 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Communication-Efficient Federated Learning based on Differentially Private Sketches
Oct 10, 2024



Federated learning (FL) faces two primary challenges: the risk of privacy leakage due to parameter sharing and communication inefficiencies. To address these challenges, we propose DPSFL, a federated learning method that utilizes differentially private sketches. DPSFL compresses the local gradients of each client using a count sketch, thereby improving communication efficiency, while adding noise to the sketches to ensure differential privacy (DP). We provide a theoretical analysis of privacy and convergence for the proposed method. Gradient clipping is essential in DP learning to limit sensitivity and constrain the addition of noise. However, clipping introduces bias into the gradients, negatively impacting FL performance. To mitigate the impact of clipping, we propose an enhanced method, DPSFL-AC, which employs an adaptive clipping strategy. Experimental comparisons with existing techniques demonstrate the superiority of our methods concerning privacy preservation, communication efficiency, and model accuracy.
Partition-based differentially private synthetic data generation
Oct 10, 2023Private synthetic data sharing is preferred as it keeps the distribution and nuances of original data compared to summary statistics. The state-of-the-art methods adopt a select-measure-generate paradigm, but measuring large domain marginals still results in much error and allocating privacy budget iteratively is still difficult. To address these issues, our method employs a partition-based approach that effectively reduces errors and improves the quality of synthetic data, even with a limited privacy budget. Results from our experiments demonstrate the superiority of our method over existing approaches. The synthetic data produced using our approach exhibits improved quality and utility, making it a preferable choice for private synthetic data sharing.
Approximate Query Processing for Group-By Queries based on Conditional Generative Models
Jan 08, 2021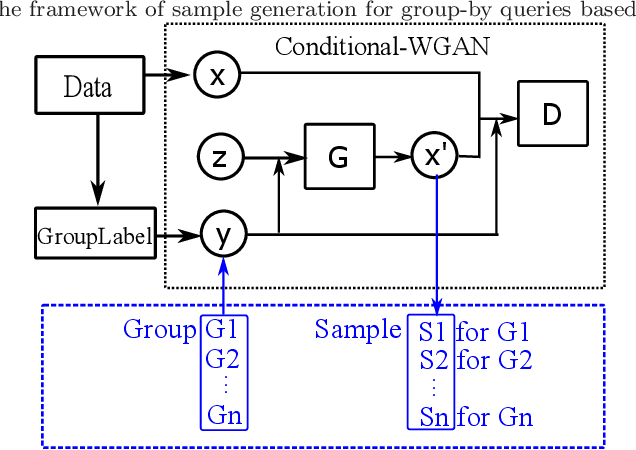

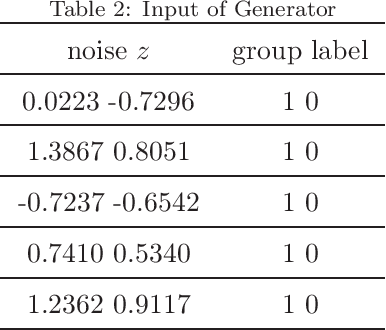
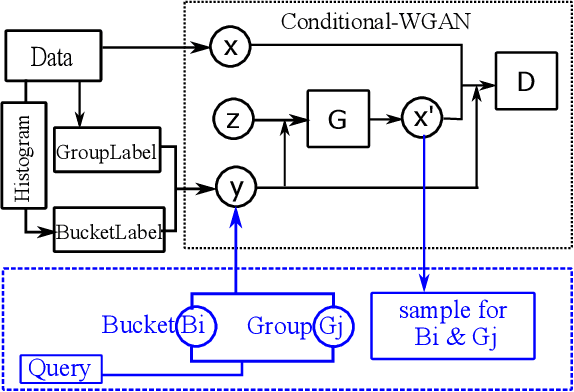
The Group-By query is an important kind of query, which is common and widely used in data warehouses, data analytics, and data visualization. Approximate query processing is an effective way to increase the querying efficiency on big data. The answer to a group-by query involves multiple values, which makes it difficult to provide sufficiently accurate estimations for all the groups. Stratified sampling improves the accuracy compared with the uniform sampling, but the samples chosen for some special queries cannot work for other queries. Online sampling chooses samples for the given query at query time, but it requires a long latency. Thus, it is a challenge to achieve both accuracy and efficiency at the same time. Facing such challenge, in this work, we propose a sample generation framework based on a conditional generative model. The sample generation framework can generate any number of samples for the given query without accessing the data. The proposed framework based on the lightweight model can be combined with stratified sampling and online aggregation to improve the estimation accuracy for group-by queries. The experimental results show that our proposed methods are both efficient and accurate.
LAQP: Learning-based Approximate Query Processing
Mar 05, 2020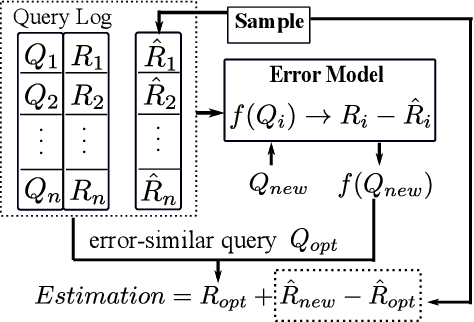
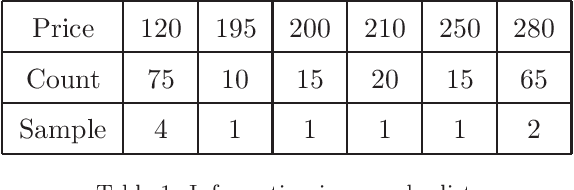
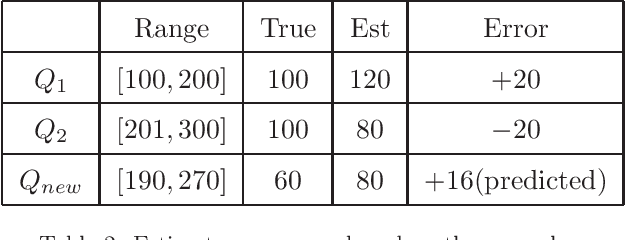
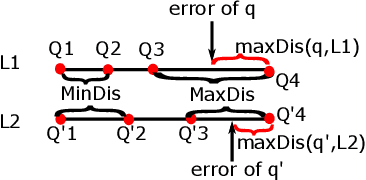
Querying on big data is a challenging task due to the rapid growth of data amount. Approximate query processing (AQP) is a way to meet the requirement of fast response. In this paper, we propose a learning-based AQP method called the LAQP. The LAQP builds an error model learned from the historical queries to predict the sampling-based estimation error of each new query. It makes a combination of the sampling-based AQP, the pre-computed aggregations and the learned error model to provide high-accurate query estimations with a small off-line sample. The experimental results indicate that our LAQP outperforms the sampling-based AQP, the pre-aggregation-based AQP and the most recent learning-based AQP method.