 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxViT: Multi-Axis Vision Transformer
Apr 04, 2022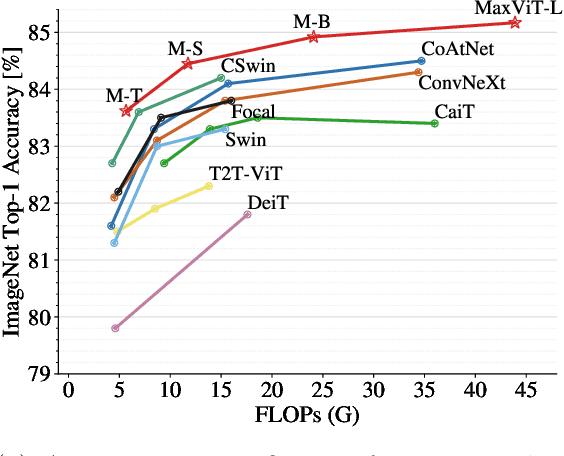

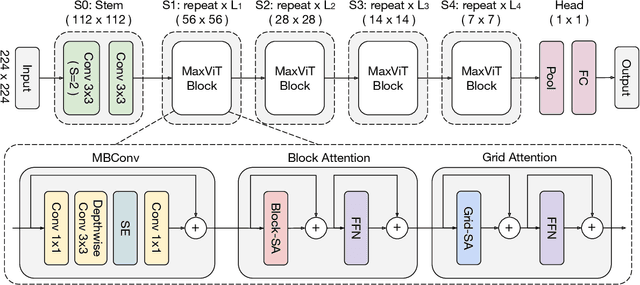
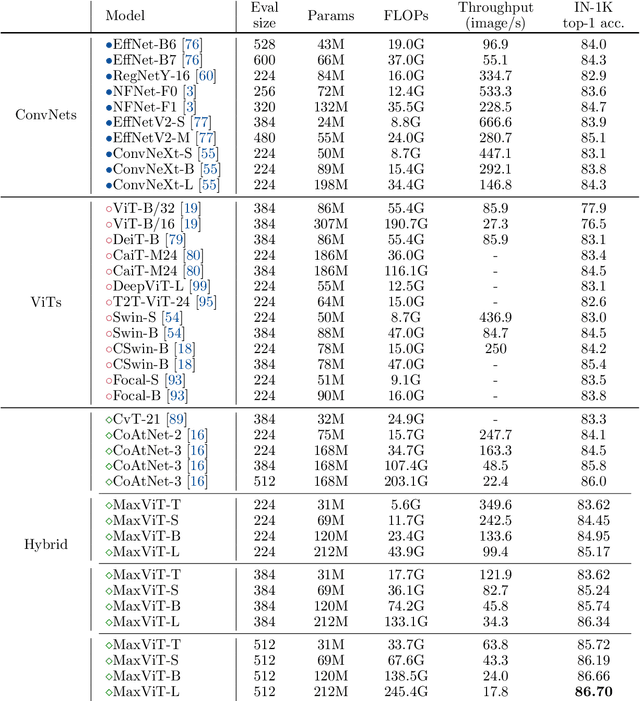
Transformers have recently gained significant attention in the computer vision community. However, the lack of scalability of self-attention mechanisms with respect to image size has limited their wide adoption in state-of-the-art vision backbones. In this paper we introduce an efficient and scalable attention model we call multi-axis attention, which consists of two aspects: blocked local and dilated global attention. These design choices allow global-local spatial interactions on arbitrary input resolutions with only linear complexity. We also present a new architectural element by effectively blending our proposed attention model with convolutions, and accordingly propose a simple hierarchical vision backbone, dubbed MaxViT, by simply repeating the basic building block over multiple stages. Notably, MaxViT is able to "see" globally throughout the entire network, even in earlier, high-resolution stages. We demonstrate the effectiveness of our model on a broad spectrum of vision tasks. On image classification, MaxViT achieves state-of-the-art performance under various settings: without extra data, MaxViT attains 86.5\% ImageNet-1K top-1 accuracy; with ImageNet-21K pre-training, our model achieves 88.7\% top-1 accuracy. For downstream tasks, MaxViT as a backbone delivers favorable performance on object detection as well as visual aesthetic assessment. We also show that our proposed model expresses strong generative modeling capability on ImageNet, demonstrating the superior potential of MaxViT blocks as a universal vision module. We will make the code and models publicly available.
