 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe VoiceMOS Challenge 2022
Mar 28, 2022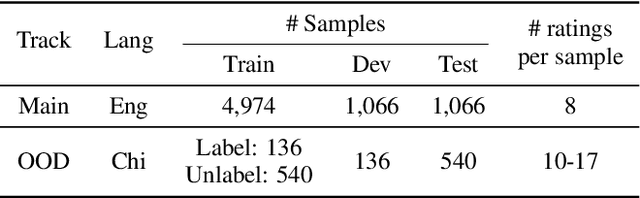
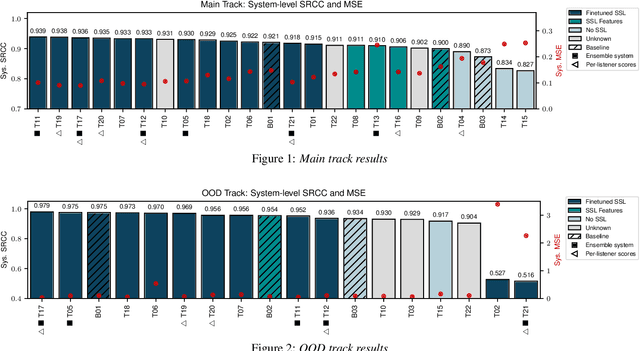
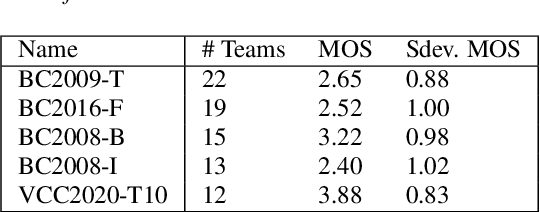
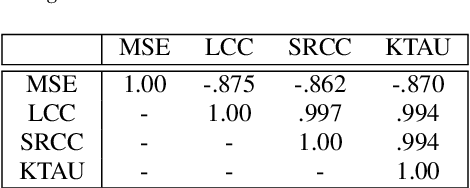
We present the first edition of the VoiceMOS Challenge, a scientific event that aims to promote the study of automatic prediction of the mean opinion score (MOS) of synthetic speech. This challenge drew 22 participating teams from academia and industry who tried a variety of approaches to tackle the problem of predicting human ratings of synthesized speech. The listening test data for the main track of the challenge consisted of samples from 187 different text-to-speech and voice conversion systems spanning over a decade of research, and the out-of-domain track consisted of data from more recent systems rated in a separate listening test. Results of the challenge show the effectiveness of fine-tuning self-supervised speech models for the MOS prediction task, as well as the difficulty of predicting MOS ratings for unseen speakers and listeners, and for unseen systems in the out-of-domain setting.
Subspace-based Representation and Learning for Phonotactic Spoken Language Recognition
Mar 28, 2022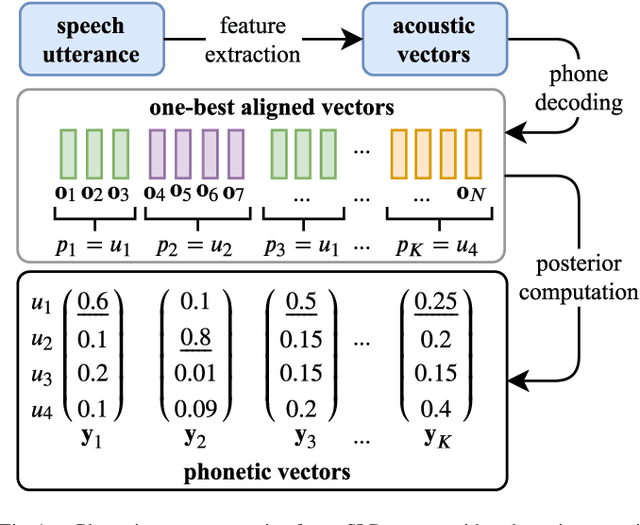
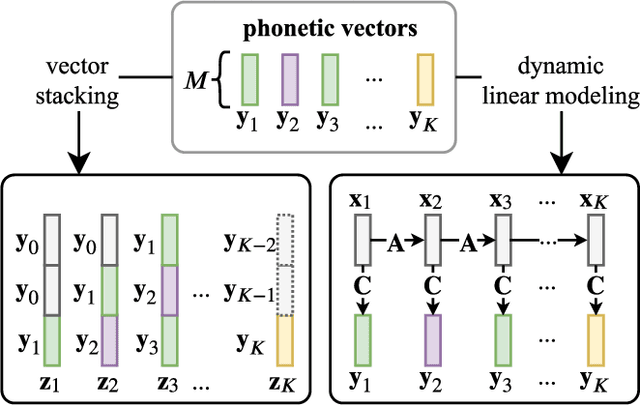
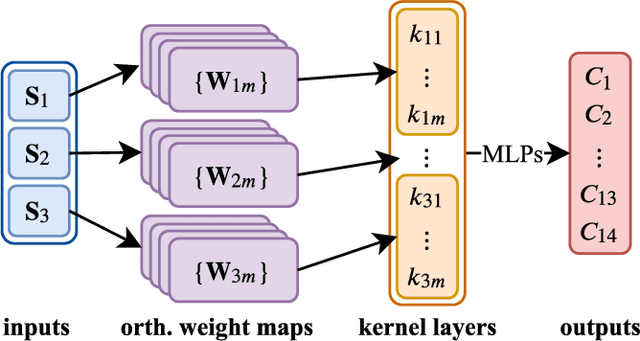

Phonotactic constraints can be employed to distinguish languages by representing a speech utterance as a multinomial distribution or phone events. In the present study, we propose a new learning mechanism based on subspace-based representation, which can extract concealed phonotactic structures from utterances, for language verification and dialect/accent identification. The framework mainly involves two successive parts. The first part involves subspace construction. Specifically, it decodes each utterance into a sequence of vectors filled with phone-posteriors and transforms the vector sequence into a linear orthogonal subspace