 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Oct 12, 2022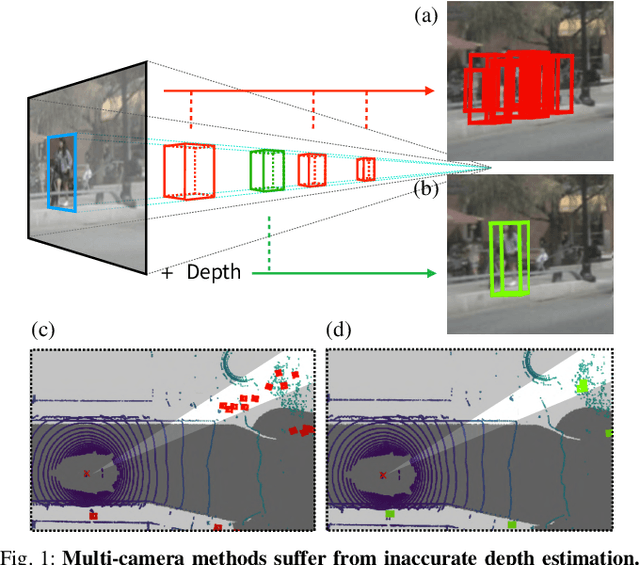
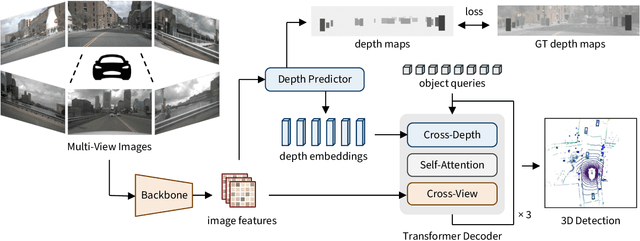
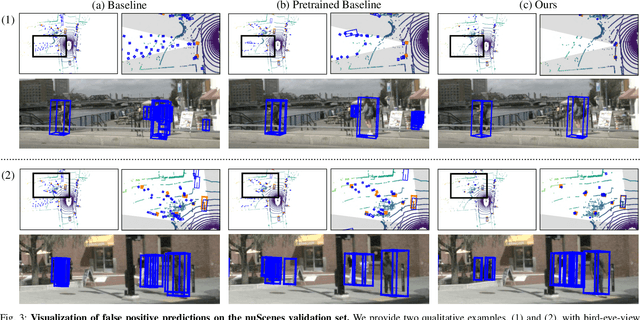
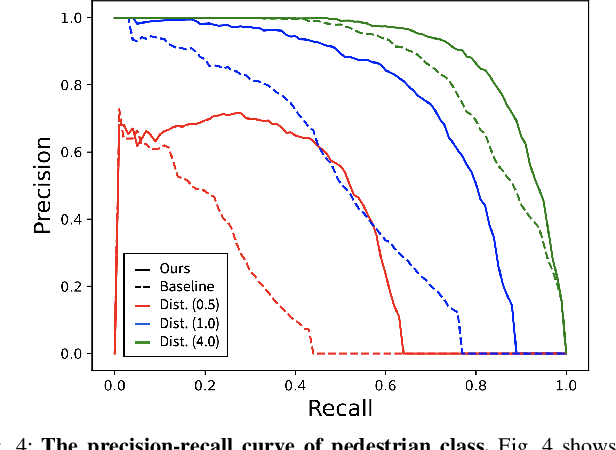
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
Learning Fine-Grained Visual Understanding for Video Question Answering via Decoupling Spatial-Temporal Modeling
Oct 08, 2022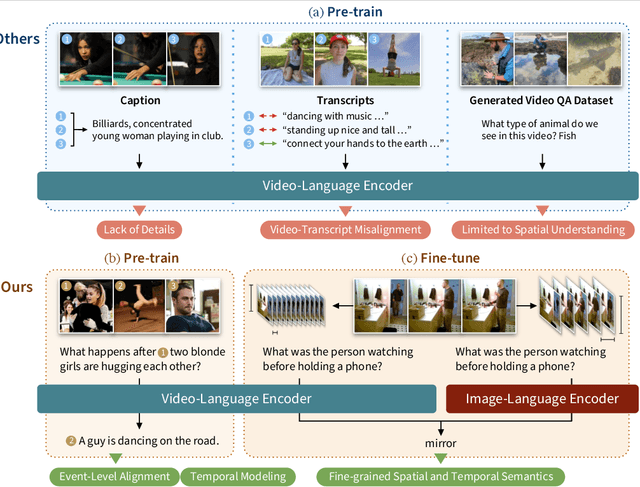
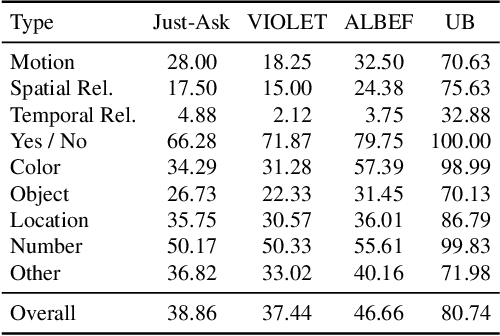
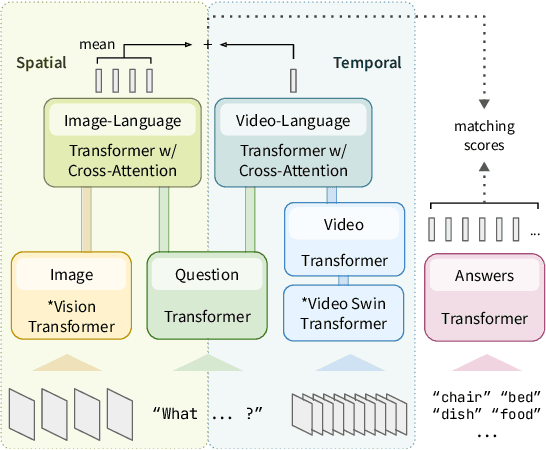
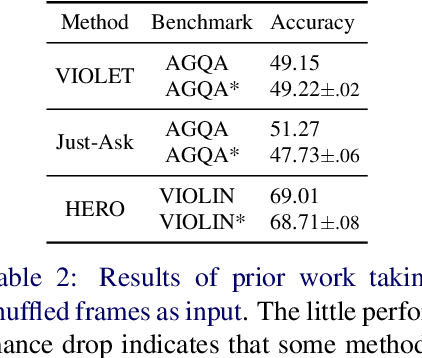
While recent large-scale video-language pre-training made great progress in video question answering, the design of spatial modeling of video-language models is less fine-grained than that of image-language models; existing practices of temporal modeling also suffer from weak and noisy alignment between modalities. To learn fine-grained visual understanding, we decouple spatial-temporal modeling and propose a hybrid pipeline, Decoupled Spatial-Temporal Encoders, integrating an image- and a video-language encoder. The former encodes spatial semantics from larger but sparsely sampled frames independently of time, while the latter models temporal dynamics at lower spatial but higher temporal resolution. To help the video-language model learn temporal relations for video QA, we propose a novel pre-training objective, Temporal Referring Modeling, which requires the model to identify temporal positions of events in video sequences. Extensive experiments demonstrate that our model outperforms previous work pre-trained on orders of magnitude larger datasets.