MAXIM: Multi-Axis MLP for Image Processing
Jan 09, 2022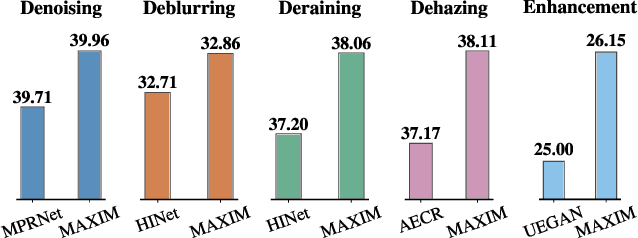
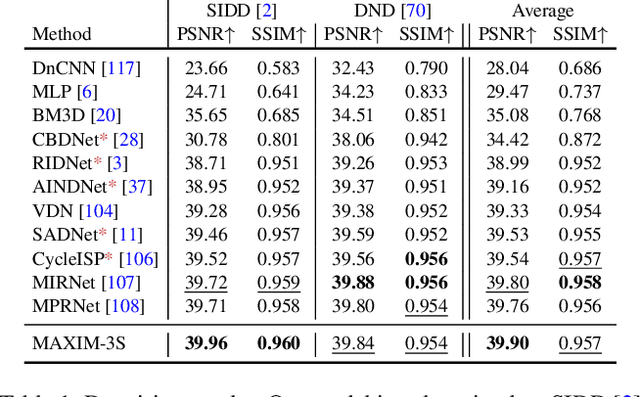
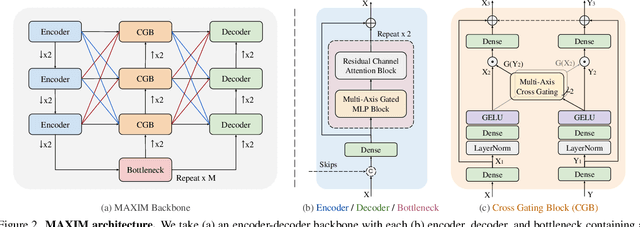
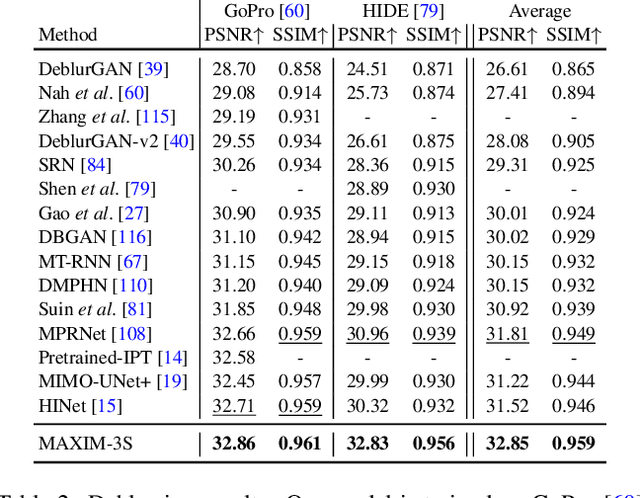
Recent progress on Transformers and multi-layer perceptron (MLP) models provide new network architectural designs for computer vision tasks. Although these models proved to be effective in many vision tasks such as image recognition, there remain challenges in adapting them for low-level vision. The inflexibility to support high-resolution images and limitations of local attention are perhaps the main bottlenecks for using Transformers and MLPs in image restoration. In this work we present a multi-axis MLP based architecture, called MAXIM, that can serve as an efficient and flexible general-purpose vision backbone for image processing tasks. MAXIM uses a UNet-shaped hierarchical structure and supports long-range interactions enabled by spatially-gated MLPs. Specifically, MAXIM contains two MLP-based building blocks: a multi-axis gated MLP that allows for efficient and scalable spatial mixing of local and global visual cues, and a cross-gating block, an alternative to cross-attention, which accounts for cross-feature mutual conditioning. Both these modules are exclusively based on MLPs, but also benefit from being both global and `fully-convolutional', two properties that are desirable for image processing. Our extensive experimental results show that the proposed MAXIM model achieves state-of-the-art performance on more than ten benchmarks across a range of image processing tasks, including denoising, deblurring, deraining, dehazing, and enhancement while requiring fewer or comparable numbers of parameters and FLOPs than competitive models.