based on low-rank matrix factorization or dynamic linear modeling. The second part involves subspace learning based on kernel machines, such as support vector machines and the newly developed subspace-based neural networks (SNNs). The input layer of SNNs is specifically designed for the sample represented by subspaces. The topology ensures that the same output can be derived from identical subspaces by modifying the conventional feed-forward pass to fit the mathematical definition of subspace similarity. Evaluated on the "General LR" test of NIST LRE 2007, the proposed method achieved up to 52%, 46%, 56%, and 27% relative reductions in equal error rates over the sequence-based PPR-LM, PPR-VSM, and PPR-IVEC methods and the lattice-based PPR-LM method, respectively. Furthermore, on the dialect/accent identification task of NIST LRE 2009, the SNN-based system performed better than the aforementioned four baseline methods.
Speech-enhanced and Noise-aware Networks for Robust Speech Recognition
Mar 25, 2022
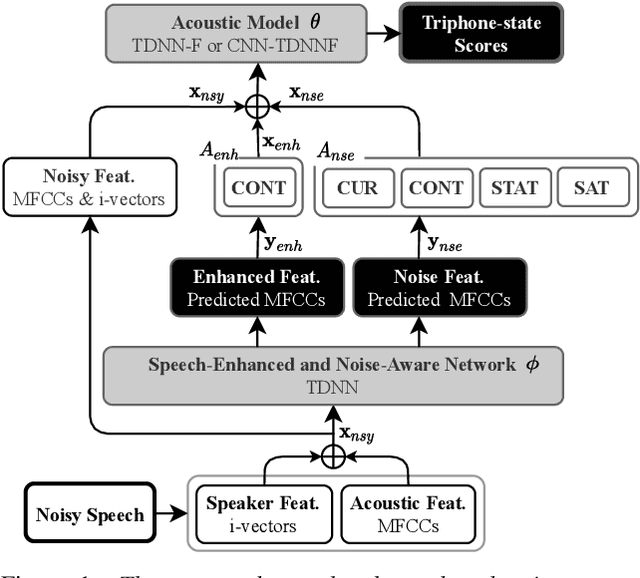
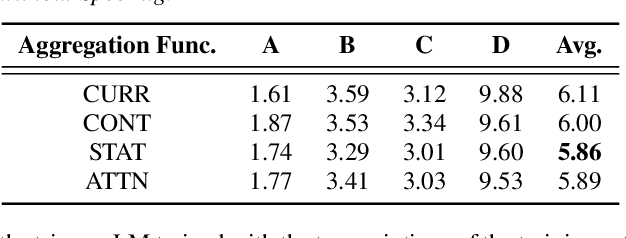
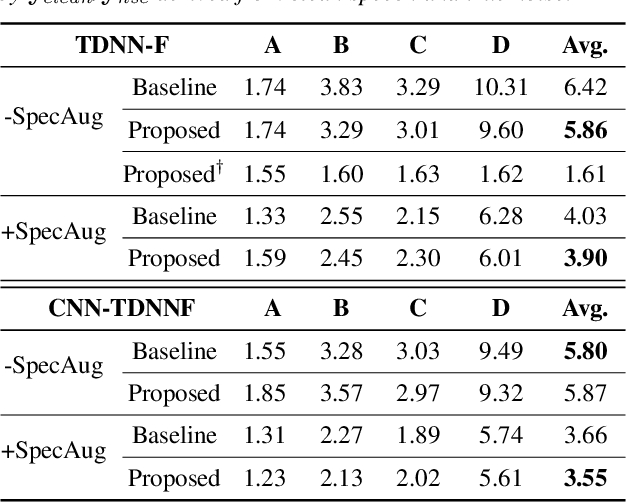
Compensation for channel mismatch and noise interference is essential for robust automatic speech recognition. Enhanced speech has been introduced into the multi-condition training of acoustic models to improve their generalization ability. In this paper, a noise-aware training framework based on two cascaded neural structures is proposed to jointly optimize speech enhancement and speech recognition. The feature enhancement module is composed of a multi-task autoencoder, where noisy speech is decomposed into clean speech and noise. By concatenating its enhanced, noise-aware, and noisy features for each frame, the acoustic-modeling module maps each feature-augmented frame into a triphone state by optimizing the lattice-free maximum mutual information and cross entropy between the predicted and actual state sequences. On top of the factorized time delay neural network (TDNN-F) and