Coarse-to-Fine Point Cloud Registration with SE-Equivariant Representations
Oct 05, 2022
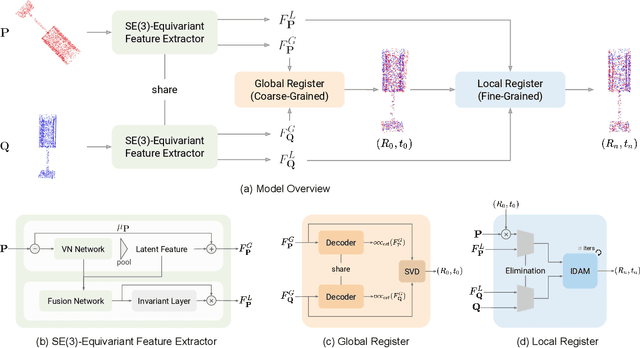
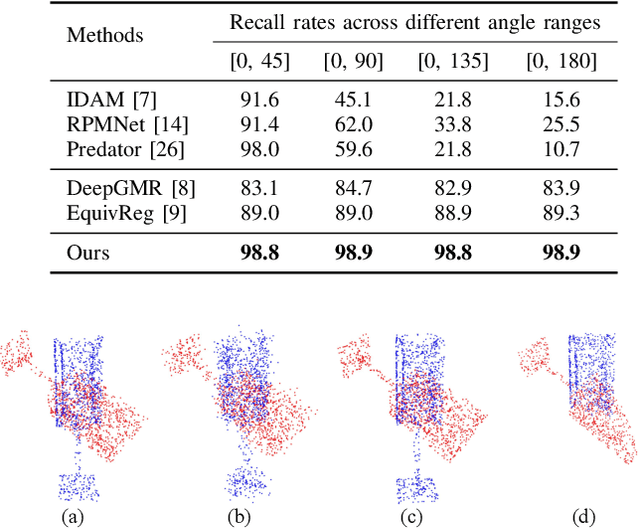
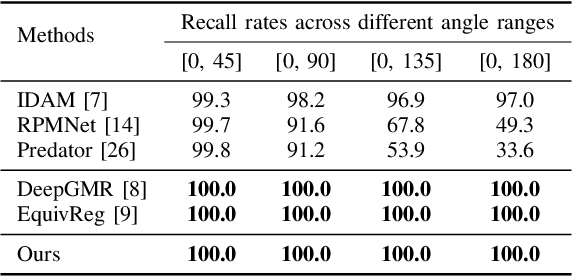
Point cloud registration is a crucial problem in computer vision and robotics. Existing methods either rely on matching local geometric features, which are sensitive to the pose differences, or leverage global shapes and thereby lead to inconsistency when facing distribution variances such as partial overlapping. Combining the advantages of both types of methods, we adopt a coarse-to-fine pipeline that concurrently handles both issues. We first reduce the pose differences between input point clouds by aligning global features; then we match the local features to further refine the inaccurate alignments resulting from distribution variances. As global feature alignment requires the features to preserve the poses of input point clouds and local feature matching expects the features to be invariant to these poses, we propose an SE(3)-equivariant feature extractor to simultaneously generate two types of features. In this feature extractor, representations preserving the poses are first encoded by our novel SE(3)-equivariant network and then converted into pose-invariant ones by a pose-detaching module. Experiments demonstrate that our proposed method increases the recall rate by 20% compared to state-of-the-art methods when facing both pose differences and distribution variances.
CFVS: Coarse-to-Fine Visual Servoing for 6-DoF Object-Agnostic Peg-In-Hole Assembly
Sep 19, 2022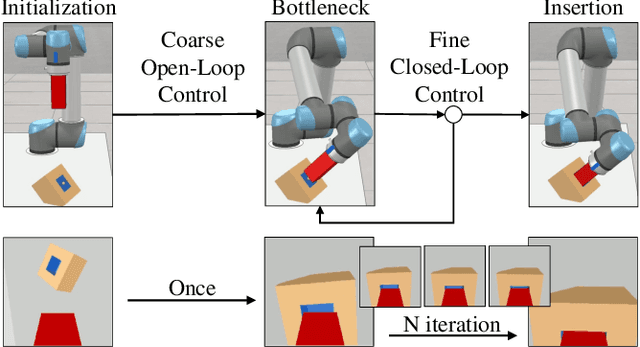
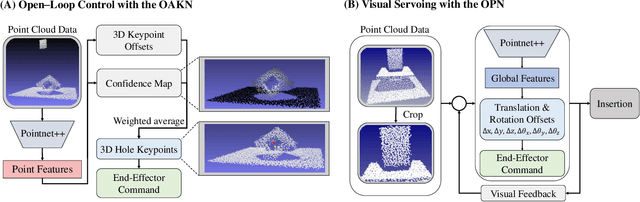

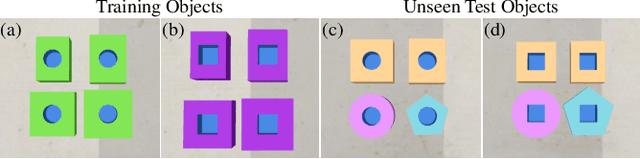
Robotic peg-in-hole assembly remains a challenging task due to its high accuracy demand. Previous work tends to simplify the problem by restricting the degree of freedom of the end-effector, or limiting the distance between the target and the initial pose position, which prevents them from being deployed in real-world manufacturing. Thus, we present a Coarse-to-Fine Visual Servoing (CFVS) peg-in-hole method, achieving 6-DoF end-effector motion control based on 3D visual feedback. CFVS can handle arbitrary tilt angles and large initial alignment errors through a fast pose estimation before refinement. Furthermore, by introducing a confidence map to ignore the irrelevant contour of objects, CFVS is robust against noise and can deal with various targets beyond training data. Extensive experiments show CFVS outperforms state-of-the-art methods and obtains 100%, 91%, and 82% average success rates in 3-DoF, 4-DoF, and 6-DoF peg-in-hole, respectively.
