 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIND:Explainable Framework for Meta-learning
May 20, 2022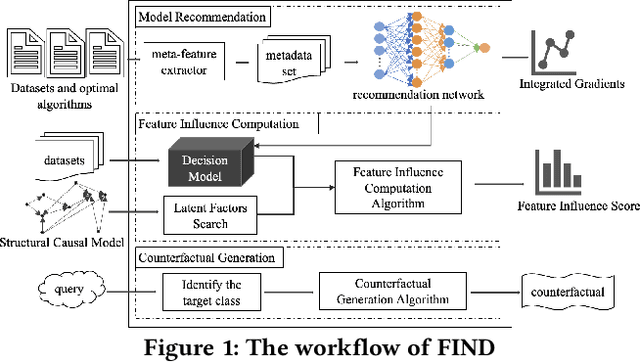

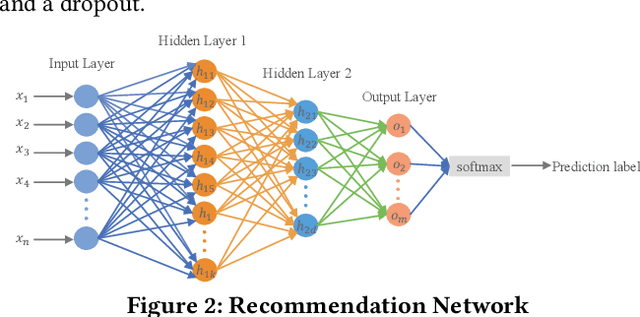
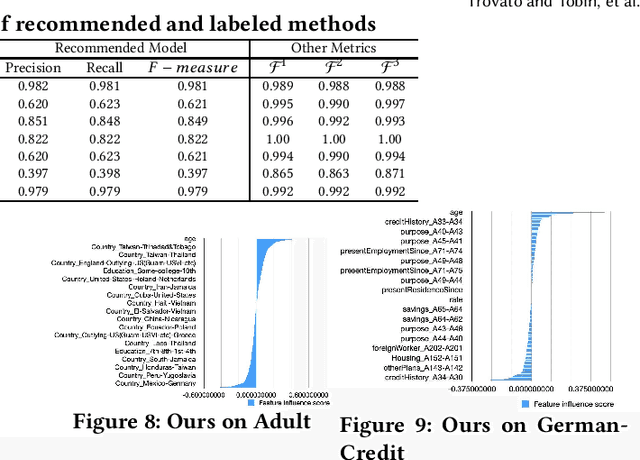
Meta-learning is used to efficiently enable the automatic selection of machine learning models by combining data and prior knowledge. Since the traditional meta-learning technique lacks explainability, as well as shortcomings in terms of transparency and fairness, achieving explainability for meta-learning is crucial. This paper proposes FIND, an interpretable meta-learning framework that not only can explain the recommendation results of meta-learning algorithm selection, but also provide a more complete and accurate explanation of the recommendation algorithm's performance on specific datasets combined with business scenarios. The validity and correctness of this framework have been demonstrated by extensive experiments.