its convolutional variant (CNN-TDNNF), both with SpecAug, the two proposed systems achieve word error rate (WER) of 3.90% and 3.55%, respectively, on the Aurora-4 task. Compared with the best existing systems that use bigram and trigram language models for decoding, the proposed CNN-TDNNF-based system achieves a relative WER reduction of 15.20% and 33.53%, respectively. In addition, the proposed CNN-TDNNF-based system also outperforms the baseline CNN-TDNNF system on the AMI task.
Partially Fake Audio Detection by Self-attention-based Fake Span Discovery
Feb 15, 2022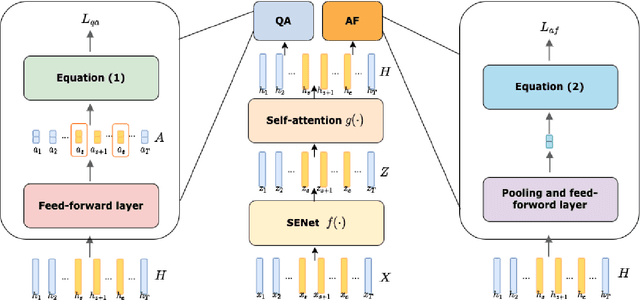
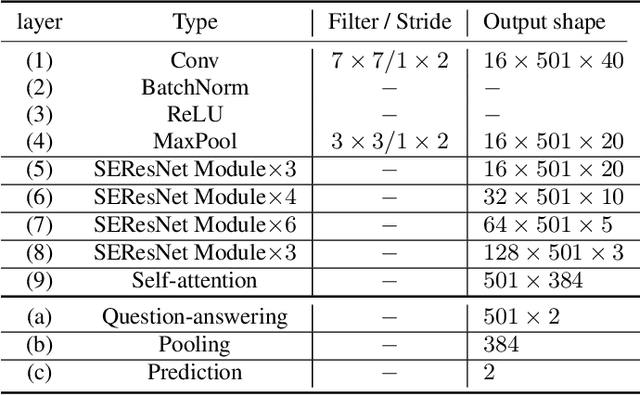

The past few years have witnessed the significant advances of speech synthesis and voice conversion technologies. However, such technologies can undermine the robustness of broadly implemented biometric identification models and can be harnessed by in-the-wild attackers for illegal uses. The ASVspoof challenge mainly focuses on synthesized audios by advanced speech synthesis and voice conversion models, and replay attacks. Recently, the first Audio Deep Synthesis Detection challenge (ADD 2022) extends the attack scenarios into more aspects. Also ADD 2022 is the first challenge to propose the partially fake audio detection task. Such brand new attacks are dangerous and how to tackle such attacks remains an open question. Thus, we propose a novel framework by introducing the question-answering (fake span discovery) strategy with the self-attention mechanism to detect partially fake audios. The proposed fake span detection module tasks the anti-spoofing model to predict the start and end positions of the fake clip within the partially fake audio, address the model's attention into discovering the fake spans rather than other shortcuts with less generalization, and finally equips the model with the discrimination capacity between real and partially fake audios. Our submission ranked second in the partially fake audio detection track of ADD 2022.
