 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Inference for Sparse Extreme Multi-Label Ranking Trees
Jun 09, 2021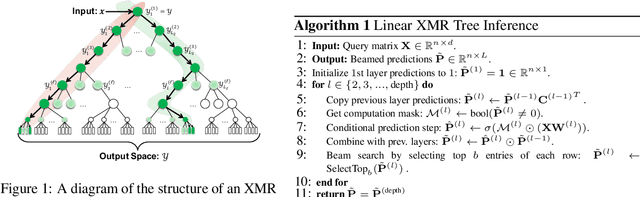

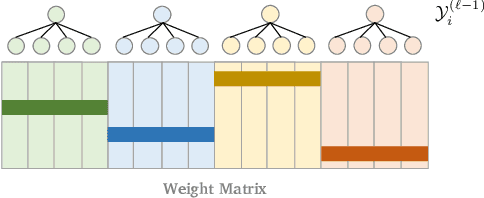
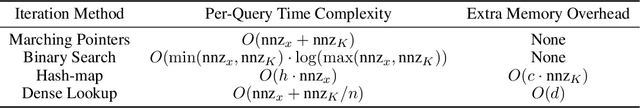
Tree-based models underpin many modern semantic search engines and recommender systems due to their sub-linear inference times. In industrial applications, these models operate at extreme scales, where every bit of performance is critical. Memory constraints at extreme scales also require that models be sparse, hence tree-based models are often back-ended by sparse matrix algebra routines. However, there are currently no sparse matrix techniques specifically designed for the sparsity structure one encounters in tree-based models for extreme multi-label ranking/classification (XMR/XMC) problems. To address this issue, we present the masked sparse chunk multiplication (MSCM) technique, a sparse matrix technique specifically tailored to XMR trees. MSCM is easy to implement, embarrassingly parallelizable, and offers a significant performance boost to any existing tree inference pipeline at no cost. We perform a comprehensive study of MSCM applied to several different sparse inference schemes and benchmark our methods on a general purpose extreme multi-label ranking framework. We observe that MSCM gives consistently dramatic speedups across both the online and batch inference settings, single- and multi-threaded settings, and on many different tree models and datasets. To demonstrate its utility in industrial applications, we apply MSCM to an enterprise-scale semantic product search problem with 100 million products and achieve sub-millisecond latency of 0.88 ms per query on a single thread -- an 8x reduction in latency over vanilla inference techniques. The MSCM technique requires absolutely no sacrifices to model accuracy as it gives exactly the same results as standard sparse matrix techniques. Therefore, we believe that MSCM will enable users of XMR trees to save a substantial amount of compute resources in their inference pipelines at very little cost.
PECOS: Prediction for Enormous and Correlated Output Spaces
Oct 12, 2020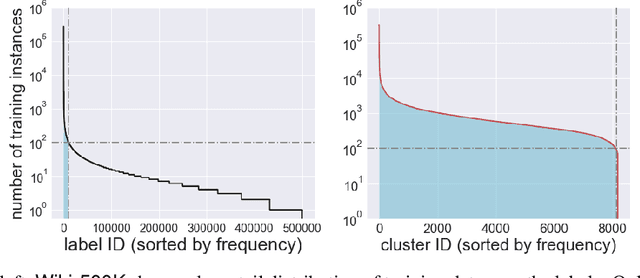
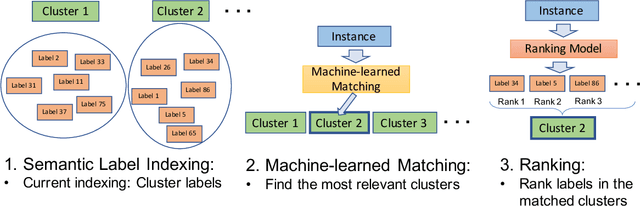

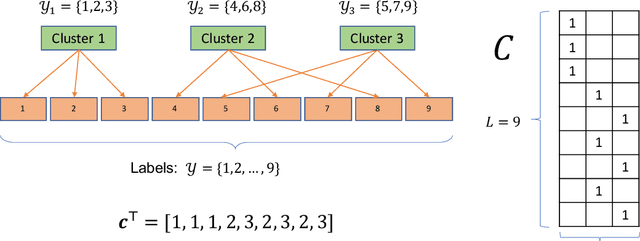
Many challenging problems in modern applications amount to finding relevant results from an enormous output space of potential candidates. The size of the output space for these problems can range from millions to billions. Moreover, training data is often limited for many of the so-called ``long-tail'' of items in the output space. Given the inherent paucity of training data for most of the items in the output space, developing machine learned models that perform well for spaces of this size is challenging. Fortunately, items in the output space are often correlated thereby presenting an opportunity to alleviate the data sparsity issue. In this paper, we propose the Prediction for