AutoTS: Automatic Time Series Forecasting Model Design Based on Two-Stage Pruning
Mar 26, 2022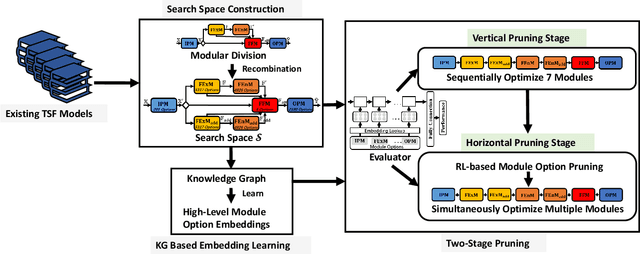
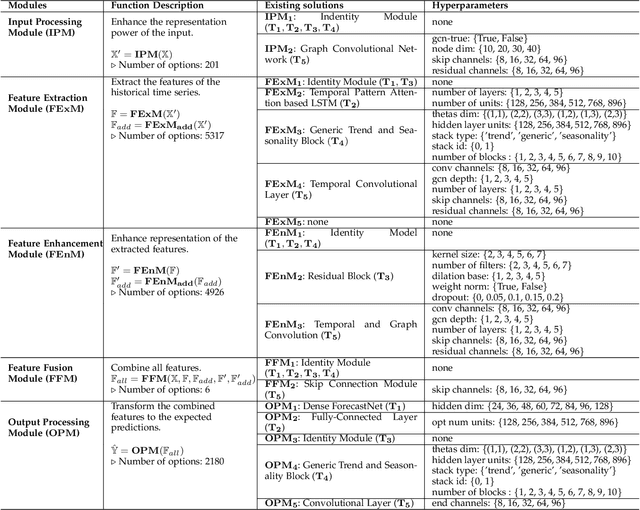
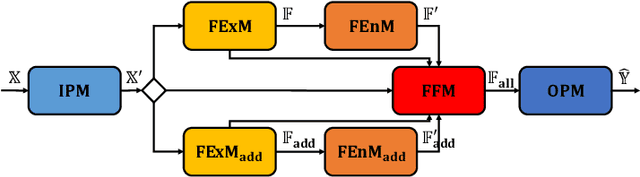

Automatic Time Series Forecasting (TSF) model design which aims to help users to efficiently design suitable forecasting model for the given time series data scenarios, is a novel research topic to be urgently solved. In this paper, we propose AutoTS algorithm trying to utilize the existing design skills and design efficient search methods to effectively solve this problem. In AutoTS, we extract effective design experience from the existing TSF works. We allow the effective combination of design experience from different sources, so as to create an effective search space containing a variety of TSF models to support different TSF tasks. Considering the huge search space, in AutoTS, we propose a two-stage pruning strategy to reduce the search difficulty and improve the search efficiency. In addition, in AutoTS, we introduce the knowledge graph to reveal associations between module options. We make full use of these relational information to learn higher-level features of each module option, so as to further improve the search quality. Extensive experimental results show that AutoTS is well-suited for the TSF area. It is more efficient than the existing neural architecture search algorithms, and can quickly design powerful TSF model better than the manually designed ones.
AutoMC: Automated Model Compression based on Domain Knowledge and Progressive search strategy
Jan 24, 2022



Model compression methods can reduce model complexity on the premise of maintaining acceptable performance, and thus promote the application of deep neural networks under resource constrained environments. Despite their great success, the selection of suitable compression methods and design of details of the compression scheme are difficult, requiring lots of domain knowledge as support, which is not friendly to non-expert users. To make more users easily access to the model compression scheme that best meet their needs, in this paper, we propose AutoMC, an effective automatic tool for model compression. AutoMC builds the domain knowledge on model compression to deeply understand the characteristics and advantages of each compression method under different settings. In addition, it presents a progressive search strategy to efficiently explore pareto optimal compression scheme according to the learned prior knowledge combined with the historical evaluation information. Extensive experimental results show that AutoMC can provide satisfying compression schemes within short time, demonstrating the effectiveness of AutoMC.
TPAD: Identifying Effective Trajectory Predictions Under the Guidance of Trajectory Anomaly Detection Model
Jan 09, 2022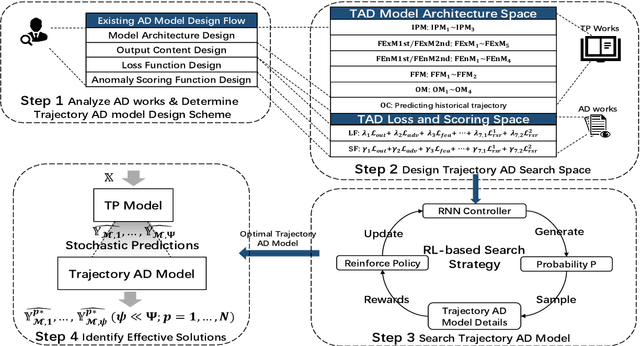
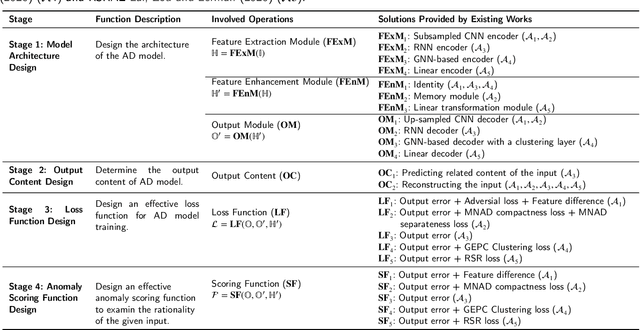

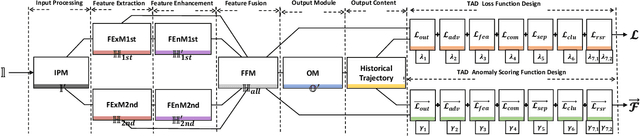
Trajectory Prediction (TP) is an important research topic in computer vision and robotics fields. Recently, many stochastic TP models have been proposed to deal with this problem and have achieved better performance than the traditional models with deterministic trajectory outputs. However, these stochastic models can generate a number of future trajectories with different qualities. They are lack of self-evaluation ability, that is, to examine the rationality of their prediction results, thus failing to guide users to identify high-quality ones from their candidate results. This hinders them from playing their best in real applications. In this paper, we make up for this defect and propose TPAD, a novel TP evaluation method based on the trajectory Anomaly Detection (AD) technique. In TPAD, we firstly combine the Automated Machine Learning (AutoML) technique and the experience in the AD and TP field to automatically design an effective trajectory AD model. Then, we utilize the learned trajectory AD model to examine the rationality of the predicted trajectories, and screen out good TP results for users. Extensive experimental results demonstrate that TPAD can effectively identify near-optimal prediction results, improving stochastic TP models' practical application effect.