EMGSE: Acoustic/EMG Fusion for Multimodal Speech Enhancement
Feb 14, 2022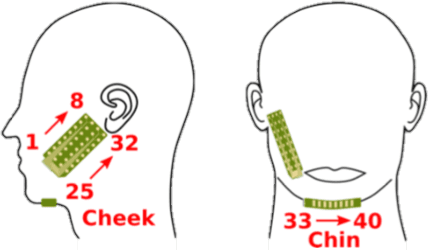
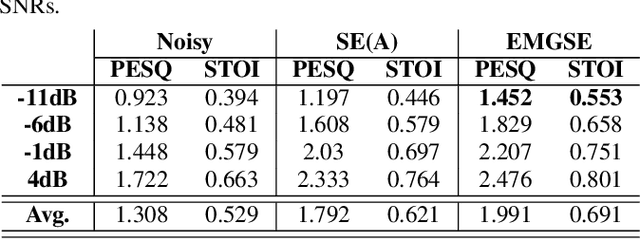
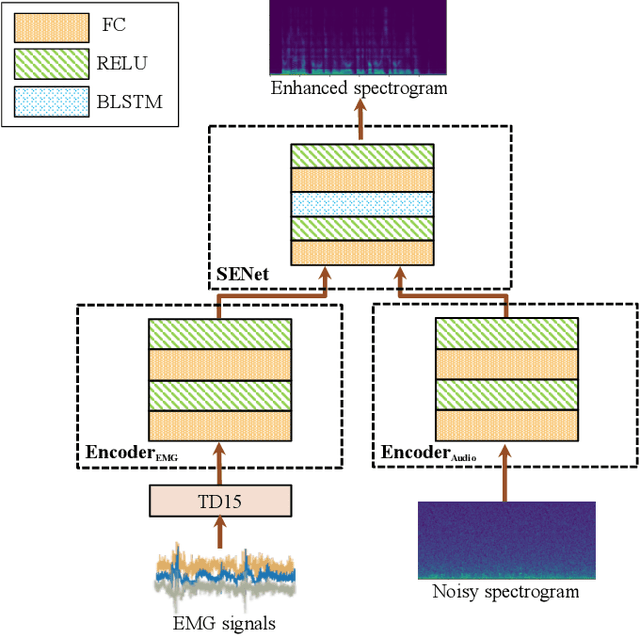
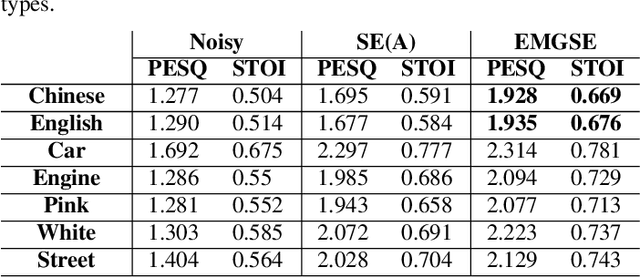
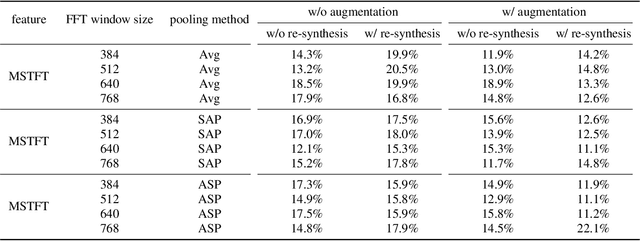
Multimodal learning has been proven to be an effective method to improve speech enhancement (SE) performance, especially in challenging situations such as low signal-to-noise ratios, speech noise, or unseen noise types. In previous studies, several types of auxiliary data have been used to construct multimodal SE systems, such as lip images, electropalatography, or electromagnetic midsagittal articulography. In this paper, we propose a novel EMGSE framework for multimodal SE, which integrates audio and facial electromyography (EMG) signals. Facial EMG is a biological signal containing articulatory movement information, which can be measured in a non-invasive way. Experimental results show that the proposed EMGSE system can achieve better performance than the audio-only SE system. The benefits of fusing EMG signals with acoustic signals for SE are notable under challenging circumstances. Furthermore, this study reveals that cheek EMG is sufficient for SE.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Dec 01, 2021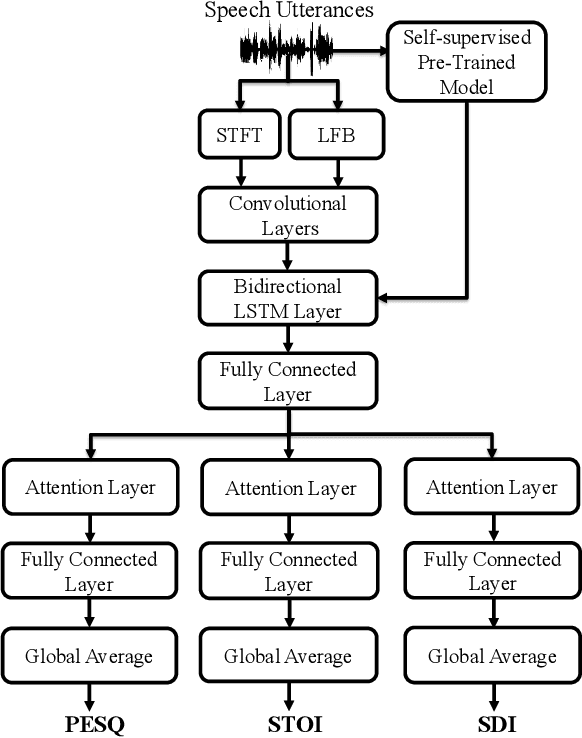