Enormous and Correlated Output Spaces (PECOS) framework, a versatile and modular machine learning framework for solving prediction problems for very large output spaces, and apply it to the eXtreme Multilabel Ranking (XMR) problem: given an input instance, find and rank the most relevant items from an enormous but fixed and finite output space. PECOS is a three-phase framework: (i) in the first phase, PECOS organizes the output space using a semantic indexing scheme, (ii) in the second phase, PECOS uses the indexing to narrow down the output space by orders of magnitude using a machine learned matching scheme, and (iii) in the third phase, PECOS ranks the matched items using a final ranking scheme. The versatility and modularity of PECOS allows for easy plug-and-play of various choices for the indexing, matching, and ranking phases. On a dataset where the output space is of size 2.8 million, PECOS with a neural matcher results in a 10% increase in precision@1 (from 46% to 51.2%) over PECOS with a recursive linear matcher but takes 265x more time to train. We also develop fast real time inference procedures; for example, inference takes less than 10 milliseconds on the data set with 2.8 million labels.
Learning to Encode Position for Transformer with Continuous Dynamical Model
Mar 13, 2020
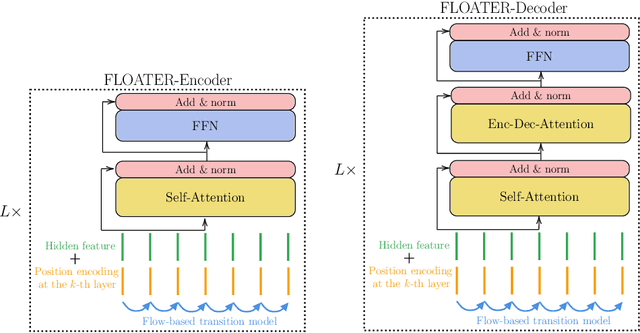
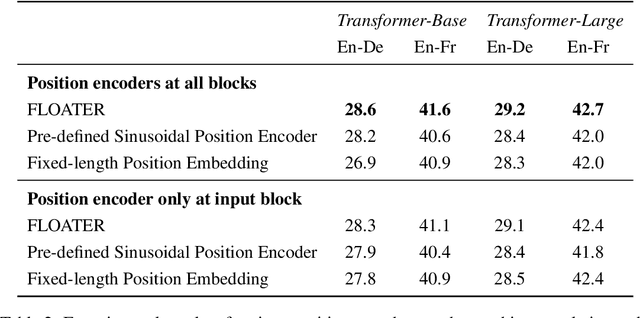
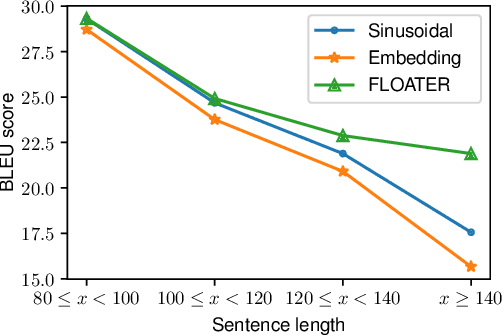
We introduce a new way of learning to encode position information for non-recurrent models, such as Transformer models. Unlike RNN and LSTM, which contain inductive bias by loading the input tokens sequentially, non-recurrent models are less sensitive to position. The main reason is that position information among input units is not inherently encoded, i.e., the models are permutation equivalent; this problem justifies why all of the existing models are accompanied by a sinusoidal encoding/embedding layer at the input. However, this solution has clear limitations: the sinusoidal encoding is not flexible enough as it is manually designed and does not contain any learnable parameters, whereas the position embedding restricts the maximum length of input sequences. It is thus desirable to design a new position layer that contains learnable parameters to adjust to different datasets and different architectures. At the same time, we would also like the encodings to extrapolate in accordance with the variable length of inputs. In our proposed solution, we borrow from the recent Neural ODE approach, which may be viewed as a versatile continuous version of a ResNet. This model is capable of modeling many kinds of dynamical systems. We model the evolution of encoded results along position index by such a dynamical system, thereby overcoming the above limitations of existing methods. We evaluate our new position layers on a variety of neural machine translation and language understanding tasks, the experimental results show consistent improvements over the baselines.