Adaptively-Realistic Image Generation from Stroke and Sketch with Diffusion Model
Sep 01, 2022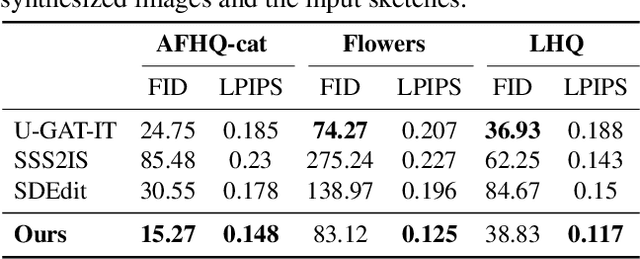
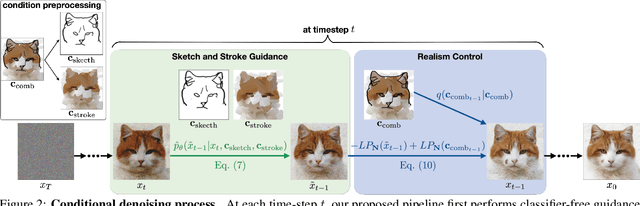

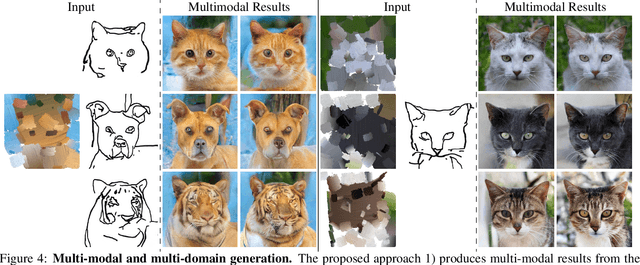
Generating images from hand-drawings is a crucial and fundamental task in content creation. The translation is difficult as there exist infinite possibilities and the different users usually expect different outcomes. Therefore, we propose a unified framework supporting a three-dimensional control over the image synthesis from sketches and strokes based on diffusion models. Users can not only decide the level of faithfulness to the input strokes and sketches, but also the degree of realism, as the user inputs are usually not consistent with the real images. Qualitative and quantitative experiments demonstrate that our framework achieves state-of-the-art performance while providing flexibility in generating customized images with control over shape, color, and realism. Moreover, our method unleashes applications such as editing on real images, generation with partial sketches and strokes, and multi-domain multi-modal synthesis.
Vector Quantized Image-to-Image Translation
Jul 27, 2022



Current image-to-image translation methods formulate the task with conditional generation models, leading to learning only the recolorization or regional changes as being constrained by the rich structural information provided by the conditional contexts. In this work, we propose introducing the vector quantization technique into the image-to-image translation framework. The vector quantized content representation can facilitate not only the translation, but also the unconditional distribution shared among different domains. Meanwhile, along with the disentangled style representation, the proposed method further enables the capability of image extension with flexibility in both intra- and inter-domains. Qualitative and quantitative experiments demonstrate that our framework achieves comparable performance to the state-of-the-art image-to-image translation and image extension methods. Compared to methods for individual tasks, the proposed method, as a unified framework, unleashes applications combining image-to-image translation, unconditional generation, and image extension altogether. For example, it provides style variability for image generation and extension, and equips image-to-image translation with further extension capabilities.
