 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Universal Image Attractiveness Ranking Framework
Sep 19, 2018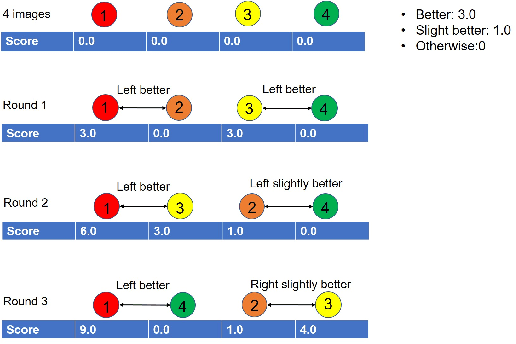
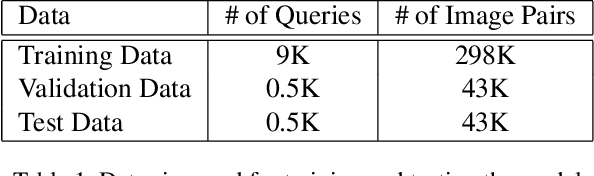

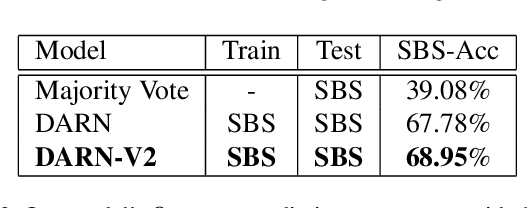
We propose a new framework to rank image attractiveness using a novel pairwise deep network trained with a large set of side-by-side multi-labeled image pairs from a web image index. The judges only provide relative ranking between two images without the need to directly assign an absolute score, or rate any predefined image attribute, thus making the rating more intuitive and straightforward. We investigate a deep attractiveness rank net (DARN), a combination of deep convolutional neural network and rank net, to directly learn an attractiveness score mean and variance for each image and the underlying criteria the judges use to label each pair. The extension of this model (DARN-V2) is able to adapt to individual judge's personal preference. We also show the attractiveness of search results are significantly improved by using this attractiveness information in a real commercial search engine. We evaluate our model against other state-of-the-art models on our side-by-side web test data and another public aesthetic data set. Our model outperforms on side-by-side labeled data, and is competitive on data labeled by absolute score.
Stacked Cross Attention for Image-Text Matching
Jul 23, 2018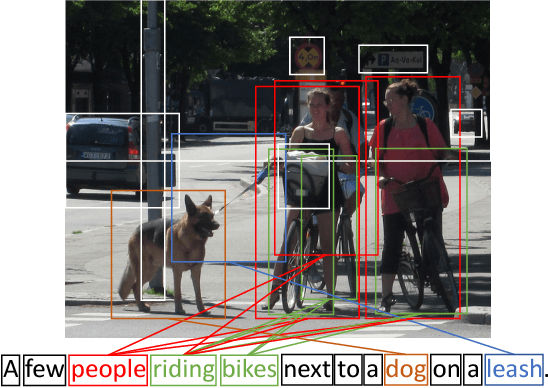
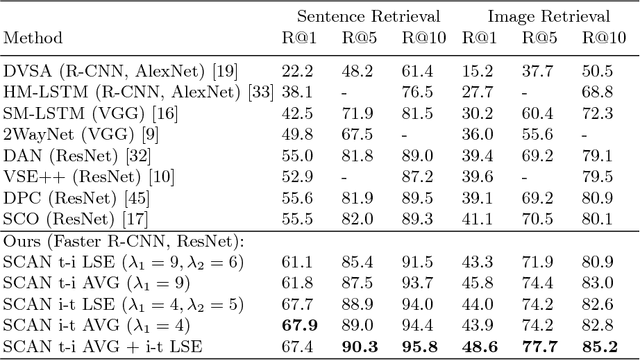
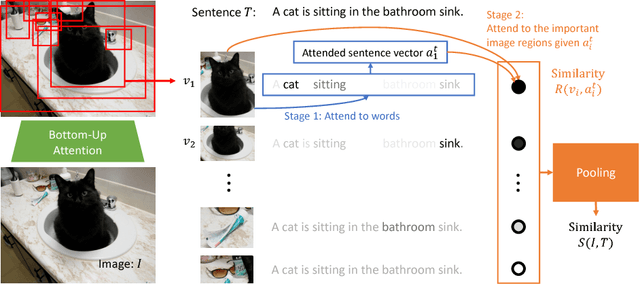
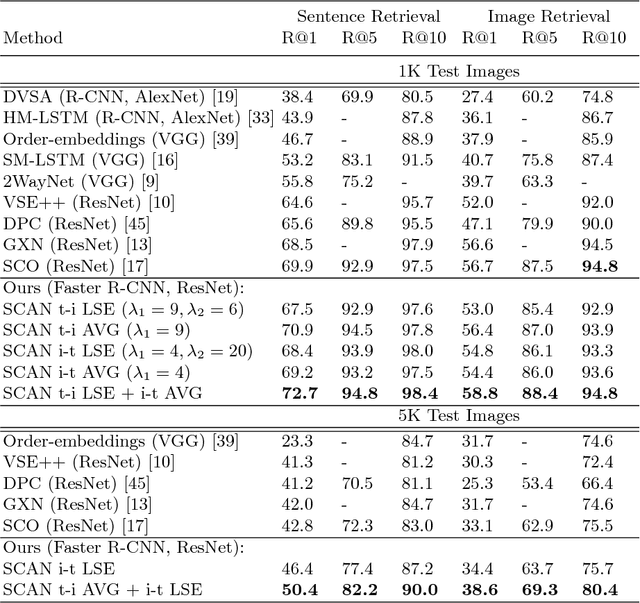
