 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Rejection Sampling: Trajectory Fusion for Scaling Mathematical Reasoning
Feb 04, 2026Large language models (LLMs) have made impressive strides in mathematical reasoning, often fine-tuned using rejection sampling that retains only correct reasoning trajectories. While effective, this paradigm treats supervision as a binary filter that systematically excludes teacher-generated errors, leaving a gap in how reasoning failures are modeled during training. In this paper, we propose TrajFusion, a fine-tuning strategy that reframes rejection sampling as a structured supervision construction process. Specifically, TrajFusion forms fused trajectories that explicitly model trial-and-error reasoning by interleaving selected incorrect trajectories with reflection prompts and correct trajectories. The length of each fused sample is adaptively controlled based on the frequency and diversity of teacher errors, providing richer supervision for challenging problems while safely reducing to vanilla rejection sampling fine-tuning (RFT) when error signals are uninformative. TrajFusion requires no changes to the architecture or training objective. Extensive experiments across multiple math benchmarks demonstrate that TrajFusion consistently outperforms RFT, particularly on challenging and long-form reasoning problems.
ConPress: Learning Efficient Reasoning from Multi-Question Contextual Pressure
Feb 01, 2026Large reasoning models (LRMs) typically solve reasoning-intensive tasks by generating long chain-of-thought (CoT) traces, leading to substantial inference overhead. We identify a reproducible inference-time phenomenon, termed Self-Compression: when multiple independent and answerable questions are presented within a single prompt, the model spontaneously produces shorter reasoning traces for each question. This phenomenon arises from multi-question contextual pressure during generation and consistently manifests across models and benchmarks. Building on this observation, we propose ConPress (Learning from Contextual Pressure), a lightweight self-supervised fine-tuning approach. ConPress constructs multi-question prompts to induce self-compression, samples the resulting model outputs, and parses and filters per-question traces to obtain concise yet correct reasoning trajectories. These trajectories are directly used for supervised fine-tuning, internalizing compressed reasoning behavior in single-question settings without external teachers, manual pruning, or reinforcement learning. With only 8k fine-tuning examples, ConPress reduces reasoning token usage by 59% on MATH500 and 33% on AIME25, while maintaining competitive accuracy.
Multi-modal Deep Analysis for Multimedia
Oct 11, 2019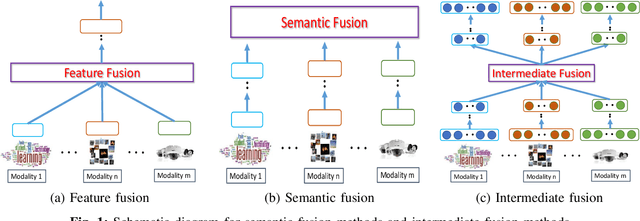
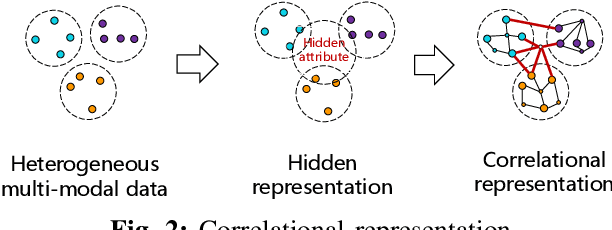

With the rapid development of Internet and multimedia services in the past decade, a huge amount of user-generated and service provider-generated multimedia data become available. These data are heterogeneous and multi-modal in nature, imposing great challenges for processing and analyzing them. Multi-modal data consist of a mixture of various types of data from different modalities such as texts, images, videos, audios etc. In this article, we present a deep and comprehensive overview for multi-modal analysis in multimedia. We introduce two scientific research problems, data-driven correlational representation and knowledge-guided fusion for multimedia analysis. To address the two scientific problems, we investigate them from the following aspects: 1) multi-modal correlational representation: multi-modal fusion of data across different modalities, and 2) multi-modal data and knowledge fusion: multi-modal fusion of data with domain knowledge. More specifically, on data-driven correlational representation, we highlight three important categories of methods, such as multi-modal deep representation, multi-modal transfer learning, and multi-modal hashing. On knowledge-guided fusion, we discuss the approaches for fusing knowledge with data and four exemplar applications that require various kinds of domain knowledge, including multi-modal visual question answering, multi-modal video summarization, multi-modal visual pattern mining and multi-modal recommendation. Finally, we bring forward our insights and future research directions.
