 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time adversarial detection and robustness for localizing humans using ultra wide band channel impulse responses
Nov 10, 2022



Keyless entry systems in cars are adopting neural networks for localizing its operators. Using test-time adversarial defences equip such systems with the ability to defend against adversarial attacks without prior training on adversarial samples. We propose a test-time adversarial example detector which detects the input adversarial example through quantifying the localized intermediate responses of a pre-trained neural network and confidence scores of an auxiliary softmax layer. Furthermore, in order to make the network robust, we extenuate the non-relevant features by non-iterative input sample clipping. Using our approach, mean performance over 15 levels of adversarial perturbations is increased by 55.33% for the fast gradient sign method (FGSM) and 6.3% for both the basic iterative method (BIM) and the projected gradient method (PGD).
SAILOR: Scaling Anchors via Insights into Latent Object Representation
Oct 17, 2022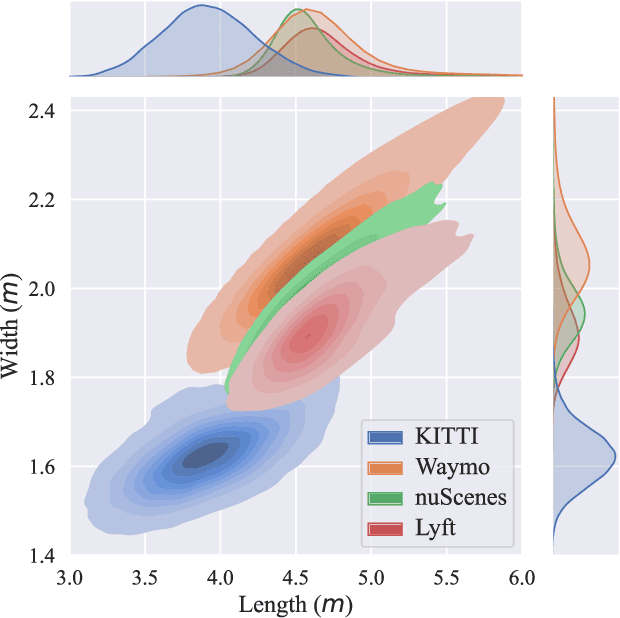
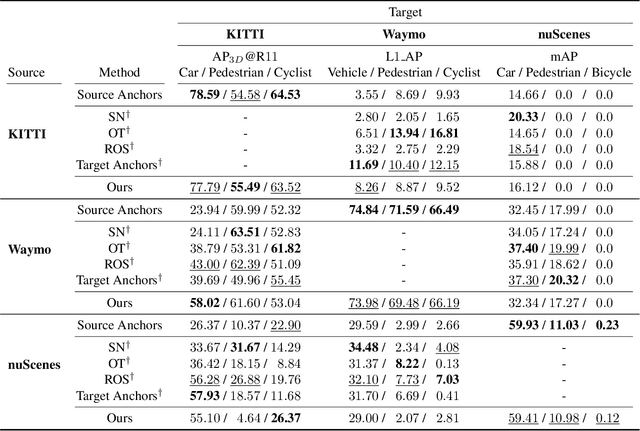
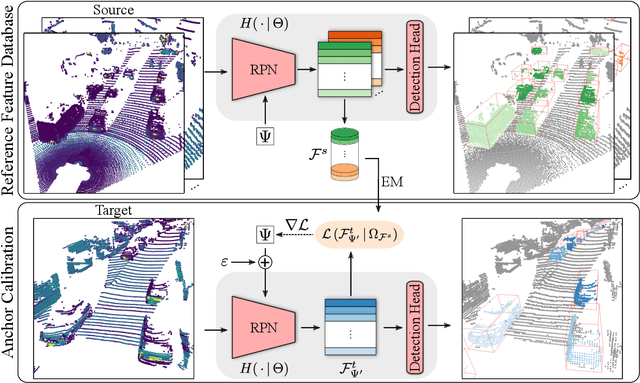
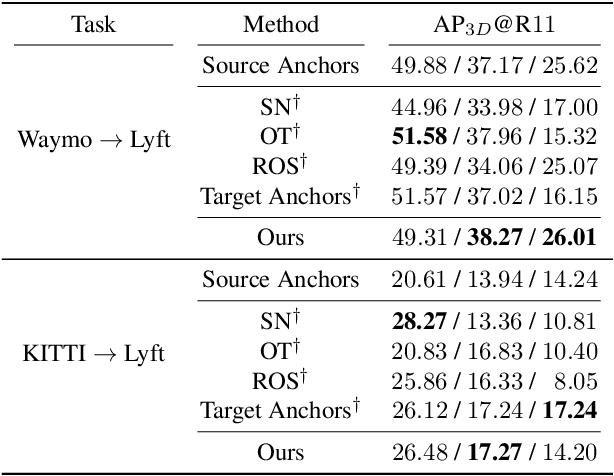
LiDAR 3D object detection models are inevitably biased towards their training dataset. The detector clearly exhibits this bias when employed on a target dataset, particularly towards object sizes. However, object sizes vary heavily between domains due to, for instance, different labeling policies or geographical locations. State-of-the-art unsupervised domain adaptation approaches outsource methods to overcome the object size bias. Mainstream size adaptation approaches exploit target domain statistics, contradicting the original