 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePECOS: Prediction for Enormous and Correlated Output Spaces
Paper and Code
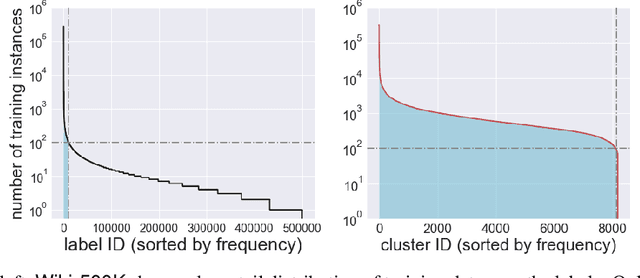
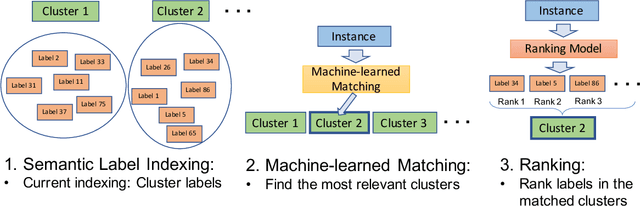

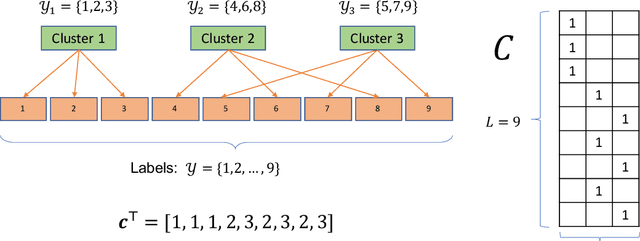
Many challenging problems in modern applications amount to finding relevant results from an enormous output space of potential candidates. The size of the output space for these problems can range from millions to billions. Moreover, training data is often limited for many of the so-called ``long-tail'' of items in the output space. Given the inherent paucity of training data for most of the items in the output space, developing machine learned models that perform well for spaces of this size is challenging. Fortunately, items in the output space are often correlated thereby presenting an opportunity to alleviate the data sparsity issue. In this paper, we propose the Prediction for Enormous and Correlated Output Spaces (PECOS) framework, a versatile and modular machine learning framework for solving prediction problems for very large output spaces, and apply it to the eXtreme Multilabel Ranking (XMR) problem: given an input instance, find and rank the most relevant items from an enormous but fixed and finite output space. PECOS is a three-phase framework: (i) in the first phase, PECOS organizes the output space using a semantic indexing scheme, (ii) in the second phase, PECOS uses the indexing to narrow down the output space by orders of magnitude using a machine learned matching scheme, and (iii) in the third phase, PECOS ranks the matched items using a final ranking scheme. The versatility and modularity of PECOS allows for easy plug-and-play of various choices for the indexing, matching, and ranking phases. On a dataset where the output space is of size 2.8 million, PECOS with a neural matcher results in a 10% increase in precision@1 (from 46% to 51.2%) over PECOS with a recursive linear matcher but takes 265x more time to train. We also develop fast real time inference procedures; for example, inference takes less than 10 milliseconds on the data set with 2.8 million labels.