Multiresolution Transformer Networks: Recurrence is Not Essential for Modeling Hierarchical Structure
Aug 27, 2019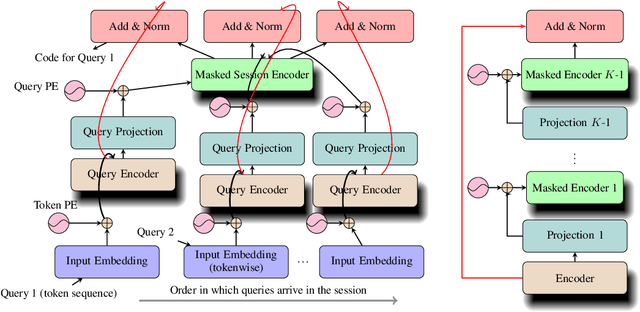

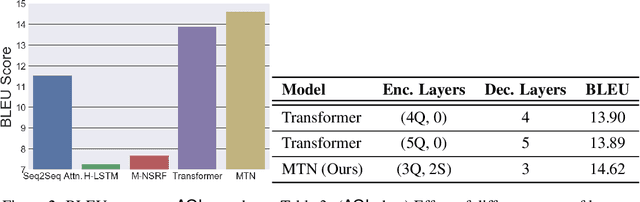
The architecture of Transformer is based entirely on self-attention, and has been shown to outperform models that employ recurrence on sequence transduction tasks such as machine translation. The superior performance of Transformer has been attributed to propagating signals over shorter distances, between positions in the input and the output, compared to the recurrent architectures. We establish connections between the dynamics in Transformer and recurrent networks to argue that several factors including gradient flow along an ensemble of multiple weakly dependent paths play a paramount role in the success of Transformer. We then leverage the dynamics to introduce {\em Multiresolution Transformer Networks} as the first architecture that exploits hierarchical structure in data via self-attention. Our models significantly outperform state-of-the-art recurrent and hierarchical recurrent models on two real-world datasets for query suggestion, namely, \aol and \amazon. In particular, on AOL data, our model registers at least 20\% improvement on each precision score, and over 25\% improvement on the BLEU score with respect to the best performing recurrent model. We thus provide strong evidence that recurrence is not essential for modeling hierarchical structure.
Graph DNA: Deep Neighborhood Aware Graph Encoding for Collaborative Filtering
May 29, 2019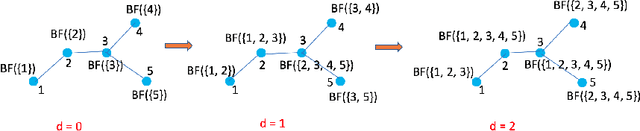
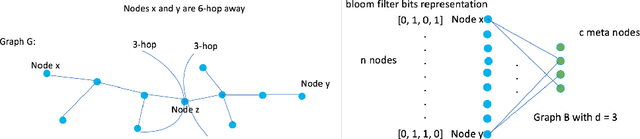

In this paper, we consider recommender systems with side information in the form of graphs. Existing collaborative filtering algorithms mainly utilize only immediate neighborhood information and have a hard time taking advantage of deeper neighborhoods beyond 1-2 hops. The main caveat of exploiting deeper graph information is the rapidly growing time and space complexity when incorporating information from these neighborhoods. In this paper, we propose using Graph DNA, a novel Deep Neighborhood Aware graph encoding algorithm, for exploiting deeper neighborhood information. DNA encoding computes approximate deep neighborhood information in linear time using Bloom filters, a space-efficient probabilistic data structure and results in a per-node encoding that is logarithmic in the number of nodes in the graph. It can be used in conjunction with both feature-based and graph-regularization-based collaborative filtering algorithms. Graph DNA has the advantages of being memory and time efficient and providing additional regularization when compared to directly using higher order graph information. We conduct experiments on real-world datasets, showing graph DNA can be easily used with 4 popular collaborative filtering algorithms and consistently leads to a performance boost with little computational and memory overhead.
