 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuet: efficient and scalable hybriD neUral rElation undersTanding
Jul 28, 2023Learned cardinality estimation methods have achieved high precision compared to traditional methods. Among learned methods, query-driven approaches face the data and workload drift problem for a long time. Although both query-driven and hybrid methods are proposed to avoid this problem, even the state-of-the-art of them suffer from high training and estimation costs, limited scalability, instability, and long-tailed distribution problem on high cardinality and high-dimensional tables, which seriously affects the practical application of learned cardinality estimators. In this paper, we prove that most of these problems are directly caused by the widely used progressive sampling. We solve this problem by introducing predicates information into the autoregressive model and propose Duet, a stable, efficient, and scalable hybrid method to estimate cardinality directly without sampling or any non-differentiable process, which can not only reduces the inference complexity from O(n) to O(1) compared to Naru and UAE but also achieve higher accuracy on high cardinality and high-dimensional tables. Experimental results show that Duet can achieve all the design goals above and be much more practical and even has a lower inference cost on CPU than that of most learned methods on GPU.
MaxCorrMGNN: A Multi-Graph Neural Network Framework for Generalized Multimodal Fusion of Medical Data for Outcome Prediction
Jul 13, 2023


With the emergence of multimodal electronic health records, the evidence for an outcome may be captured across multiple modalities ranging from clinical to imaging and genomic data. Predicting outcomes effectively requires fusion frameworks capable of modeling fine-grained and multi-faceted complex interactions between modality features within and across patients. We develop an innovative fusion approach called MaxCorr MGNN that models non-linear modality correlations within and across patients through Hirschfeld-Gebelein-Renyi maximal correlation (MaxCorr) embeddings, resulting in a multi-layered graph that preserves the identities of the modalities and patients. We then design, for the first time, a generalized multi-layered graph neural network (MGNN) for task-informed reasoning in multi-layered graphs, that learns the parameters defining patient-modality graph connectivity and message passing in an end-to-end fashion. We evaluate our model an outcome prediction task on a Tuberculosis (TB) dataset consistently outperforming several state-of-the-art neural, graph-based and traditional fusion techniques.
Contrastive Shapelet Learning for Unsupervised Multivariate Time Series Representation Learning
Jun 02, 2023



Recent studies have shown great promise in unsupervised representation learning (URL) for multivariate time series, because URL has the capability in learning generalizable representation for many downstream tasks without using inaccessible labels. However, existing approaches usually adopt the models originally designed for other domains (e.g., computer vision) to encode the time series data and rely on strong assumptions to design learning objectives, which limits their ability to perform well. To deal with these problems, we propose a novel URL framework for multivariate time series by learning time-series-specific shapelet-based representation through a popular contrasting learning paradigm. To the best of our knowledge, this is the first work that explores the shapelet-based embedding in the unsupervised general-purpose representation learning. A unified shapelet-based encoder and a novel learning objective with multi-grained contrasting and multi-scale alignment are particularly designed to achieve our goal, and a data augmentation library is employed to improve the generalization. We conduct extensive experiments using tens of real-world datasets to assess the representation quality on many downstream tasks, including classification, clustering, and anomaly detection. The results demonstrate the superiority of our method against not only URL competitors, but also techniques specially designed for downstream tasks. Our code has been made publicly available at https://github.com/real2fish/CSL.
TodyNet: Temporal Dynamic Graph Neural Network for Multivariate Time Series Classification
Apr 11, 2023Multivariate time series classification (MTSC) is an important data mining task, which can be effectively solved by popular deep learning technology. Unfortunately, the existing deep learning-based methods neglect the hidden dependencies in different dimensions and also rarely consider the unique dynamic features of time series, which lack sufficient feature extraction capability to obtain satisfactory classification accuracy. To address this problem, we propose a novel temporal dynamic graph neural network (TodyNet) that can extract hidden spatio-temporal dependencies without undefined graph structure. It enables information flow among isolated but implicit interdependent variables and captures the associations between different time slots by dynamic graph mechanism, which further improves the classification performance of the model. Meanwhile, the hierarchical representations of graphs cannot be learned due to the limitation of GNNs. Thus, we also design a temporal graph pooling layer to obtain a global graph-level representation for graph learning with learnable temporal parameters. The dynamic graph, graph information propagation, and temporal convolution are jointly learned in an end-to-end framework. The experiments on 26 UEA benchmark datasets illustrate that the proposed TodyNet outperforms existing deep learning-based methods in the MTSC tasks.
UniTS: A Universal Time Series Analysis Framework with Self-supervised Representation Learning
Mar 24, 2023Machine learning has emerged as a powerful tool for time series analysis. Existing methods are usually customized for different analysis tasks and face challenges in tackling practical problems such as partial labeling and domain shift. To achieve universal analysis and address the aforementioned problems, we develop UniTS, a novel framework that incorporates self-supervised representation learning (or pre-training). The components of UniTS are designed using sklearn-like APIs to allow flexible extensions. We demonstrate how users can easily perform an analysis task using the user-friendly GUIs, and show the superior performance of UniTS over the traditional task-specific methods without self-supervised pre-training on five mainstream tasks and two practical settings.