unsupervised assumption. Our novel unsupervised anchor calibration method addresses this limitation. Given a model trained on the source data, we estimate the optimal target anchors in a completely unsupervised manner. The main idea stems from an intuitive observation: by varying the anchor sizes for the target domain, we inevitably introduce noise or even remove valuable object cues. The latent object representation, perturbed by the anchor size, is closest to the learned source features only under the optimal target anchors. We leverage this observation for anchor size optimization. Our experimental results show that, without any retraining, we achieve competitive results even compared to state-of-the-art weakly-supervised size adaptation approaches. In addition, our anchor calibration can be combined with such existing methods, making them completely unsupervised.
An Efficient Domain-Incremental Learning Approach to Drive in All Weather Conditions
Apr 21, 2022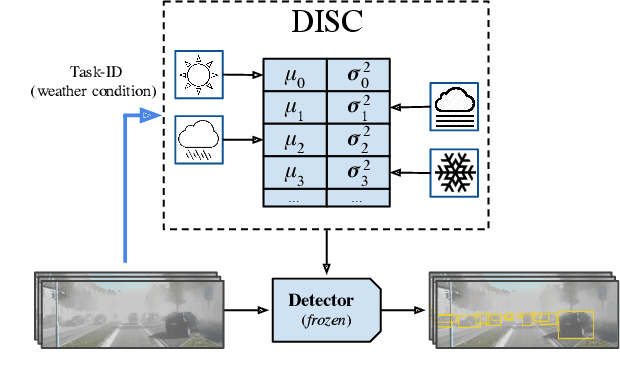
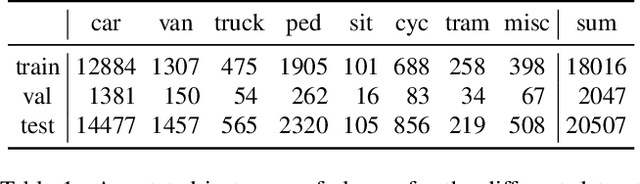
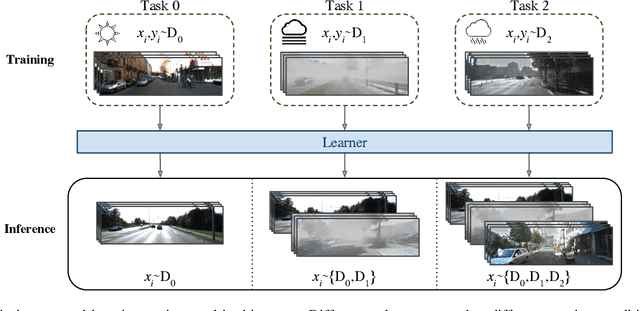
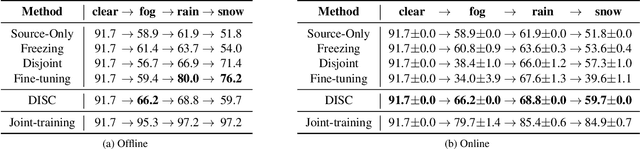
Although deep neural networks enable impressive visual perception performance for autonomous driving, their robustness to varying weather conditions still requires attention. When adapting these models for changed environments, such as different weather conditions, they are prone to forgetting previously learned information. This catastrophic forgetting is typically addressed via incremental learning approaches which usually re-train the model by either keeping a memory bank of training samples or keeping a copy of the entire model or model parameters for each scenario. While these approaches show impressive results, they can be prone to scalability issues and their