Double-Head RCNN: Rethinking Classification and Localization for Object Detection
May 31, 2019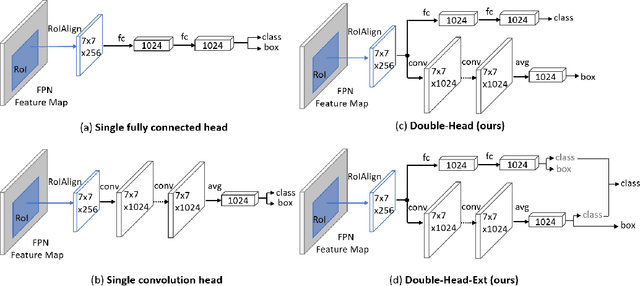

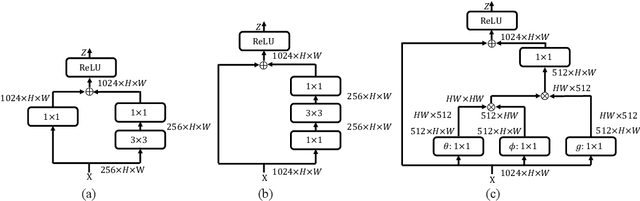
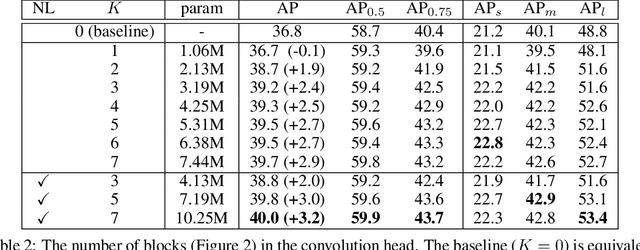
Modern R-CNN based detectors apply a head to extract Region of Interest (RoI) features for both classification and localization tasks. In contrast, we found that these two tasks have opposite preferences towards two widely used head structures (i.e. fully connected head and convolution head). Specifically, the fully connected head is more suitable for the classification task, while the convolution head is more suitable for the localization task. Therefore, we propose a Double-Head method, which has a fully connected head focusing on classification and a convolution head to pay more attention to bounding box regression. In addition, we have two findings for the unfocused tasks (i.e. classification in the convolution head, and bounding box regression in the fully connected head): (a) adding classification to the convolution head is complementary to the classification in the fully connected head, and (b) bounding box regression provides auxiliary supervision for the fully connected head. Without bells and whistles, our method gains +3.5 and +2.8 AP on MS COCO dataset from Feature Pyramid Network (FPN) baselines with ResNet-50 and ResNet-101 backbones, respectively.
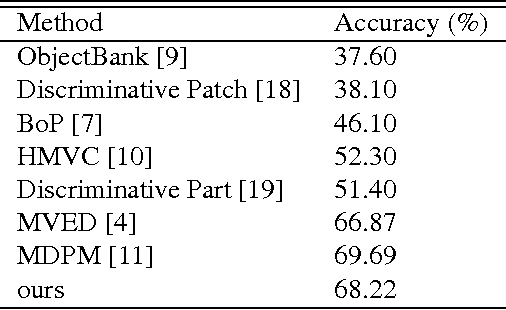
PatternNet: Visual Pattern Mining with Deep Neural Network
Jun 13, 2018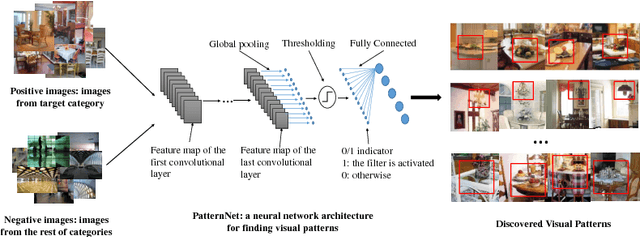

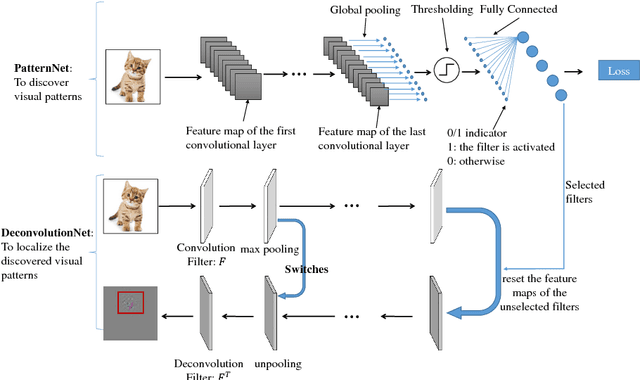
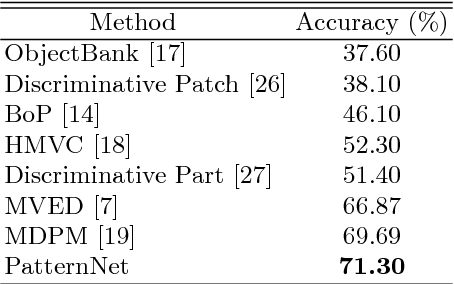
Visual patterns represent the discernible regularity in the visual world. They capture the essential nature of visual objects or scenes. Understanding and modeling visual patterns is a fundamental problem in visual recognition that has wide ranging applications. In this paper, we study the problem of visual pattern mining and propose a novel deep neural network architecture called PatternNet for discovering these patterns that are both discriminative and representative. The proposed PatternNet leverages the filters in the last convolution layer of a convolutional neural network to find locally consistent visual patches, and by combining these filters we can effectively