Addressing Deep Learning Model Uncertainty in Long-Range Climate Forecasting with Late Fusion
Dec 10, 2021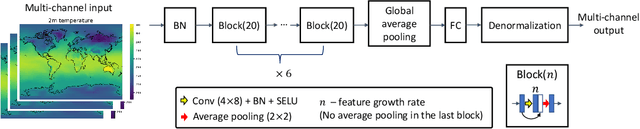
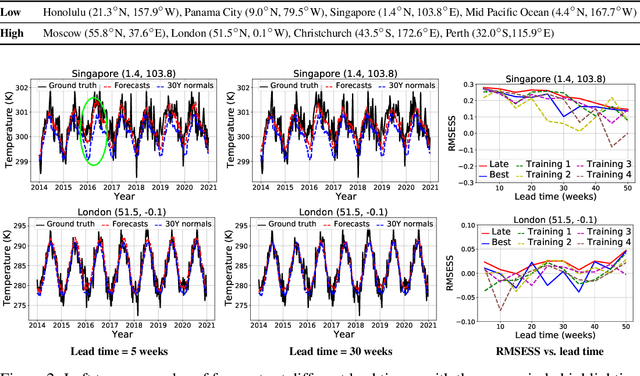
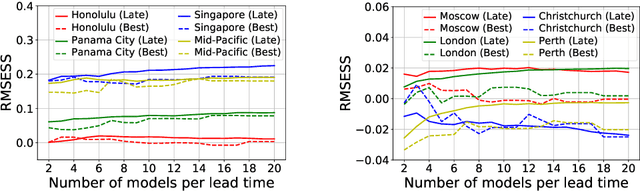
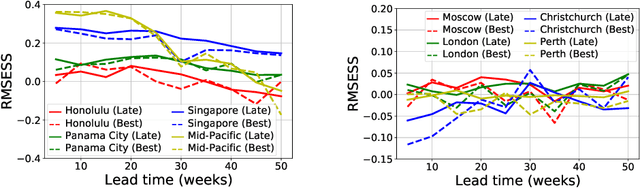
Global warming leads to the increase in frequency and intensity of climate extremes that cause tremendous loss of lives and property. Accurate long-range climate prediction allows more time for preparation and disaster risk management for such extreme events. Although machine learning approaches have shown promising results in long-range climate forecasting, the associated model uncertainties may reduce their reliability. To address this issue, we propose a late fusion approach that systematically combines the predictions from multiple models to reduce the expected errors of the fused results. We also propose a network architecture with the novel denormalization layer to gain the benefits of data normalization without actually normalizing the data. The experimental results on long-range 2m temperature forecasting show that the framework outperforms the 30-year climate normals, and the accuracy can be improved by increasing the number of models.