applicability for autonomous driving in all weather conditions has not been shown. In this paper we propose DISC -- Domain Incremental through Statistical Correction -- a simple online zero-forgetting approach which can incrementally learn new tasks (i.e weather conditions) without requiring re-training or expensive memory banks. The only information we store for each task are the statistical parameters as we categorize each domain by the change in first and second order statistics. Thus, as each task arrives, we simply 'plug and play' the statistical vectors for the corresponding task into the model and it immediately starts to perform well on that task. We show the efficacy of our approach by testing it for object detection in a challenging domain-incremental autonomous driving scenario where we encounter different adverse weather conditions, such as heavy rain, fog, and snow.
OccAM's Laser: Occlusion-based Attribution Maps for 3D Object Detectors on LiDAR Data
Apr 13, 2022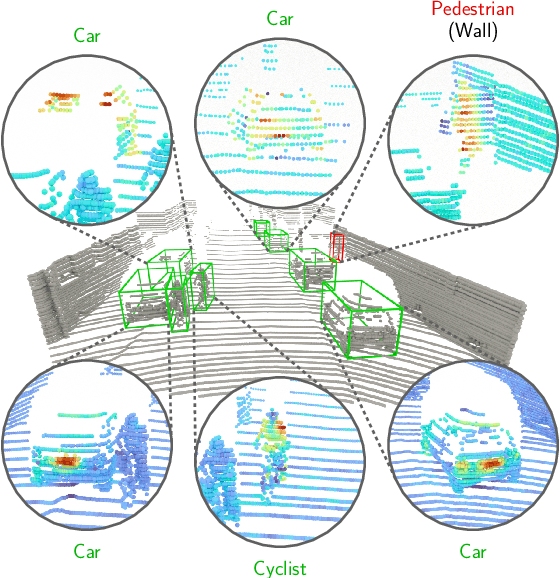
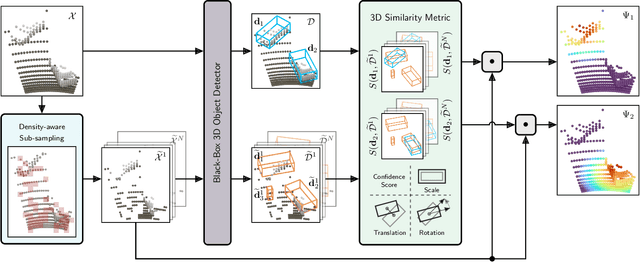
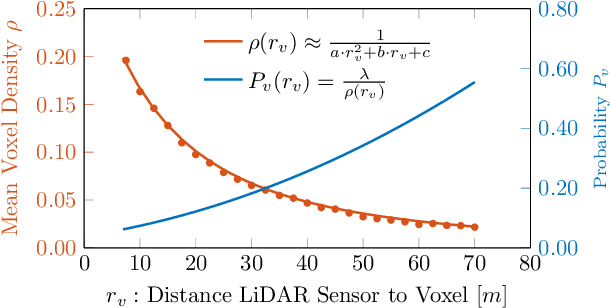
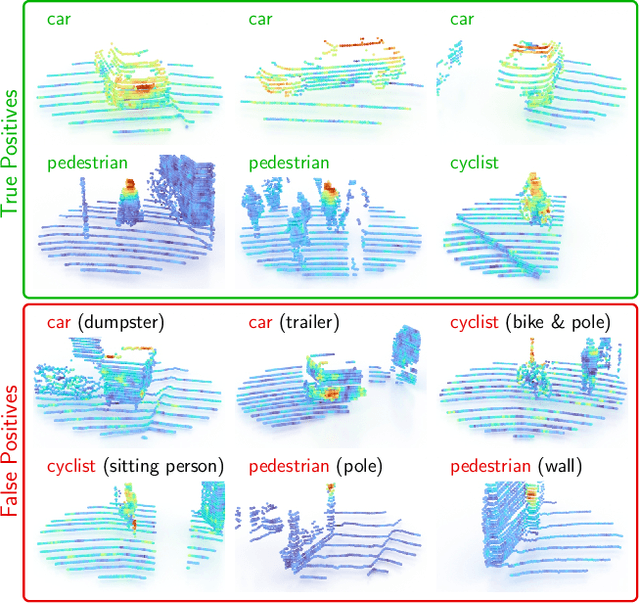
While 3D object detection in LiDAR point clouds is well-established in academia and industry, the explainability of these models is a largely unexplored field. In this paper, we propose a method to generate attribution maps for the detected objects in order to better understand the behavior of such models. These maps indicate the importance of each 3D point in predicting the specific objects. Our method works with black-box models: We do not require any prior knowledge of the architecture nor access to the model's internals, like parameters, activations or gradients. Our efficient perturbation-based approach empirically estimates the importance of each point by