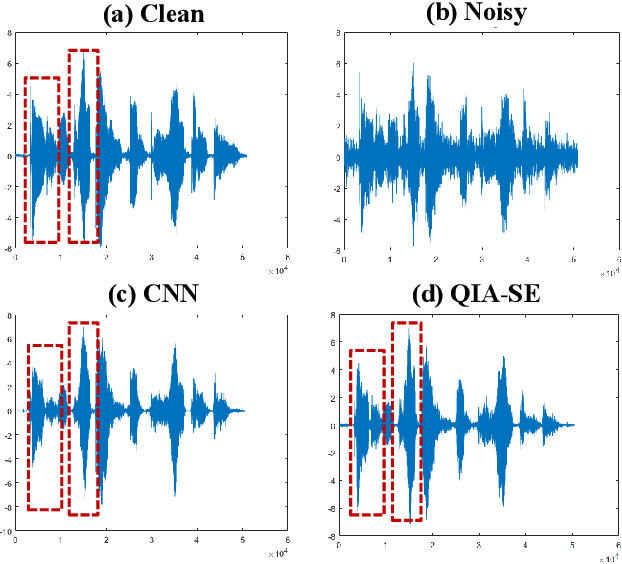
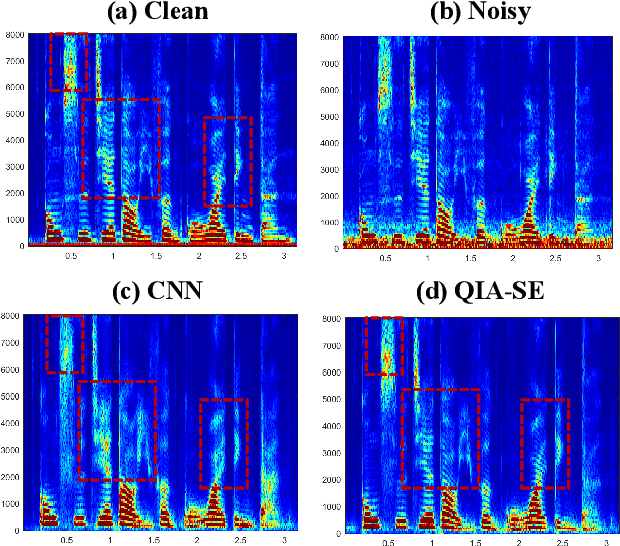
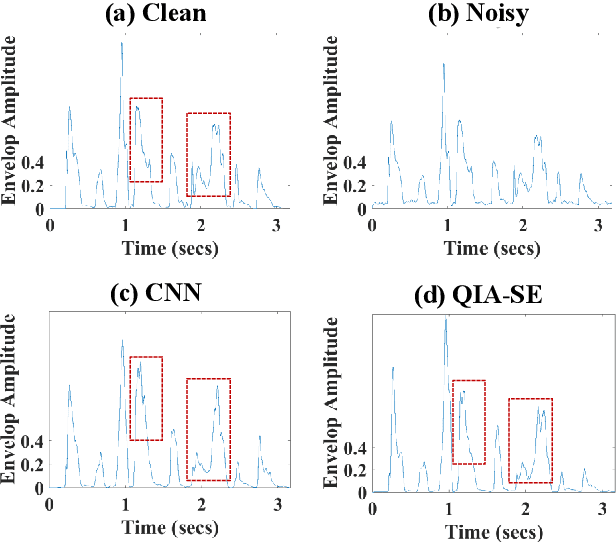
In this study, we propose a cross-domain multi-objective speech assessment model called MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, MOSA-Net is designed to estimate the speech quality, intelligibility, and distortion assessment scores of an input test speech signal. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, and a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results show that MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on noisy and enhanced speech utterances under either seen test conditions or unseen test conditions. Moreover, MOSA-Net, originally trained to assess objective scores, can be used as a pre-trained model to be effectively adapted to an assessment model for predicting subjective quality and intelligibility scores with a limited amount of training data. In light of the confirmed prediction capability, we further adopt the latent representations of MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
HASA-net: A non-intrusive hearing-aid speech assessment network
Nov 10, 2021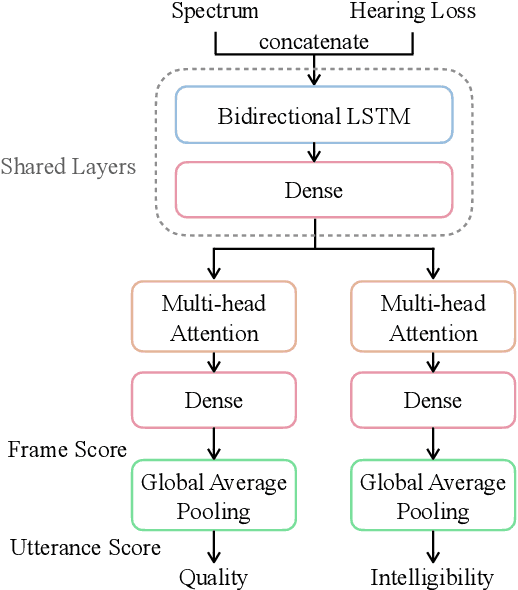