Think Globally, Act Locally: A Deep Neural Network Approach to High-Dimensional Time Series Forecasting
May 09, 2019
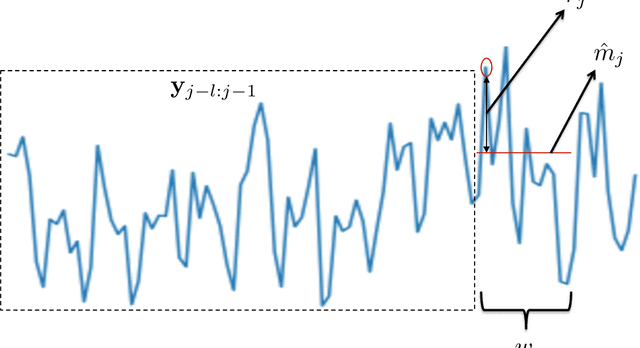

Forecasting high-dimensional time series plays a crucial role in many applications such as demand forecasting and financial predictions. Modern real-world datasets can have millions of correlated time-series that evolve together, i.e they are extremely high dimensional (one dimension for each individual time-series). Thus there is need for exploiting these global patterns and coupling them with local calibration for better prediction. However, most recent deep learning approaches in the literature are one-dimensional, i.e, even though they are trained on the whole dataset, during prediction, the future forecast for a single dimension mainly depends on past values from the same dimension. In this paper, we seek to correct this deficiency and propose DeepGLO, a deep forecasting model which thinks globally and acts locally. In particular, DeepGLO is a hybrid model that combines a global matrix factorization model regularized by a temporal deep network with a local deep temporal model that captures patterns specific to each dimension. The global and local models are combined via a data-driven attention mechanism for each dimension. The proposed deep architecture used is a variation of temporal convolution termed as leveled network which can be trained effectively on high-dimensional but diverse time series, where different time series can have vastly different scales, without a priori normalization or rescaling. Empirical results demonstrate that DeepGLO outperforms state-of-the-art approaches on various datasets; for example, we see more than 30% improvement in WAPE over other methods on a real-world dataset that contains more than 100K-dimensional time series.