testing the model with randomly generated subsets of the input point cloud. Our sub-sampling strategy takes into account the special characteristics of LiDAR data, such as the depth-dependent point density. We show a detailed evaluation of the attribution maps and demonstrate that they are interpretable and highly informative. Furthermore, we compare the attribution maps of recent 3D object detection architectures to provide insights into their decision-making processes.
CycDA: Unsupervised Cycle Domain Adaptation from Image to Video
Mar 30, 2022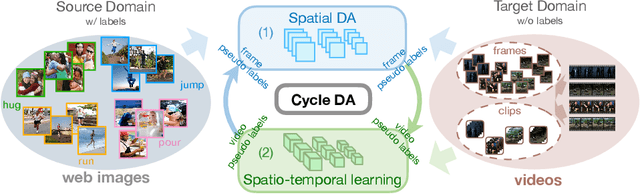
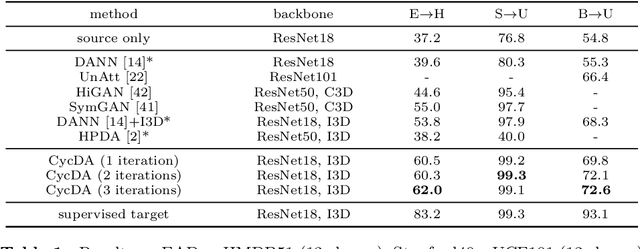
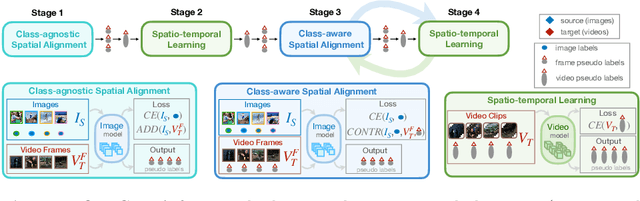
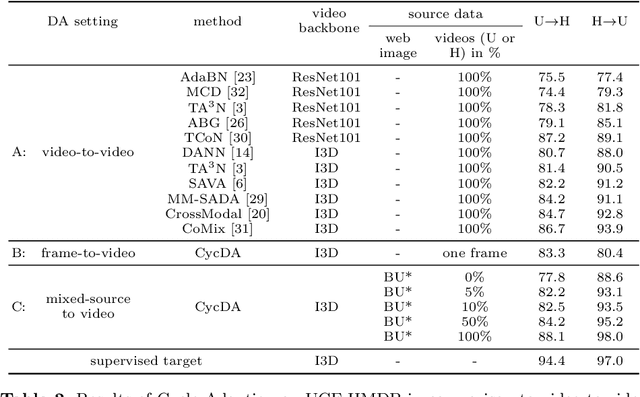
Although action recognition has achieved impressive results over recent years, both collection and annotation of video training data are still time-consuming and cost intensive. Therefore, image-to-video adaptation has been proposed to exploit labeling-free web image source for adapting on unlabeled target videos. This poses two major challenges: (1) spatial domain shift between web images and video frames; (2) modality gap between image and video data. To address these challenges, we propose Cycle Domain Adaptation (CycDA), a cycle-based approach for unsupervised image-to-video domain adaptation by leveraging the joint spatial information in images and videos on the one hand and, on the other hand, training an independent spatio-temporal model to bridge the modality gap. We alternate between the spatial and spatio-temporal learning with knowledge transfer between the two in each cycle. We evaluate our approach on benchmark datasets for image-to-video as well as for mixed-source domain adaptation achieving state-of-the-art results and demonstrating the benefits of our cyclic adaptation.