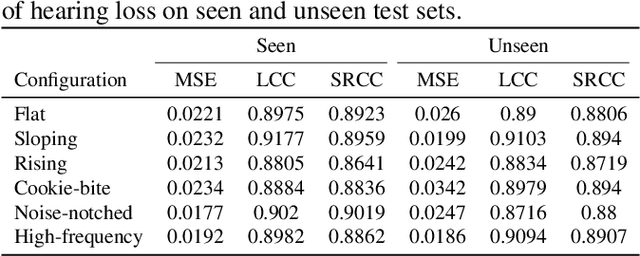
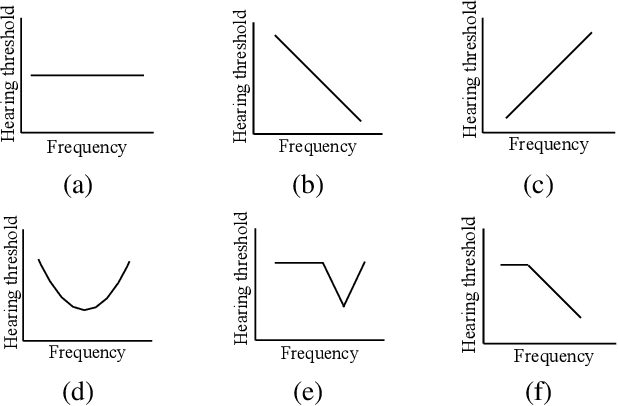
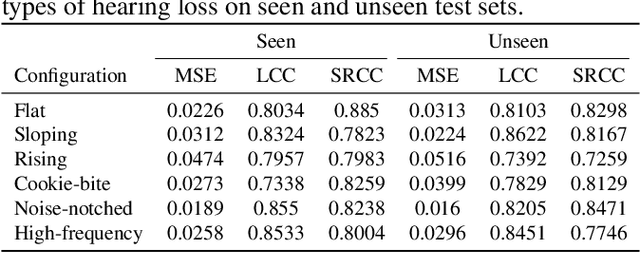
Without the need of a clean reference, non-intrusive speech assessment methods have caught great attention for objective evaluations. Recently, deep neural network (DNN) models have been applied to build non-intrusive speech assessment approaches and confirmed to provide promising performance. However, most DNN-based approaches are designed for normal-hearing listeners without considering hearing-loss factors. In this study, we propose a DNN-based hearing aid speech assessment network (HASA-Net), formed by a bidirectional long short-term memory (BLSTM) model, to predict speech quality and intelligibility scores simultaneously according to input speech signals and specified hearing-loss patterns. To the best of our knowledge, HASA-Net is the first work to incorporate quality and intelligibility assessments utilizing a unified DNN-based non-intrusive model for hearing aids. Experimental results show that the predicted speech quality and intelligibility scores of HASA-Net are highly correlated to two well-known intrusive hearing-aid evaluation metrics, hearing aid speech quality index (HASQI) and hearing aid speech perception index (HASPI), respectively.