Deblurring via Stochastic Refinement
Dec 28, 2021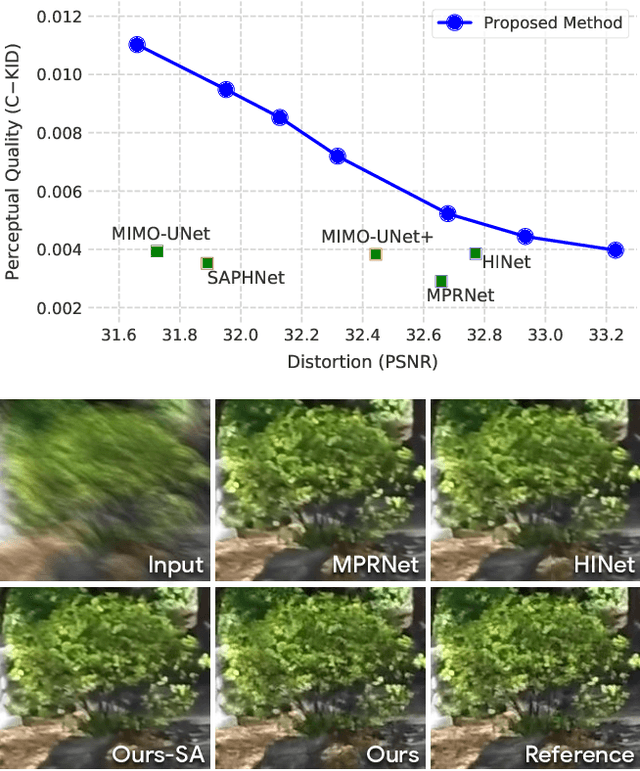
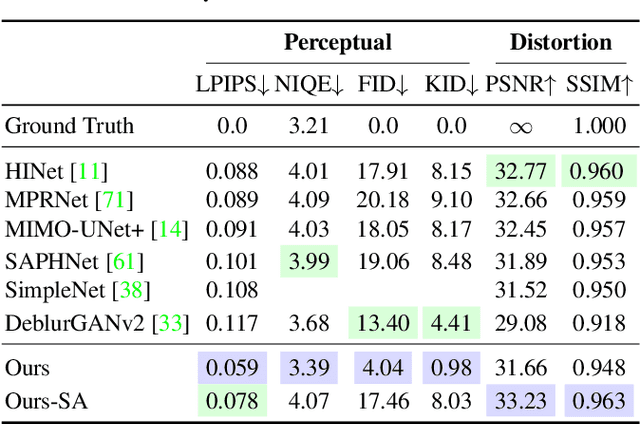
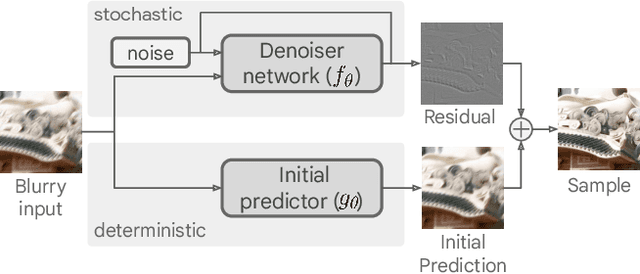

Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
Exponentiated Gradient Reweighting for Robust Training Under Label Noise and Beyond
Apr 03, 2021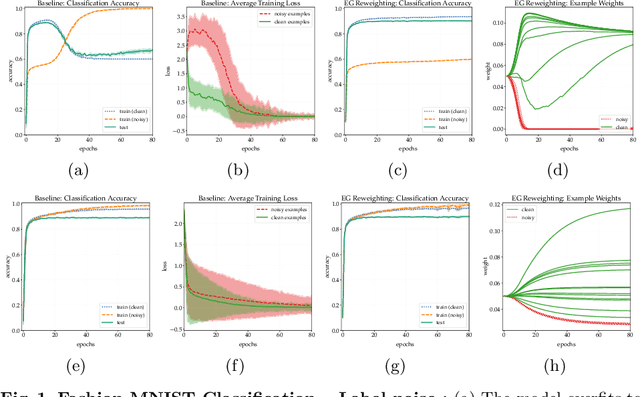
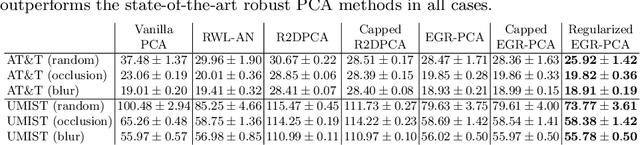
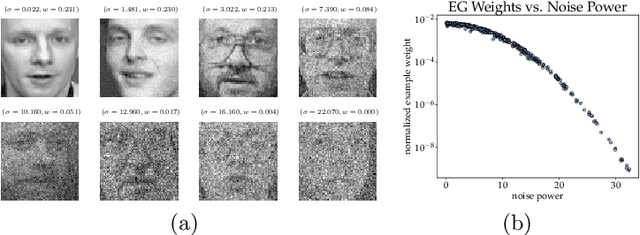

Many learning tasks in machine learning can be viewed as taking a gradient step towards minimizing the average loss of a batch of examples in each training iteration. When noise is prevalent in the data, this uniform treatment of examples can lead to overfitting to noisy examples with larger loss values and result in poor generalization. Inspired by the expert setting in on-line learning, we present a flexible approach to learning from noisy examples. Specifically, we treat each training example as an expert and maintain a distribution over all examples. We alternate between updating the parameters of the model using gradient descent and updating the example weights using the exponentiated gradient update. Unlike other related methods, our approach handles a general class of loss functions and can be applied to a wide range of noise types and applications. We show the efficacy of our approach for multiple learning settings, namely noisy principal component analysis and a variety of noisy classification problems.
Learning to Resize Images for Computer Vision Tasks
Mar 17, 2021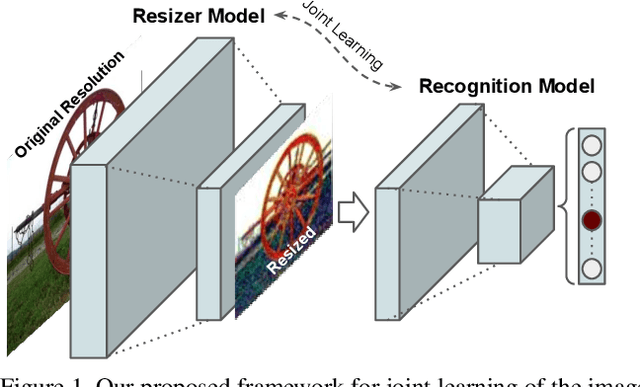


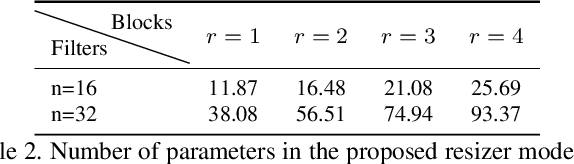
For all the ways convolutional neural nets have revolutionized computer vision in recent years, one important aspect has received surprisingly little attention: the effect of image size on the accuracy of tasks being trained for. Typically, to be efficient, the input images are resized to a relatively small spatial resolution (e.g. 224x224), and both training and inference are carried out at this resolution. The actual mechanism for this re-scaling has been an afterthought: Namely, off-the-shelf image resizers such as bilinear and bicubic are commonly used in most machine learning software frameworks. But do these resizers limit the on task performance of the trained networks? The answer is yes. Indeed, we show that the typical linear resizer can be replaced with learned resizers that can substantially improve performance. Importantly, while the classical resizers typically result in better perceptual quality of the downscaled images, our proposed learned resizers do not necessarily give better visual quality, but instead improve task performance. Our learned image resizer is jointly trained with a baseline vision model. This learned CNN-based resizer creates machine friendly visual manipulations that lead to a consistent improvement of the end task metric over the baseline model. Specifically, here we focus on the classification task with the ImageNet dataset, and experiment with four different models to learn resizers adapted to each model. Moreover, we show that the proposed resizer can also be useful for fine-tuning the classification baselines for other vision tasks. To this end, we experiment with three different baselines to develop image quality assessment (IQA) models on the AVA dataset.