Cross-Modal 3D Shape Generation and Manipulation
Jul 24, 2022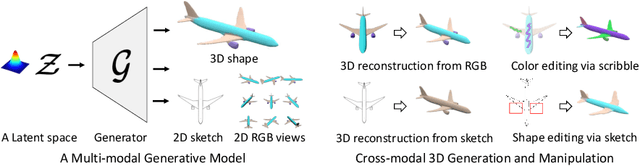

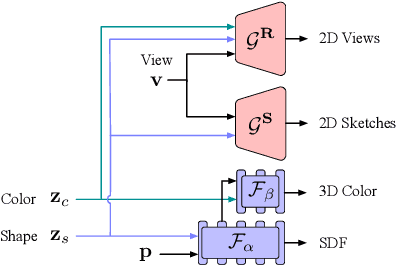
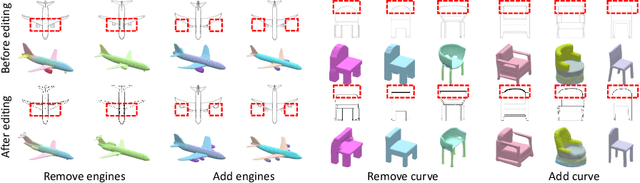
Creating and editing the shape and color of 3D objects require tremendous human effort and expertise. Compared to direct manipulation in 3D interfaces, 2D interactions such as sketches and scribbles are usually much more natural and intuitive for the users. In this paper, we propose a generic multi-modal generative model that couples the 2D modalities and implicit 3D representations through shared latent spaces. With the proposed model, versatile 3D generation and manipulation are enabled by simply propagating the editing from a specific 2D controlling modality through the latent spaces. For example, editing the 3D shape by drawing a sketch, re-colorizing the 3D surface via painting color scribbles on the 2D rendering, or generating 3D shapes of a certain category given one or a few reference images. Unlike prior works, our model does not require re-training or fine-tuning per editing task and is also conceptually simple, easy to implement, robust to input domain shifts, and flexible to diverse reconstruction on partial 2D inputs. We evaluate our framework on two representative 2D modalities of grayscale line sketches and rendered color images, and demonstrate that our method enables various shape manipulation and generation tasks with these 2D modalities.
Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features
Jun 02, 2022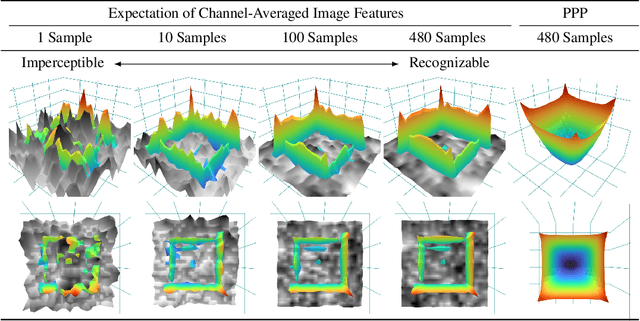
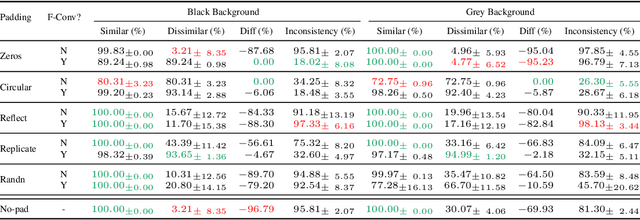
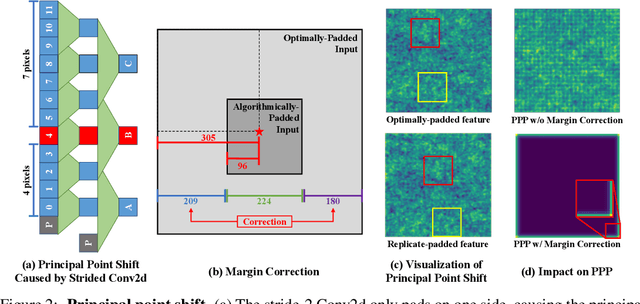
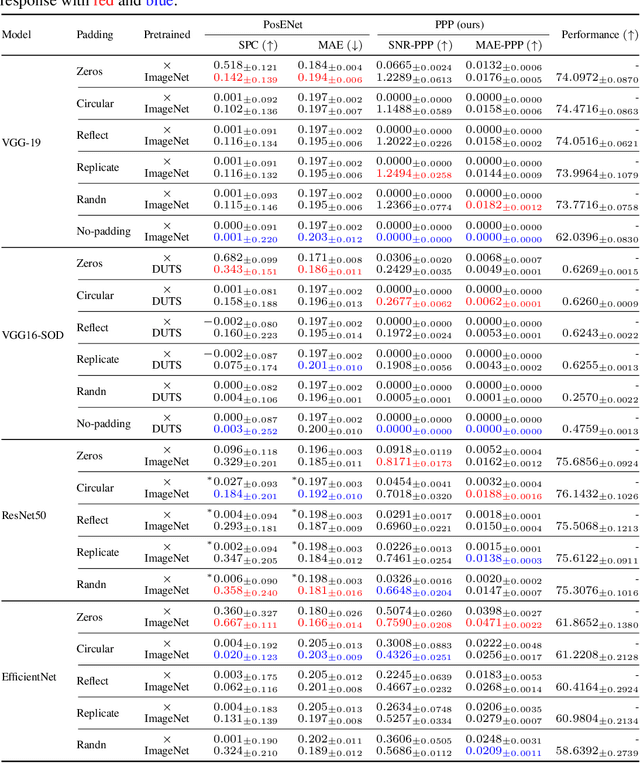
Recent studies show that paddings in convolutional neural networks encode absolute position information which can negatively affect the model performance for certain tasks. However, existing metrics for quantifying the strength of positional information remain unreliable and frequently lead to erroneous results. To address this issue, we propose novel metrics for measuring (and visualizing) the encoded positional information. We formally define the encoded information as PPP (Position-information Pattern from Padding) and conduct a series of experiments to study its properties as well as its formation. The proposed metrics measure the presence of positional information more reliably than the existing metrics based on PosENet and a test in F-Conv. We also demonstrate that for any extant (and proposed) padding schemes, PPP is primarily a learning artifact and is less dependent on the characteristics of the underlying padding schemes.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022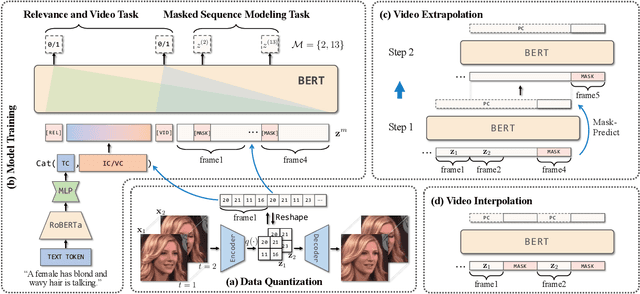
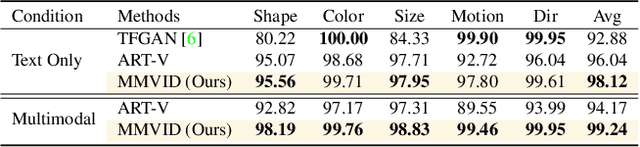


Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.