Speech Enhancement-assisted Stargan Voice Conversion in Noisy Environments
Oct 19, 2021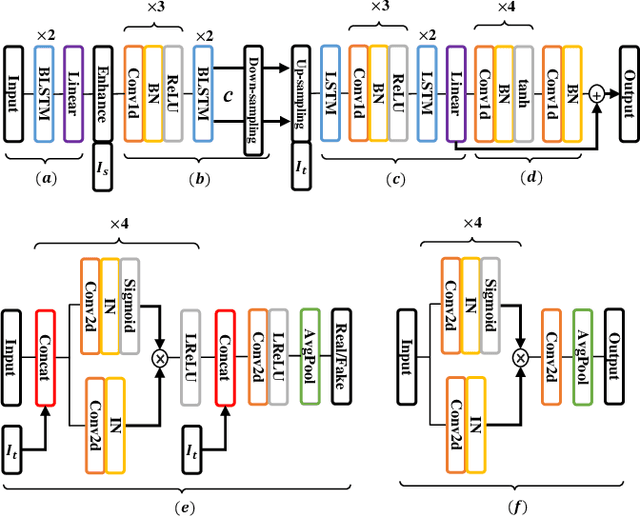

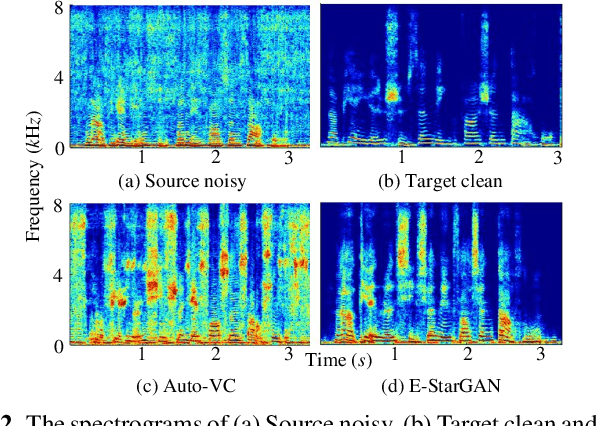
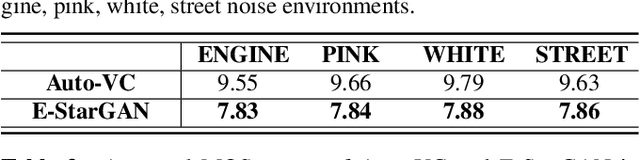
Numerous voice conversion (VC) techniques have been proposed for the conversion of voices among different speakers. Although the decent quality of converted speech can be observed when VC is applied in a clean environment, the quality will drop sharply when the system is running under noisy conditions. In order to address this issue, we propose a novel enhancement-based StarGAN (E-StarGAN) VC system, which leverages a speech enhancement (SE) technique for signal pre-processing. SE systems are generally used to reduce noise components in noisy speech and to generate enhanced speech for downstream application tasks. Therefore, we investigated the effectiveness of E-StarGAN, which combines VC and SE, and demonstrated the robustness of the proposed approach in various noisy environments. The results of VC experiments conducted on a Mandarin dataset show that when combined with SE, the proposed E-StarGAN VC model is robust to unseen noises. In addition, the subjective listening test results show that the proposed E-StarGAN model can improve the sound quality of speech signals converted from noise-corrupted source utterances.
Time Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021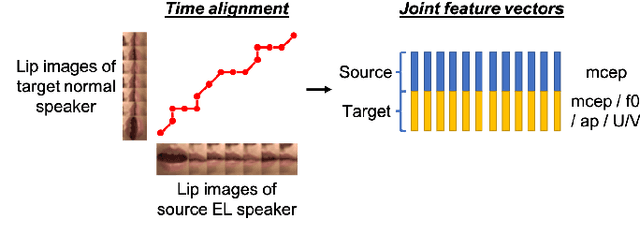
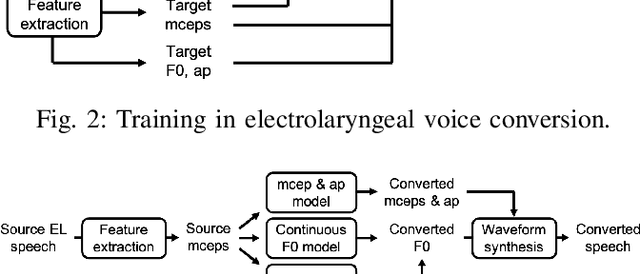
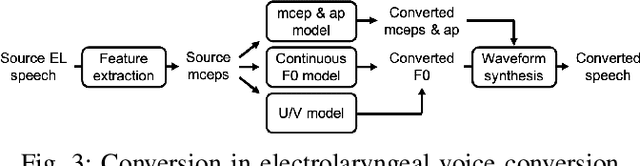
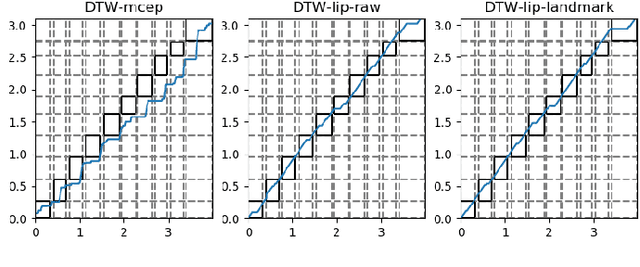
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.