3D Human Pose Estimation Using Möbius Graph Convolutional Networks
Mar 20, 2022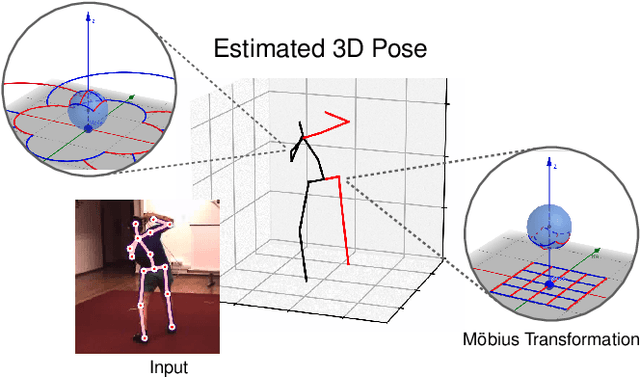
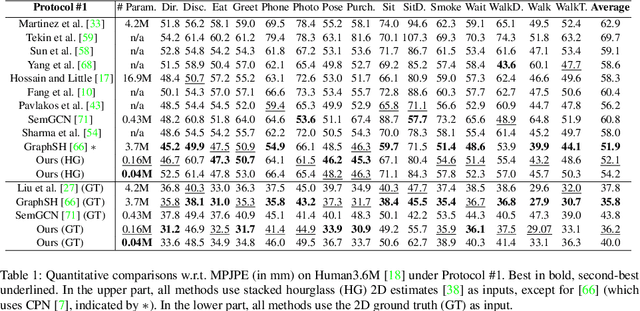
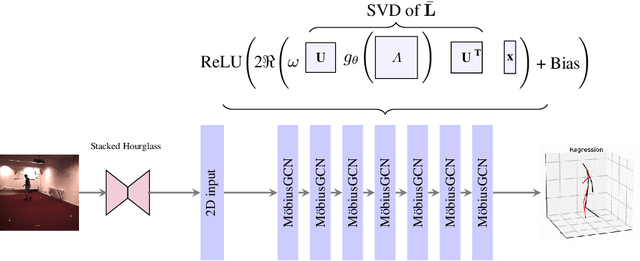
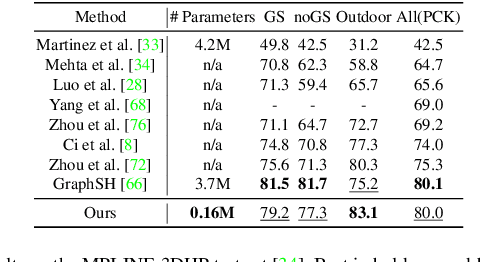
3D human pose estimation is fundamental to understanding human behavior. Recently, promising results have been achieved by graph convolutional networks (GCNs), which achieve state-of-the-art performance and provide rather light-weight architectures. However, a major limitation of GCNs is their inability to encode all the transformations between joints explicitly. To address this issue, we propose a novel spectral GCN using the M\"obius transformation (M\"obiusGCN). In particular, this allows us to directly and explicitly encode the transformation between joints, resulting in a significantly more compact representation. Compared to even the lightest architectures so far, our novel approach requires 90-98% fewer parameters, i.e. our lightest M\"obiusGCN uses only 0.042M trainable parameters. Besides the drastic parameter reduction, explicitly encoding the transformation of joints also enables us to achieve state-of-the-art results. We evaluate our approach on the two challenging pose estimation benchmarks, Human3.6M and MPI-INF-3DHP, demonstrating both state-of-the-art results and the generalization capabilities of M\"obiusGCN.