discover unique visual patterns. In addition, PatternNet can discover visual patterns efficiently without performing expensive image patch sampling, and this advantage provides an order of magnitude speedup compared to most other approaches. We evaluate the proposed PatternNet subjectively by showing randomly selected visual patterns which are discovered by our method and quantitatively by performing image classification with the identified visual patterns and comparing our performance with the current state-of-the-art. We also directly evaluate the quality of the discovered visual patterns by leveraging the identified patterns as proposed objects in an image and compare with other relevant methods. Our proposed network and procedure, PatterNet, is able to outperform competing methods for the tasks described.
Event Specific Multimodal Pattern Mining with Image-Caption Pairs
Jan 05, 2016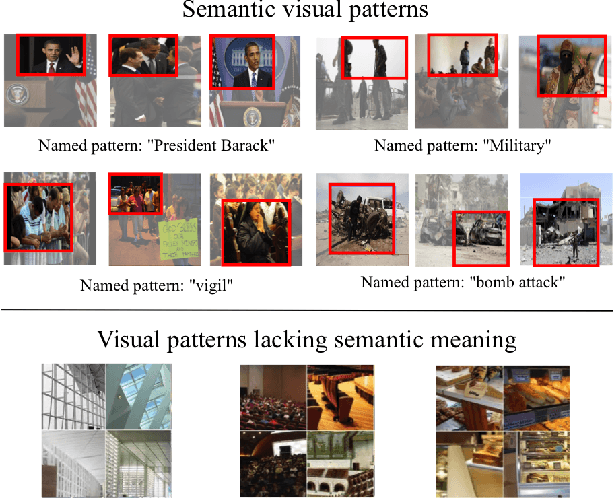

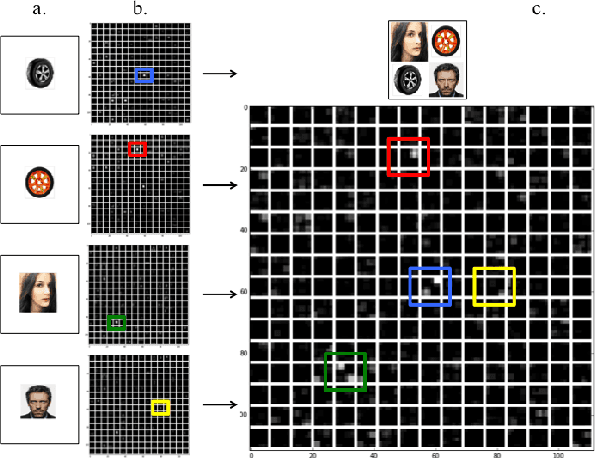
In this paper we describe a novel framework and algorithms for discovering image patch patterns from a large corpus of weakly supervised image-caption pairs generated from news events. Current pattern mining techniques attempt to find patterns that are representative and discriminative, we stipulate that our discovered patterns must also be recognizable by humans and preferably with meaningful names. We propose a new multimodal pattern mining approach that leverages the descriptive captions often accompanying news images to learn semantically meaningful image patch patterns. The mutltimodal patterns are then named using words mined from the associated image captions for each pattern. A novel evaluation framework is provided that demonstrates our patterns are 26.2% more semantically meaningful than those discovered by the state of the art vision only pipeline, and that we can provide tags for the discovered images patches with 54.5% accuracy with no direct supervision. Our methods also discover named patterns beyond those covered by the existing image datasets like ImageNet. To the best of our knowledge this is the first algorithm developed to automatically mine image patch patterns that have strong semantic meaning specific to high-level news events, and then evaluate these patterns based on that criteria.