SurpriseNet: Melody Harmonization Conditioning on User-controlled Surprise Contours
Aug 24, 2021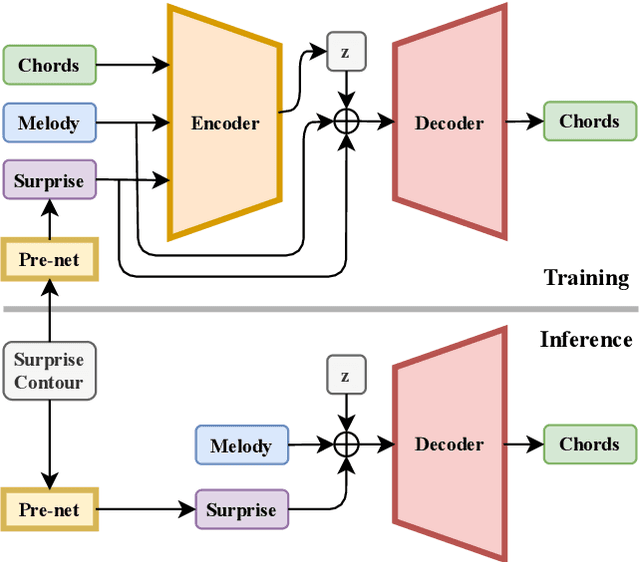
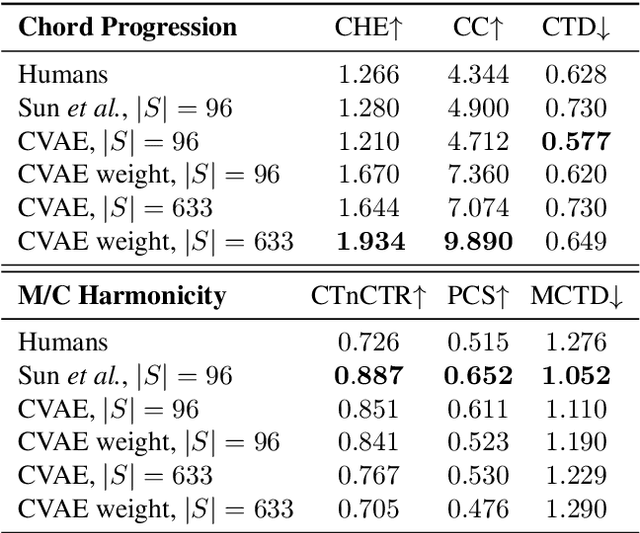
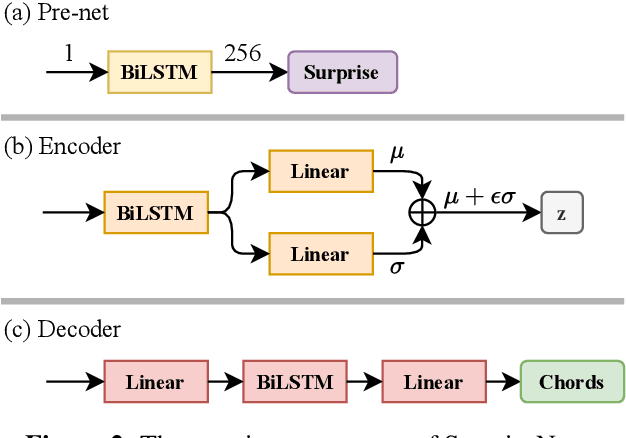

The surprisingness of a song is an essential and seemingly subjective factor in determining whether the listener likes it. With the help of information theory, it can be described as the transition probability of a music sequence modeled as a Markov chain. In this study, we introduce the concept of deriving entropy variations over time, so that the surprise contour of each chord sequence can be extracted. Based on this, we propose a user-controllable framework that uses a conditional variational autoencoder (CVAE) to harmonize the melody based on the given chord surprise indication. Through explicit conditions, the model can randomly generate various and harmonic chord progressions for a melody, and the Spearman's correlation and p-value significance show that the resulting chord progressions match the given surprise contour quite well. The vanilla CVAE model was evaluated in a basic melody harmonization task (no surprise control) in terms of six objective metrics. The results of experiments on the Hooktheory Lead Sheet Dataset show that our model achieves performance comparable to the state-of-the-art melody harmonization model.