The Norm Must Go On: Dynamic Unsupervised Domain Adaptation by Normalization
Dec 01, 2021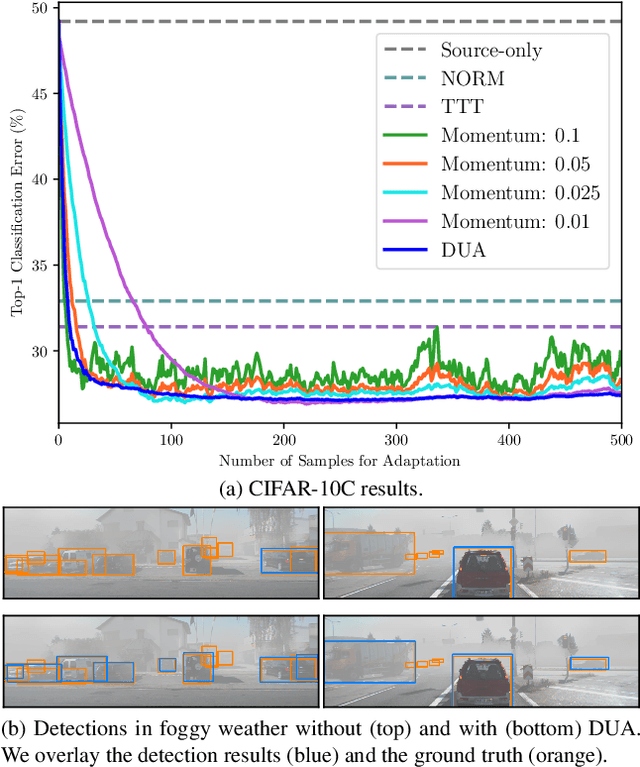
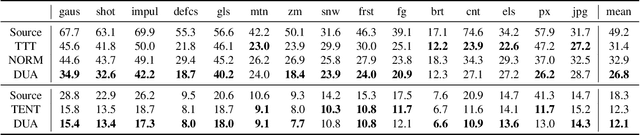
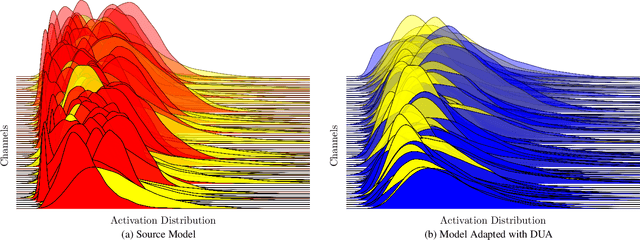
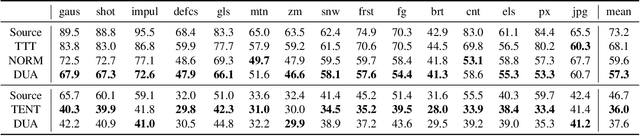
Domain adaptation is crucial to adapt a learned model to new scenarios, such as domain shifts or changing data distributions. Current approaches usually require a large amount of labeled or unlabeled data from the shifted domain. This can be a hurdle in fields which require continuous dynamic adaptation or suffer from scarcity of data, e.g. autonomous driving in challenging weather conditions. To address this problem of continuous adaptation to distribution shifts, we propose Dynamic Unsupervised Adaptation (DUA). We modify the feature representations of the model by continuously adapting the statistics of the batch normalization layers. We show that by accessing only a tiny fraction of unlabeled data from the shifted domain and adapting sequentially, a strong performance gain can be achieved. With even less than 1% of unlabeled data from the target domain, DUA already achieves competitive results to strong baselines. In addition, the computational overhead is minimal in contrast to previous approaches. Our approach is simple, yet effective and can be applied to any architecture which uses batch normalization as one of its components. We show the utility of DUA by evaluating it on a variety of domain adaptation datasets and tasks including object recognition, digit recognition and object detection.