A Modular Deep Learning Approach for Extreme Multi-label Text Classification
May 07, 2019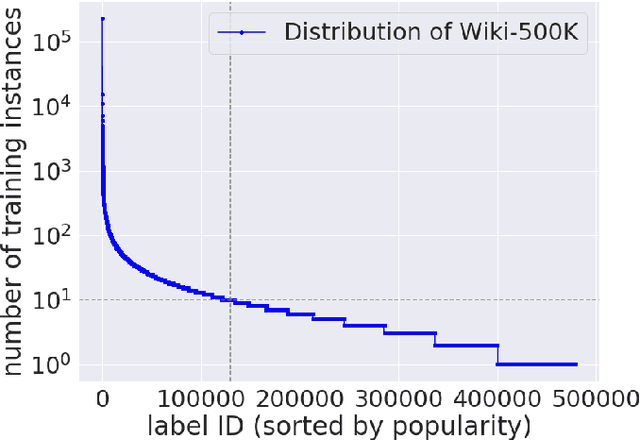

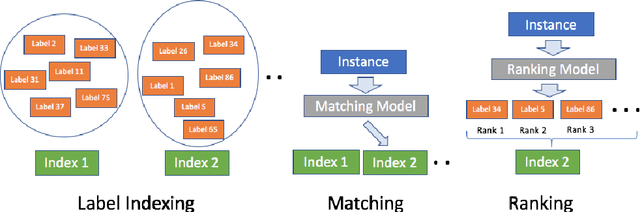
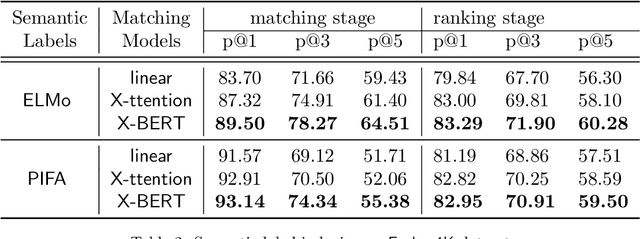
Extreme multi-label classification (XMC) aims to assign to an instance the most relevant subset of labels from a colossal label set. Due to modern applications that lead to massive label sets, the scalability of XMC has attracted much recent attention from both academia and industry. In this paper, we establish a three-stage framework to solve XMC efficiently, which includes 1) indexing the labels, 2) matching the instance to the relevant indices, and 3) ranking the labels from the relevant indices. This framework unifies many existing XMC approaches. Based on this framework, we propose a modular deep learning approach SLINMER: Semantic Label Indexing, Neural Matching, and Efficient Ranking. The label indexing stage of SLINMER can adopt different semantic label representations leading to different configurations of SLINMER. Empirically, we demonstrate that several individual configurations of SLINMER achieve superior performance than the state-of-the-art XMC approaches on several benchmark datasets. Moreover, by ensembling those configurations, SLINMER can achieve even better results. In particular, on a Wiki dataset with around 0.5 millions of labels, the precision@1 is increased from 61% to 67%.
Extreme Stochastic Variational Inference: Distributed and Asynchronous
Aug 03, 2018
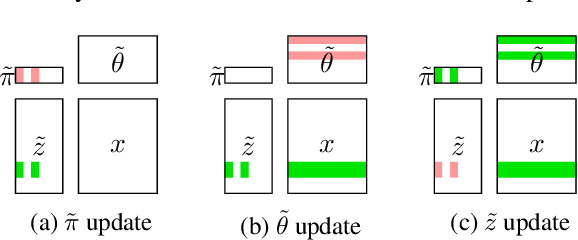
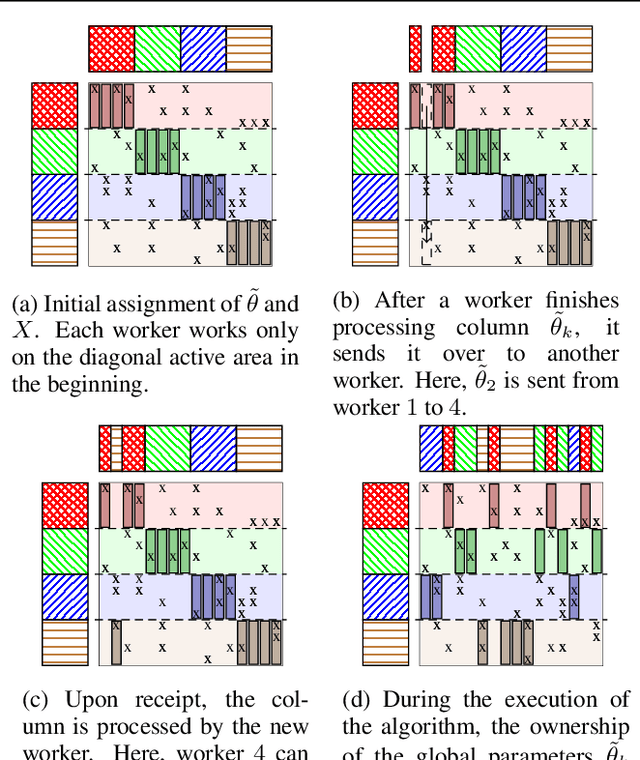
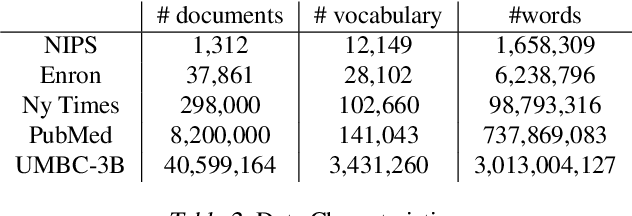