Search For Deep Graph Neural Networks
Sep 21, 2021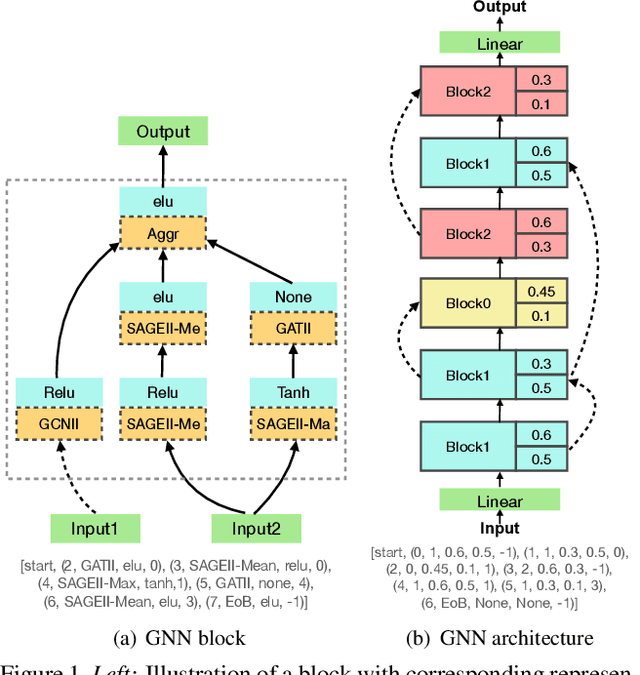

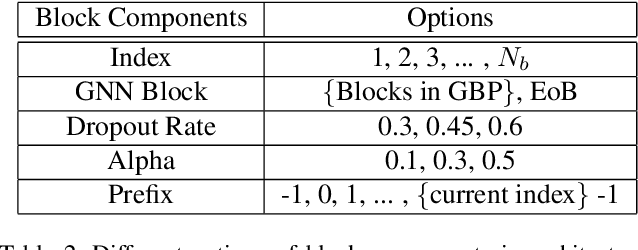
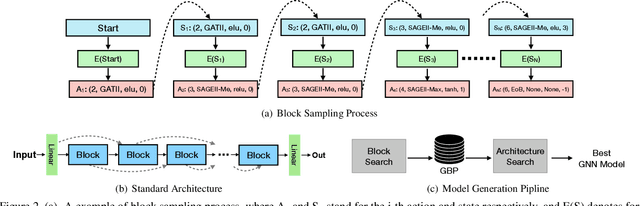
Current GNN-oriented NAS methods focus on the search for different layer aggregate components with shallow and simple architectures, which are limited by the 'over-smooth' problem. To further explore the benefits from structural diversity and depth of GNN architectures, we propose a GNN generation pipeline with a novel two-stage search space, which aims at automatically generating high-performance while transferable deep GNN models in a block-wise manner. Meanwhile, to alleviate the 'over-smooth' problem, we incorporate multiple flexible residual connection in our search space and apply identity mapping in the basic GNN layers. For the search algorithm, we use deep-q-learning with epsilon-greedy exploration strategy and reward reshaping. Extensive experiments on real-world datasets show that our generated GNN models outperforms existing manually designed and NAS-based ones.
TENSILE: A Tensor granularity dynamic GPU memory scheduler method towards multiple dynamic workloads system
May 28, 2021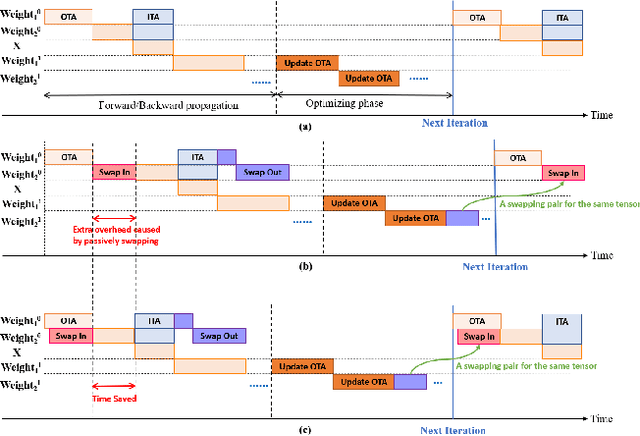
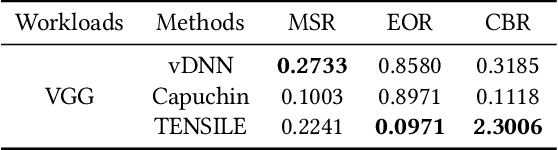
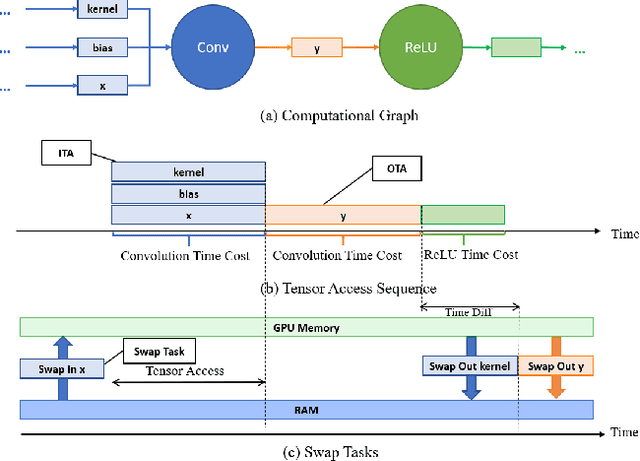
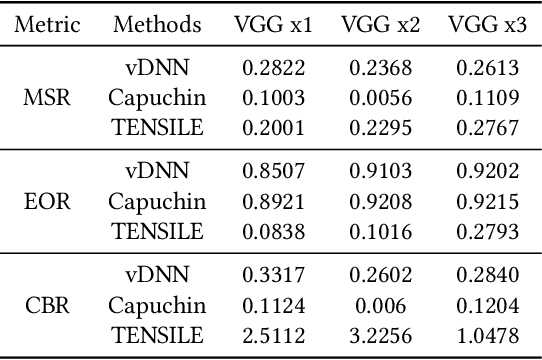
Recently, deep learning has been an area of intense researching. However, as a kind of computing intensive task, deep learning highly relies on the the scale of the GPU memory, which is usually expensive and scarce. Although there are some extensive works have been proposed for dynamic GPU memory management, they are hard