Efficient Multi-Organ Segmentation Using SpatialConfiguration-Net with Low GPU Memory Requirements
Nov 26, 2021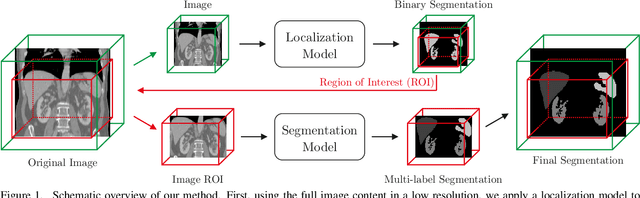

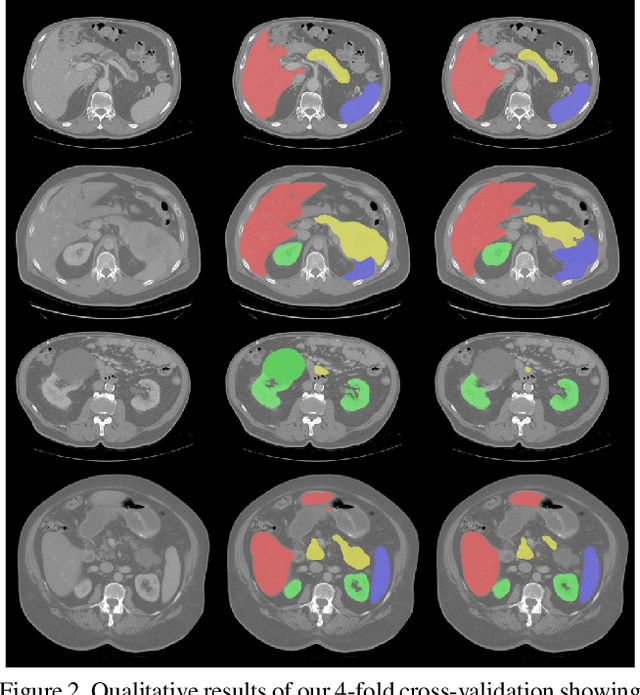
Even though many semantic segmentation methods exist that are able to perform well on many medical datasets, often, they are not designed for direct use in clinical practice. The two main concerns are generalization to unseen data with a different visual appearance, e.g., images acquired using a different scanner, and efficiency in terms of computation time and required Graphics Processing Unit (GPU) memory. In this work, we employ a multi-organ segmentation model based on the SpatialConfiguration-Net (SCN), which integrates prior knowledge of the spatial configuration among the labelled organs to resolve spurious responses in the network outputs. Furthermore, we modified the architecture of the segmentation model to reduce its memory footprint as much as possible without drastically impacting the quality of the predictions. Lastly, we implemented a minimal inference script for which we optimized both, execution time and required GPU memory.