ADeADA: Adaptive Density-aware Active Domain Adaptation for Semantic Segmentation
Feb 15, 2022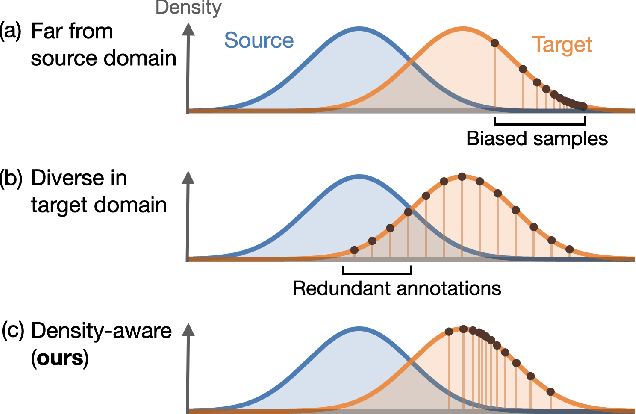
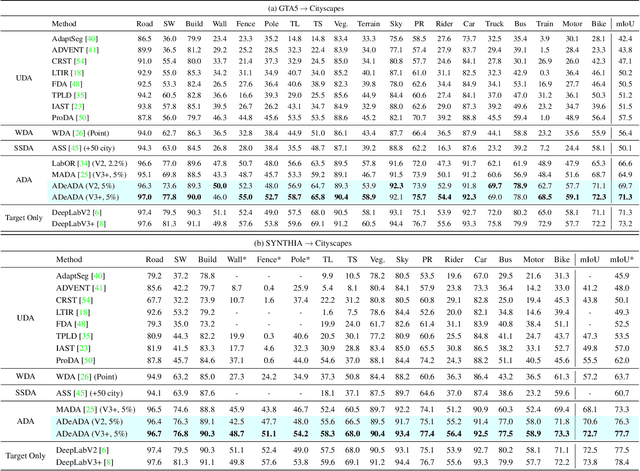
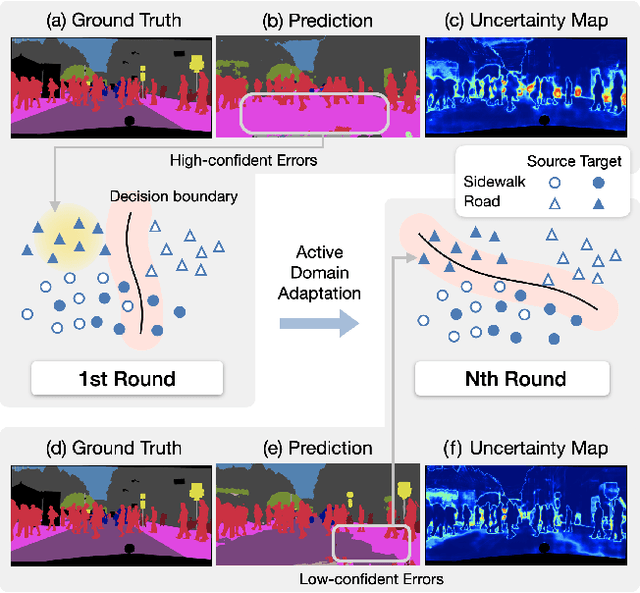
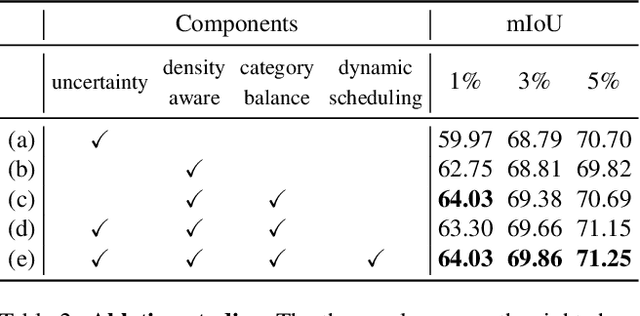
In the field of domain adaptation, a trade-off exists between the model performance and the number of target domain annotations. Active learning, maximizing model performance with few informative labeled data, comes in handy for such a scenario. In this work, we present ADeADA, a general active domain adaptation framework for semantic segmentation. To adapt the model to the target domain with minimum queried labels, we propose acquiring labels of the samples with high probability density in the target domain yet with low probability density in the source domain, complementary to the existing source domain labeled data. To further facilitate the label efficiency, we design an adaptive budget allocation policy, which dynamically balances the labeling budgets among different categories as well as between density-aware and uncertainty-based methods. Extensive experiments show that our method outperforms existing active learning and domain adaptation baselines on two benchmarks, GTA5 -> Cityscapes and SYNTHIA -> Cityscapes. With less than 5% target domain annotations, our method reaches comparable results with that of full supervision.