Stochastic variational inference (SVI), the state-of-the-art algorithm for scaling variational inference to large-datasets, is inherently serial. Moreover, it requires the parameters to fit in the memory of a single processor; this is problematic when the number of parameters is in billions. In this paper, we propose extreme stochastic variational inference (ESVI), an asynchronous and lock-free algorithm to perform variational inference for mixture models on massive real world datasets. ESVI overcomes the limitations of SVI by requiring that each processor only access a subset of the data and a subset of the parameters, thus providing data and model parallelism simultaneously. We demonstrate the effectiveness of ESVI by running Latent Dirichlet Allocation (LDA) on UMBC-3B, a dataset that has a vocabulary of 3 million and a token size of 3 billion. In our experiments, we found that ESVI not only outperforms VI and SVI in wallclock-time, but also achieves a better quality solution. In addition, we propose a strategy to speed up computation and save memory when fitting large number of topics.
LearningWord Embeddings for Low-resource Languages by PU Learning
May 09, 2018
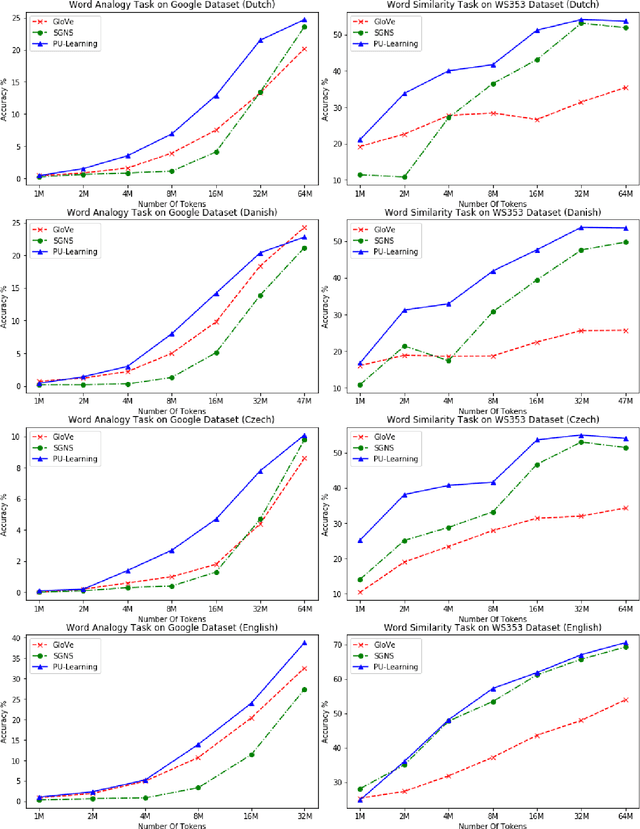

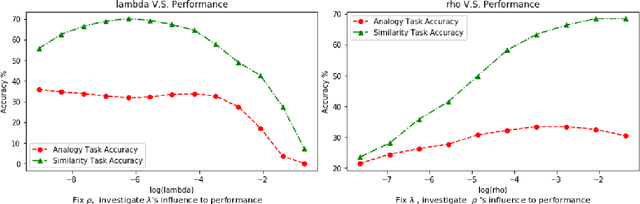
Word embedding is a key component in many downstream applications in processing natural languages. Existing approaches often assume the existence of a large collection of text for learning effective word embedding. However, such a corpus may not be available for some low-resource languages. In this paper, we study how to effectively learn a word embedding model on a corpus with only a few million tokens. In such a situation, the co-occurrence matrix is sparse as the co-occurrences of many word pairs are unobserved. In contrast to existing approaches often only sample a few unobserved word pairs as negative samples, we argue that the zero entries in the co-occurrence matrix also provide valuable information. We then design a Positive-Unlabeled Learning (PU-Learning) approach to factorize the co-occurrence matrix and validate the proposed approaches in four different languages.