FedST: Privacy Preserving Federated Shapelet Transformation for Interpretable Time Series Classification
Mar 02, 2023This paper studies how to develop accurate and interpretable time series classification (TSC) models with the help of external data in a privacy-preserving federated learning (FL) scenario. To the best of our knowledge, we are the first to study on this essential topic. Achieving this goal requires us to seamlessly integrate the techniques from multiple fields including Data Mining, Machine Learning, and Security. In this paper, we formulate the problem and identify the interpretability constraints under the FL setting. We systematically investigate existing TSC solutions for the centralized scenario and propose FedST, a novel FL-enabled TSC framework based on a shapelet transformation method. We recognize the federated shapelet search step as the kernel of FedST. Thus, we design $\Pi_{FedSS-B}$, a basic protocol for the FedST kernel that we prove to be secure and accurate. Further, we identify the efficiency bottlenecks of the basic protocol and propose optimizations tailored for the FL setting for acceleration. Our theoretical analysis shows that the proposed optimizations are secure and more efficient. We conduct extensive experiments using both synthetic and real-world datasets. Empirical results show that our FedST solution is effective in terms of TSC accuracy, and the proposed optimizations can achieve three orders of magnitude of speedup.
DCLP: Neural Architecture Predictor with Curriculum Contrastive Learning
Feb 25, 2023



Neural predictors currently show great potential in the performance evaluation phase of neural architecture search (NAS). Despite their efficiency in the evaluation process, it is challenging to train the predictor with fewer architecture evaluations for efficient NAS. However, most of the current approaches are more concerned with improving the structure of the predictor to solve this problem, while the full use of the information contained in unlabeled data is less explored. To address this issue, we introduce a contrastive learning framework with curriculum learning guidance for the neural predictor called DCLP. To be specific, we develop a plan for the training order of positive samples during pre-training through the proposed difficulty measurer and training scheduler, and utilize the contrastive learner to learn representations of data. Compared with existing predictors, we experimentally demonstrate that DCLP has high accuracy and efficiency, and also shows an encouraging ability to discover superior architectures in multiple search spaces when combined with search strategies.
Fusing Modalities by Multiplexed Graph Neural Networks for Outcome Prediction in Tuberculosis
Oct 25, 2022In a complex disease such as tuberculosis, the evidence for the disease and its evolution may be present in multiple modalities such as clinical, genomic, or imaging data. Effective patient-tailored outcome prediction and therapeutic guidance will require fusing evidence from these modalities. Such multimodal fusion is difficult since the evidence for the disease may not be uniform across all modalities, not all modality features may be relevant, or not all modalities may be present for all patients. All