to be applied to systems with multitasking dynamic workloads, such as in-database machine learning system. In this paper, we demonstrated TENSILE, a method of managing GPU memory in tensor granularity to reduce the GPU memory peak, with taking the multitasking dynamic workloads into consideration. As far as we know, TENSILE is the first method which is designed to manage multiple workloads' GPU memory using. We implement TENSILE on our own deep learning framework, and evaluated its performance. The experiment results shows that our method can achieve less time overhead than prior works with more GPU memory saved.
FL-AGCNS: Federated Learning Framework for Automatic Graph Convolutional Network Search
Apr 09, 2021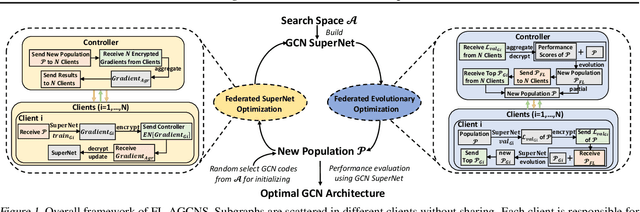
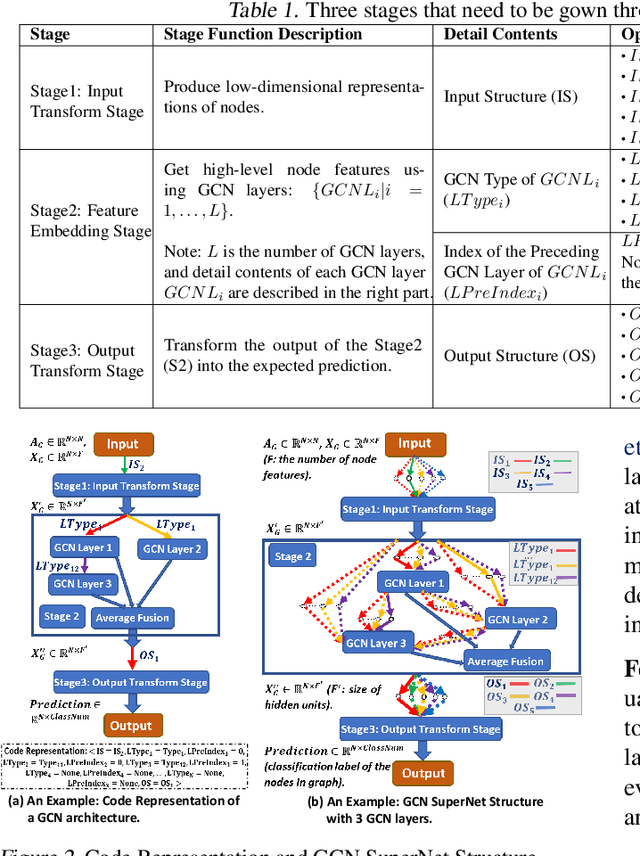
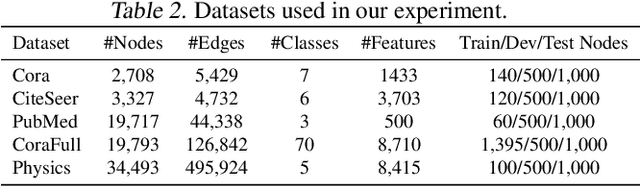
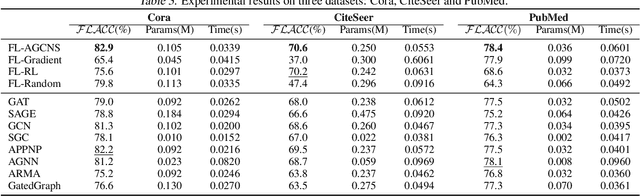
Recently, some Neural Architecture Search (NAS) techniques are proposed for the automatic design of Graph Convolutional Network (GCN) architectures. They bring great convenience to the use of GCN, but could hardly apply to the Federated Learning (FL) scenarios with distributed and private datasets, which limit their applications. Moreover, they need to train many candidate GCN models from scratch, which is inefficient for FL. To address these challenges, we propose FL-AGCNS, an efficient GCN NAS algorithm suitable for FL scenarios. FL-AGCNS designs a federated evolutionary optimization strategy to enable distributed agents to cooperatively design powerful GCN models while keeping personal information on local devices. Besides, it applies the GCN SuperNet and a weight sharing strategy to speed up the evaluation of GCN models. Experimental results show that FL-AGCNS can find better GCN models in short time under the FL framework, surpassing the state-of-the-arts NAS methods and GCN models.