A Greedy Approach for Budgeted Maximum Inner Product Search
Oct 11, 2016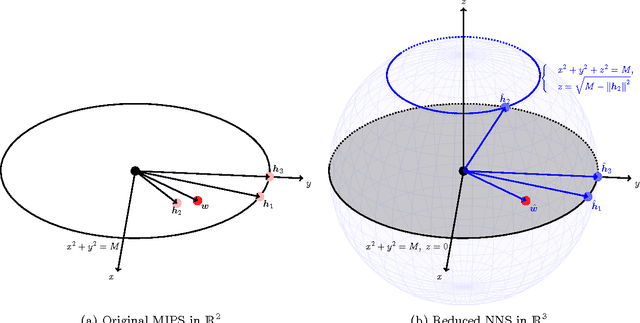
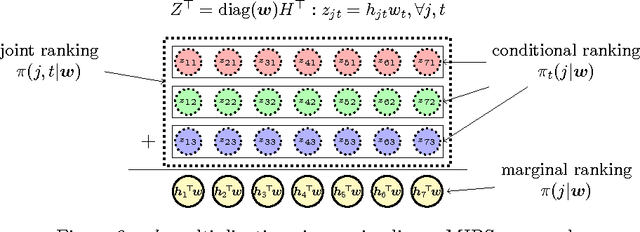
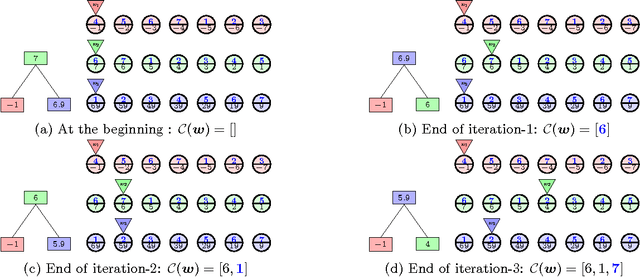
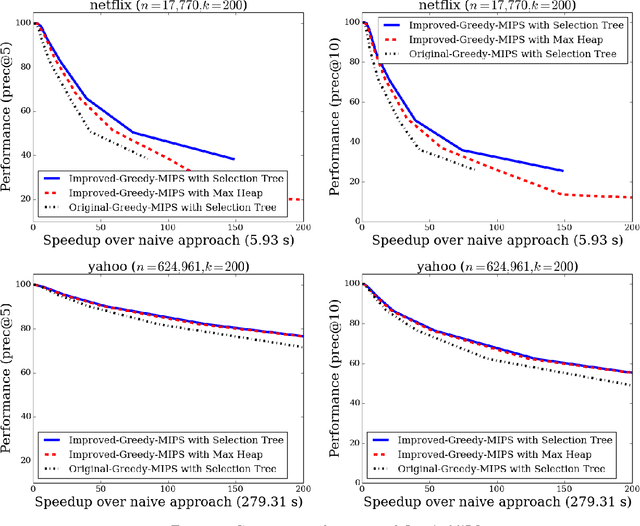
Maximum Inner Product Search (MIPS) is an important task in many machine learning applications such as the prediction phase of a low-rank matrix factorization model for a recommender system. There have been some works on how to perform MIPS in sub-linear time recently. However, most of them do not have the flexibility to control the trade-off between search efficient and search quality. In this paper, we study the MIPS problem with a computational budget. By carefully studying the problem structure of MIPS, we develop a novel Greedy-MIPS algorithm, which can handle budgeted MIPS by design. While simple and intuitive, Greedy-MIPS yields surprisingly superior performance compared to state-of-the-art approaches. As a specific example, on a candidate set containing half a million vectors of dimension 200, Greedy-MIPS runs 200x faster than the naive approach while yielding search results with the top-5 precision greater than 75\%.