these nuances make simple methods of early, late, or intermediate fusion of features inadequate for outcome prediction. In this paper, we present a novel fusion framework using multiplexed graphs and derive a new graph neural network for learning from such graphs. Specifically, the framework allows modalities to be represented through their targeted encodings, and models their relationship explicitly via multiplexed graphs derived from salient features in a combined latent space. We present results that show that our proposed method outperforms state-of-the-art methods of fusing modalities for multi-outcome prediction on a large Tuberculosis (TB) dataset.
Differentiable Self-Adaptive Learning Rate
Oct 19, 2022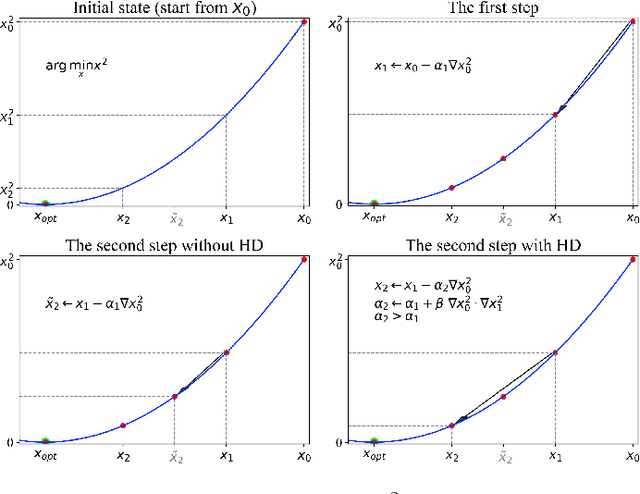
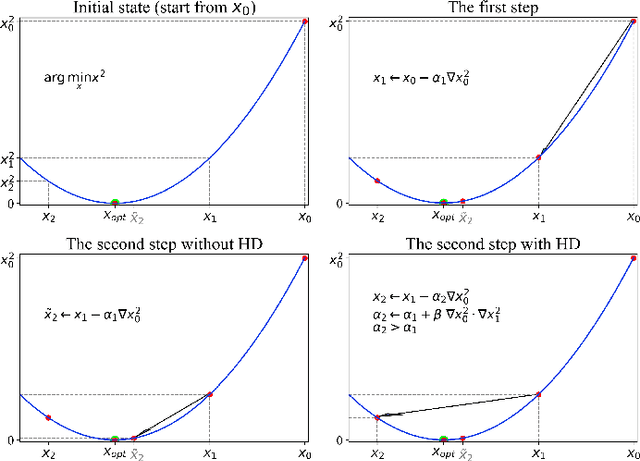
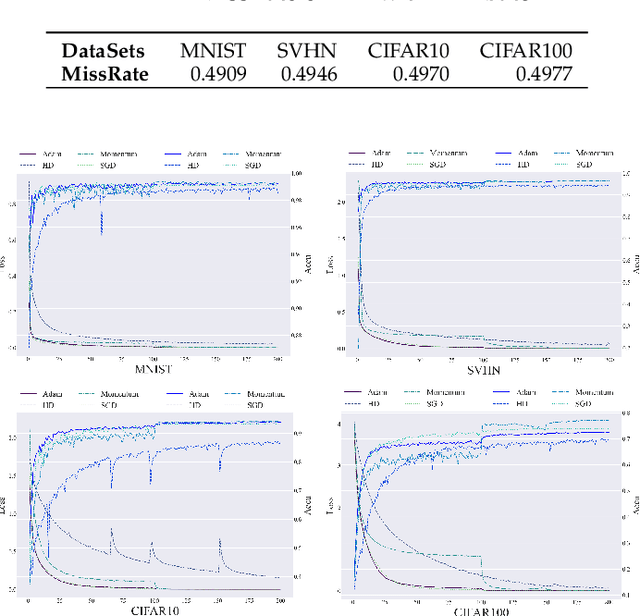
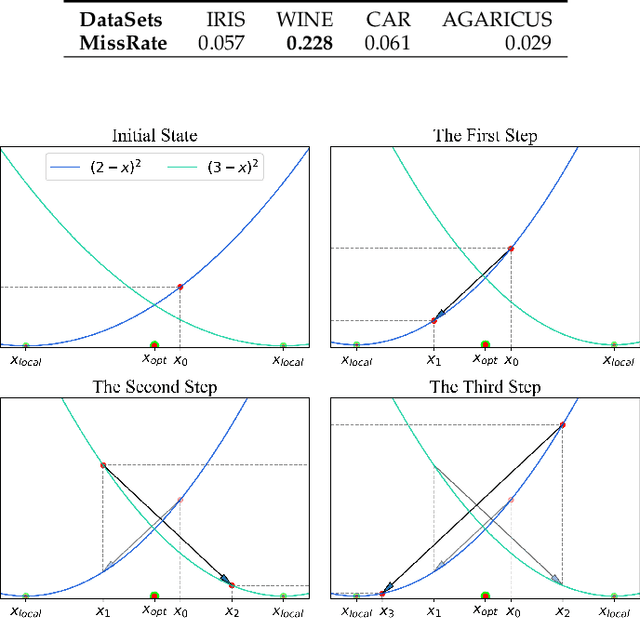
Learning rate adaptation is a popular topic in machine learning. Gradient Descent trains neural nerwork with a fixed learning rate. Learning rate adaptation is proposed to accelerate the training process through adjusting the step size in the training session. Famous works include Momentum, Adam and Hypergradient. Hypergradient is the most special one. Hypergradient achieved adaptation by calculating the derivative of learning rate with respect to cost function and utilizing gradient descent for learning rate. However, Hypergradient is still not perfect. In practice, Hypergradient fail to decrease training loss after learning rate adaptation with a large probability. Apart from that, evidence has been found that Hypergradient are not suitable for dealing with large datesets in the form of minibatch training. Most unfortunately, Hypergradient always fails to get a good accuracy on the validation dataset although it could reduce training loss to a very tiny value. To solve Hypergradient's problems, we propose a novel adaptation algorithm, where learning rate is parameter specific and internal structured. We conduct extensive experiments on multiple network models and datasets compared with various benchmark optimizers. It is shown that our algorithm can achieve faster and higher qualified convergence than those state-of-art optimizers.
EEML: Ensemble Embedded Meta-learning
Jun 18, 2022


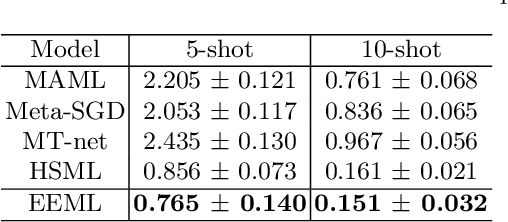
To accelerate learning process with few samples, meta-learning resorts to prior knowledge from previous tasks. However, the inconsistent task distribution and heterogeneity is hard to be handled through a global sharing model initialization. In this paper, based on gradient-based meta-learning, we propose an ensemble embedded meta-learning algorithm (EEML) that explicitly utilizes multi-model-ensemble to organize prior knowledge into diverse specific experts. We rely on a task embedding cluster mechanism to deliver diverse tasks to matching experts in training process and instruct how experts collaborate in test phase. As a result, the multi experts can focus on their own area of expertise and cooperate in upcoming task to solve the task heterogeneity. The experimental results show that the proposed method outperforms recent state-of-the-arts easily in few-shot learning problem, which validates the importance of differentiation and cooperation.