Deep Perceptual Image Quality Assessment for Compression
Mar 01, 2021

Lossy Image compression is necessary for efficient storage and transfer of data. Typically the trade-off between bit-rate and quality determines the optimal compression level. This makes the image quality metric an integral part of any imaging system. While the existing full-reference metrics such as PSNR and SSIM may be less sensitive to perceptual quality, the recently introduced learning methods may fail to generalize to unseen data. In this paper we propose the largest image compression quality dataset to date with human perceptual preferences, enabling the use of deep learning, and we develop a full reference perceptual quality assessment metric for lossy image compression that outperforms the existing state-of-the-art methods. We show that the proposed model can effectively learn from thousands of examples available in the new dataset, and consequently it generalizes better to other unseen datasets of human perceptual preference.
Projected Distribution Loss for Image Enhancement
Dec 16, 2020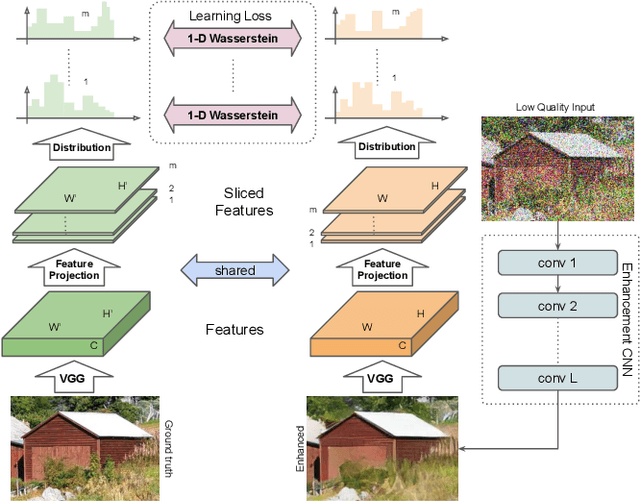
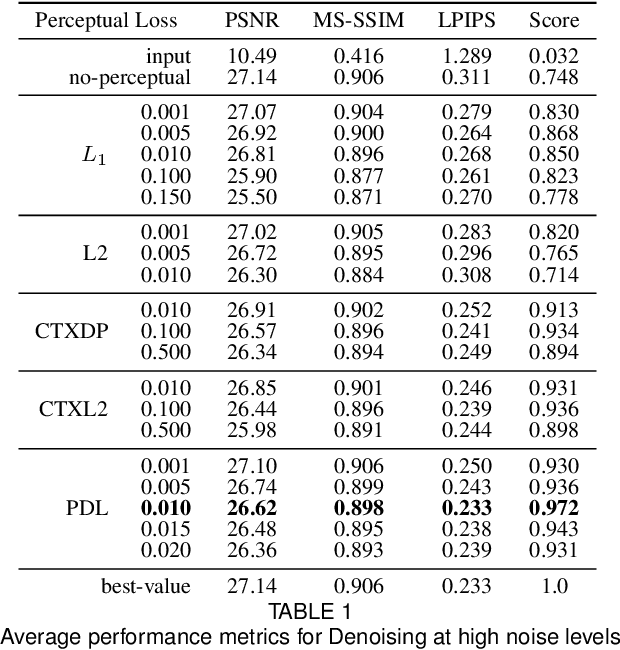
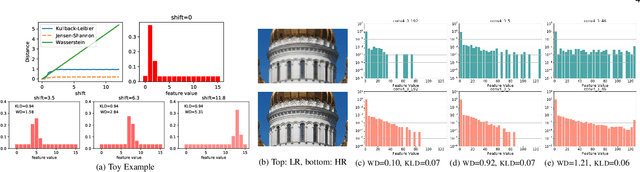
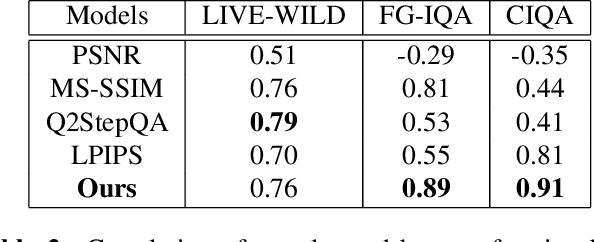
Features obtained from object recognition CNNs have been widely used for measuring perceptual similarities between images. Such differentiable metrics can be used as perceptual learning losses to train image enhancement models. However, the choice of the distance function between input and target features may have a consequential impact on the performance of the trained model. While using the norm of the difference between extracted features leads to limited hallucination of details, measuring the distance between distributions of features may generate more textures; yet also more unrealistic details and artifacts. In this