Approximate Query Processing for Group-By Queries based on Conditional Generative Models
Jan 08, 2021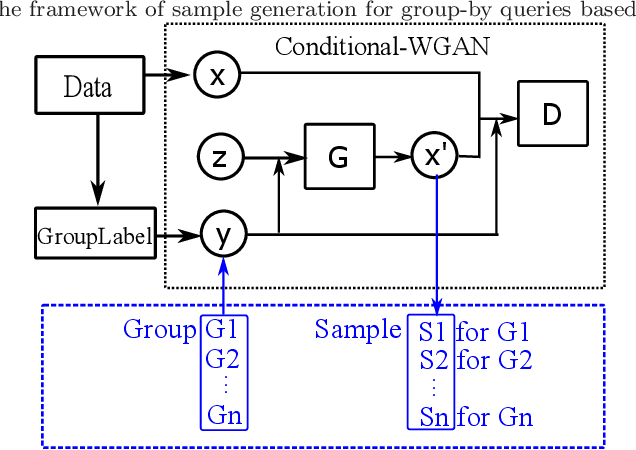

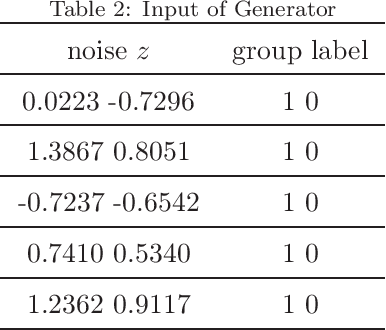
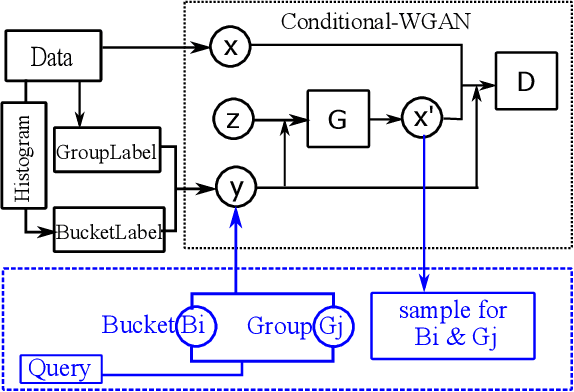
The Group-By query is an important kind of query, which is common and widely used in data warehouses, data analytics, and data visualization. Approximate query processing is an effective way to increase the querying efficiency on big data. The answer to a group-by query involves multiple values, which makes it difficult to provide sufficiently accurate estimations for all the groups. Stratified sampling improves the accuracy compared with the uniform sampling, but the samples chosen for some special queries cannot work for other queries. Online sampling chooses samples for the given query at query time, but it requires a long latency. Thus, it is a challenge to achieve both accuracy and efficiency at the same time. Facing such challenge, in this work, we propose a sample generation framework based on a conditional generative model. The sample generation framework can generate any number of samples for the given query without accessing the data. The proposed framework based on the lightweight model can be combined with stratified sampling and online aggregation to improve the estimation accuracy for group-by queries. The experimental results show that our proposed methods are both efficient and accurate.
