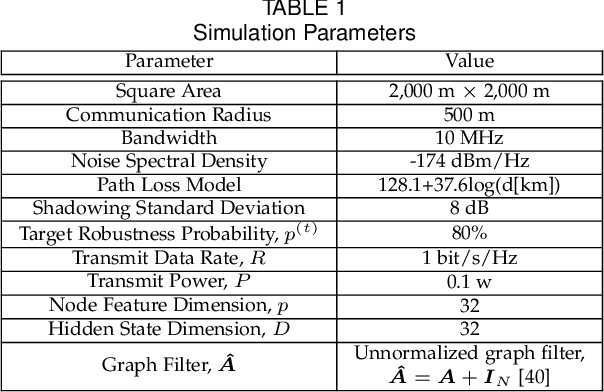

Graph neural network (GNN) is an efficient neural network model for graph data and is widely used in different fields, including wireless communications. Different from other neural network models, GNN can be implemented in a decentralized manner with information exchanges among neighbors, making it a potentially powerful tool for decentralized control in wireless communication systems. The main bottleneck, however, is wireless channel impairments that deteriorate the prediction robustness of GNN. To overcome this obstacle, we analyze and enhance the robustness of the decentralized GNN in different wireless communication systems in this paper. Specifically, using a GNN binary classifier as an example, we first develop a methodology to verify whether the predictions are robust. Then, we analyze the performance of the decentralized GNN binary classifier in both uncoded and coded wireless communication systems. To remedy imperfect wireless transmission and enhance the prediction robustness, we further propose novel retransmission mechanisms for the above two communication systems, respectively. Through simulations on the synthetic graph data, we validate our analysis, verify the effectiveness of the proposed retransmission mechanisms, and provide some insights for practical implementation.