paper, we demonstrate that aggregating 1D-Wasserstein distances between CNN activations is more reliable than the existing approaches, and it can significantly improve the perceptual performance of enhancement models. More explicitly, we show that in imaging applications such as denoising, super-resolution, demosaicing, deblurring and JPEG artifact removal, the proposed learning loss outperforms the current state-of-the-art on reference-based perceptual losses. This means that the proposed learning loss can be plugged into different imaging frameworks and produce perceptually realistic results.
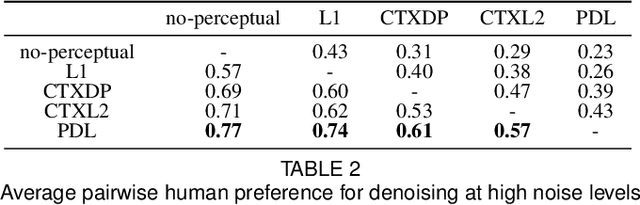
Rank-smoothed Pairwise Learning In Perceptual Quality Assessment
Nov 21, 2020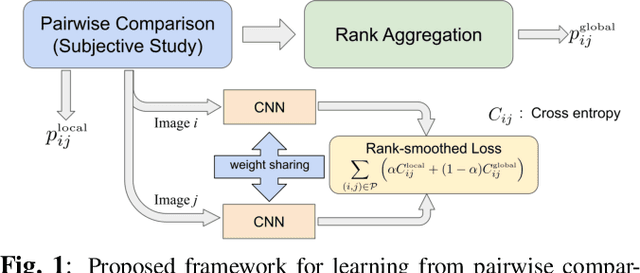
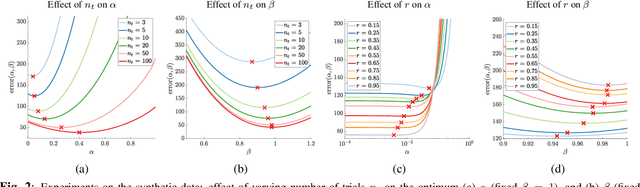
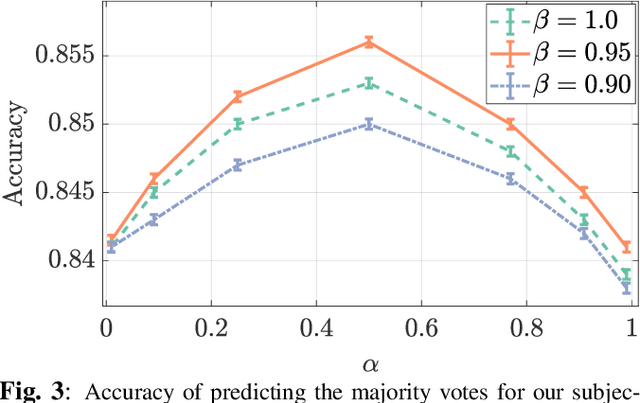

Conducting pairwise comparisons is a widely used approach in curating human perceptual preference data. Typically raters are instructed to make their choices according to a specific set of rules that address certain dimensions of image quality and aesthetics. The outcome of this process is a dataset of sampled image pairs with their associated empirical preference probabilities. Training a model on these pairwise preferences is a common deep learning approach. However, optimizing by gradient descent through mini-batch learning means that the "global" ranking of the images is not explicitly taken into account. In other words, each step of the gradient descent relies only on a limited number of pairwise comparisons. In this work, we demonstrate that regularizing the pairwise empirical probabilities with aggregated rankwise probabilities leads to a more reliable training loss. We show that training a deep image quality assessment model with our rank-smoothed loss consistently improves the accuracy of predicting human preferences.