Auto-STGCN: Autonomous Spatial-Temporal Graph Convolutional Network Search Based on Reinforcement Learning and Existing Research Results
Oct 15, 2020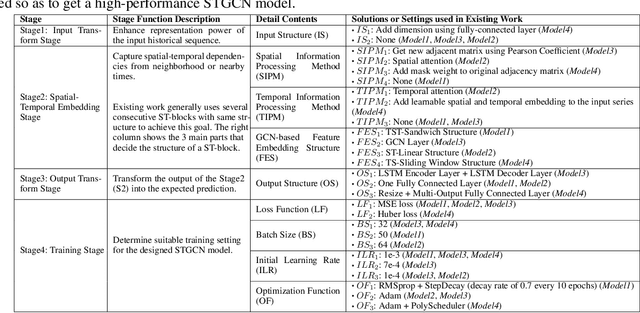
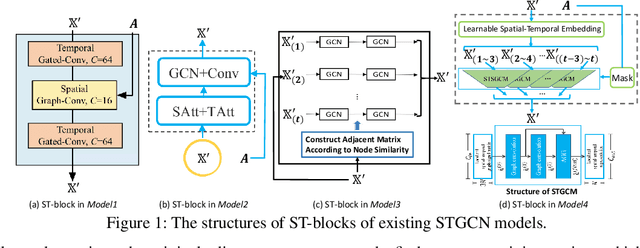
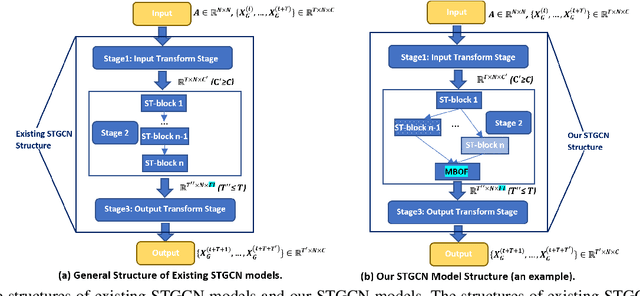
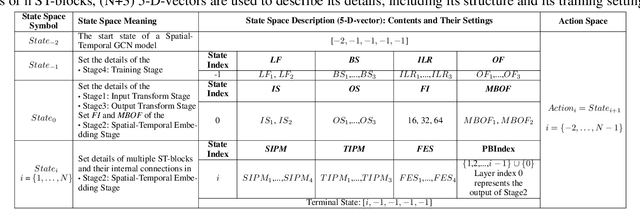
In recent years, many spatial-temporal graph convolutional network (STGCN) models are proposed to deal with the spatial-temporal network data forecasting problem. These STGCN models have their own advantages, i.e., each of them puts forward many effective operations and achieves good prediction results in the real applications. If users can effectively utilize and combine these excellent operations integrating the advantages of existing models, then they may obtain more effective STGCN models thus create greater value using existing work. However, they fail to do so due to the lack of domain knowledge, and there is lack of automated system to help users to achieve this goal. In this paper, we fill this gap and propose Auto-STGCN algorithm, which makes use of existing models to automatically explore high-performance STGCN model for specific scenarios. Specifically, we design Unified-STGCN framework, which summarizes the operations of existing architectures, and use parameters to control the usage and characteristic attributes of each operation, so as to realize the parameterized representation of the STGCN architecture and the reorganization and fusion of advantages. Then, we present Auto-STGCN, an optimization method based on reinforcement learning, to quickly search the parameter search space provided by Unified-STGCN, and generate optimal STGCN models automatically. Extensive experiments on real-world benchmark datasets show that our Auto-STGCN can find STGCN models superior to existing STGCN models with heuristic parameters, which demonstrates the effectiveness of our proposed method.