FAST3D: Flow-Aware Self-Training for 3D Object Detectors
Oct 18, 2021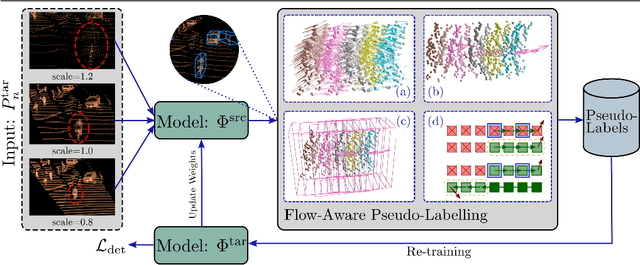
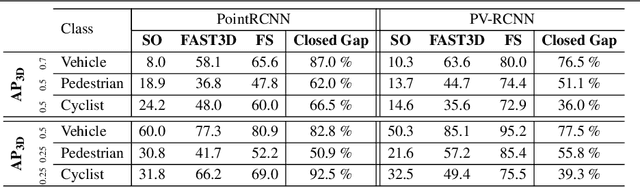
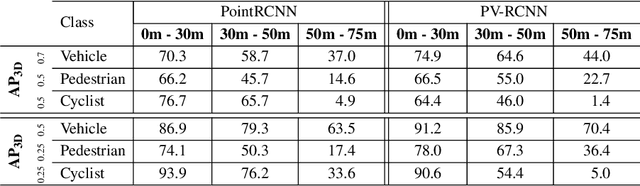
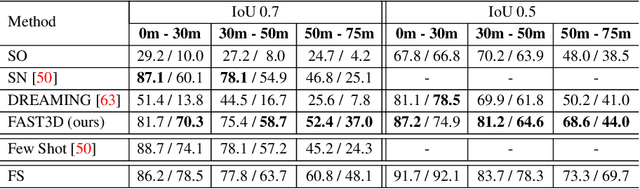
In the field of autonomous driving, self-training is widely applied to mitigate distribution shifts in LiDAR-based 3D object detectors. This eliminates the need for expensive, high-quality labels whenever the environment changes (e.g., geographic location, sensor setup, weather condition). State-of-the-art self-training approaches, however, mostly ignore the temporal nature of autonomous driving data. To address this issue, we propose a flow-aware self-training method that enables unsupervised domain adaptation for 3D object detectors on continuous LiDAR point clouds. In order to get reliable pseudo-labels, we leverage scene flow to propagate detections through time. In particular, we introduce a flow-based multi-target tracker, that exploits flow consistency to filter and refine resulting tracks. The emerged precise pseudo-labels then serve as a basis for model re-training. Starting with a pre-trained KITTI model, we conduct experiments on the challenging Waymo Open Dataset to demonstrate the effectiveness of our approach. Without any prior target domain knowledge, our results show a significant improvement over the state-of-the-art.
Robustness of Object Detectors in Degrading Weather Conditions
Jun 16, 2021

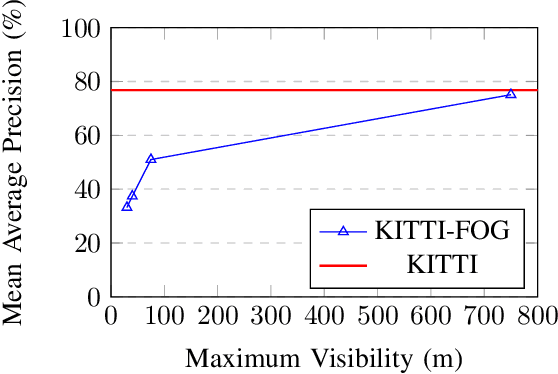
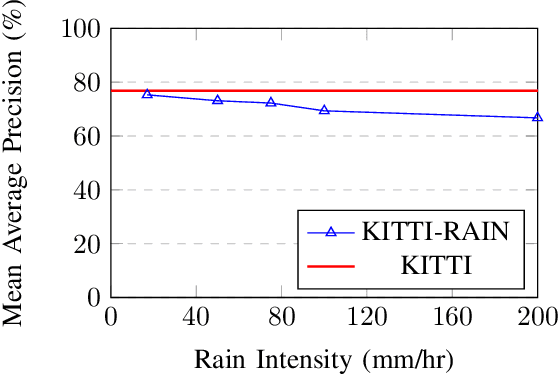
State-of-the-art object detection systems for autonomous driving achieve promising results in clear weather conditions. However, such autonomous safety critical systems also need to work in degrading weather conditions, such as rain, fog and snow. Unfortunately, most approaches evaluate only on the KITTI dataset, which consists only of clear weather scenes. In this paper we address this issue and perform one of the most detailed evaluation on single and dual modality architectures on data captured in real weather conditions. We analyse the performance degradation of these architectures in degrading weather conditions. We demonstrate that an object detection architecture performing good in clear weather might not be able to handle degrading weather conditions. We also perform ablation studies on the dual modality architectures and show their limitations.