In this paper, we study the problem of image-text matching. Inferring the latent semantic alignment between objects or other salient stuff (e.g. snow, sky, lawn) and the corresponding words in sentences allows to capture fine-grained interplay between vision and language, and makes image-text matching more interpretable. Prior work either simply aggregates the similarity of all possible pairs of regions and words without attending differentially to more and less important words or regions, or uses a multi-step attentional process to capture limited number of semantic alignments which is less interpretable. In this paper, we present Stacked Cross Attention to discover the full latent alignments using both image regions and words in a sentence as context and infer image-text similarity. Our approach achieves the state-of-the-art results on the MS-COCO and Flickr30K datasets. On Flickr30K, our approach outperforms the current best methods by 22.1% relatively in text retrieval from image query, and 18.2% relatively in image retrieval with text query (based on Recall@1). On MS-COCO, our approach improves sentence retrieval by 17.8% relatively and image retrieval by 16.6% relatively (based on Recall@1 using the 5K test set). Code has been made available at: https://github.com/kuanghuei/SCAN.
Web-Scale Responsive Visual Search at Bing
Feb 20, 2018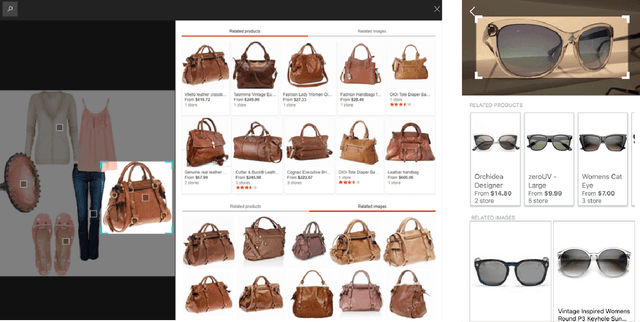
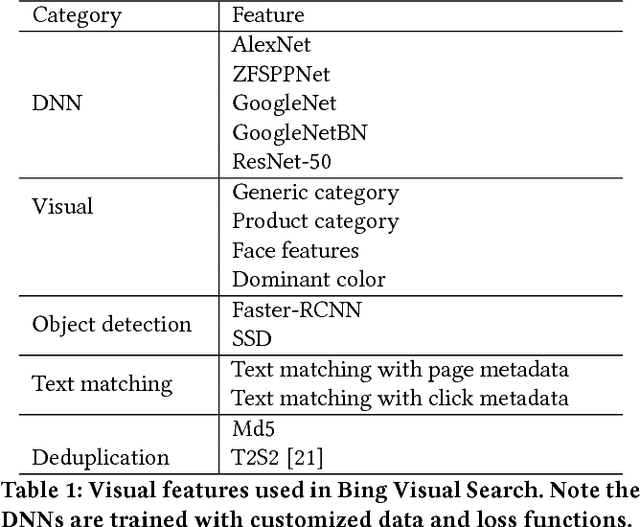
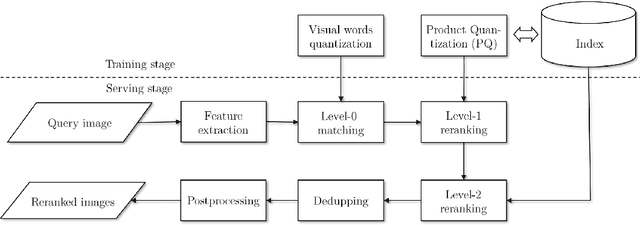

In this paper, we introduce a web-scale general visual search system deployed in Microsoft Bing. The system accommodates tens of billions of images in the index, with thousands of features for each image, and can respond in less than 200 ms. In order to overcome the challenges in relevance, latency, and scalability in such large scale of data, we employ a cascaded learning-to-rank framework based on various latest deep learning visual features, and deploy in a distributed heterogeneous computing platform. Quantitative and qualitative experiments show that our system is able to support various applications on Bing website and apps.