The Rate-Distortion-Accuracy Tradeoff: JPEG Case Study
Aug 03, 2020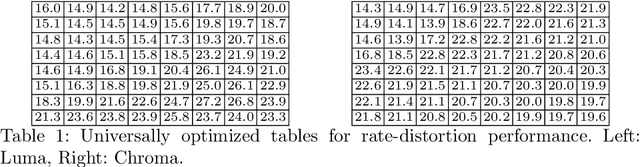
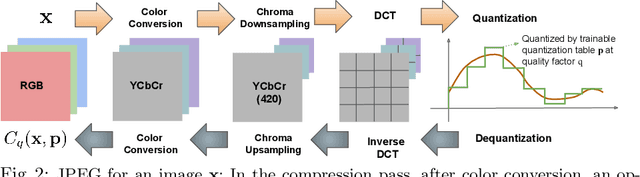
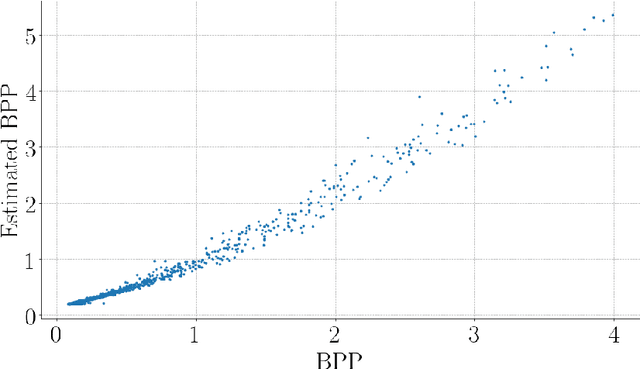
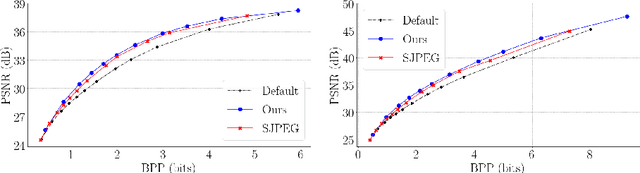
Handling digital images is almost always accompanied by a lossy compression in order to facilitate efficient transmission and storage. This introduces an unavoidable tension between the allocated bit-budget (rate) and the faithfulness of the resulting image to the original one (distortion). An additional complicating consideration is the effect of the compression on recognition performance by given classifiers (accuracy). This work aims to explore this rate-distortion-accuracy tradeoff. As a case study, we focus on the design of the quantization tables in the JPEG compression standard. We offer a novel optimal tuning of these tables via continuous optimization, leveraging a differential implementation of both the JPEG encoder-decoder and an entropy estimator. This enables us to offer a unified framework that considers the interplay between rate, distortion and classification accuracy. In all these fronts, we report a substantial boost in performance by a simple and easily implemented modification of these tables.
Super-Resolving Commercial Satellite Imagery Using Realistic Training Data
Feb 26, 2020
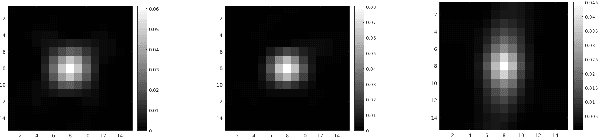

In machine learning based single image super-resolution, the degradation model is embedded in training data generation. However, most existing satellite image super-resolution methods use a simple down-sampling model with a fixed kernel to create training images. These methods work fine on synthetic data, but do not perform well on real satellite images. We propose a realistic training data generation model for commercial satellite imagery products, which includes not only the imaging process on satellites but also the post-process on the ground. We also propose a convolutional neural network optimized for satellite images. Experiments show that the proposed training data generation model is able to improve super-resolution performance on real satellite images.