 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Communication and Computational Imaging
Oct 29, 2024



Communication enables the expansion of human visual perception beyond the limitations of time and distance, while computational imaging overcomes the constraints of depth and breadth. Although impressive achievements have been witnessed with the two types of technologies, the occlusive information flow between the two domains is a bottleneck hindering their ulterior progression. Herein, we propose a novel framework that integrates communication and computational imaging (ICCI) to break through the inherent isolation between communication and computational imaging for remote perception. By jointly considering the sensing and transmitting of remote visual information, the ICCI framework performs a full-link information transfer optimization, aiming to minimize information loss from the generation of the information source to the execution of the final vision tasks. We conduct numerical analysis and experiments to demonstrate the ICCI framework by integrating communication systems and snapshot compressive imaging systems. Compared with straightforward combination schemes, which sequentially execute sensing and transmitting, the ICCI scheme shows greater robustness against channel noise and impairments while achieving higher data compression. Moreover, an 80 km 27-band hyperspectral video perception with a rate of 30 fps is experimentally achieved. This new ICCI remote perception paradigm offers a highefficiency solution for various real-time computer vision tasks.
Comparative Analysis of Novel View Synthesis and Photogrammetry for 3D Forest Stand Reconstruction and extraction of individual tree parameters
Oct 08, 2024



Accurate and efficient 3D reconstruction of trees is crucial for forest resource assessments and management. Close-Range Photogrammetry (CRP) is commonly used for reconstructing forest scenes but faces challenges like low efficiency and poor quality. Recently, Novel View Synthesis (NVS) technologies, including Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have shown promise for 3D plant reconstruction with limited images. However, existing research mainly focuses on small plants in orchards or individual trees, leaving uncertainty regarding their application in larger, complex forest stands. In this study, we collected sequential images of forest plots with varying complexity and performed dense reconstruction using NeRF and 3DGS. The resulting point clouds were compared with those from photogrammetry and laser scanning. Results indicate that NVS methods significantly enhance reconstruction efficiency. Photogrammetry struggles with complex stands, leading to point clouds with excessive canopy noise and incorrectly reconstructed trees, such as duplicated trunks. NeRF, while better for canopy regions, may produce errors in ground areas with limited views. The 3DGS method generates sparser point clouds, particularly in trunk areas, affecting diameter at breast height (DBH) accuracy. All three methods can extract tree height information, with NeRF yielding the highest accuracy; however, photogrammetry remains superior for DBH accuracy. These findings suggest that NVS methods have significant potential for 3D reconstruction of forest stands, offering valuable support for complex forest resource inventory and visualization tasks.
Atmospheric Turbulence-Immune Free Space Optical Communication System based on Discrete-Time Analog Transmission
Sep 18, 2024



To effectively mitigate the influence of atmospheric turbulence, a novel discrete-time analog transmission free-space optical (DTAT-FSO) communication scheme is proposed. It directly maps information sources to discrete-time analog symbols via joint source-channel coding and modulation. Differently from traditional digital free space optical (TD-FSO) schemes, the proposed DTAT-FSO approach can automatically adapt to the variation of the channel state, with no need to adjust the specific modulation and coding scheme. The performance of the DTAT-FSO system was evaluated in both intensity modulation/direct detection (IM/DD) and coherent FSO systems for high-resolution image transmission. The results show that the DTAT-FSO reliably transmits images at low received optical powers (ROPs) and automatically enhances quality at high ROPs, while the TD-FSO experiences cliff and leveling effects when the channel state varies. With respect to the TD-FSO scheme, the DTAT-FSO scheme improved receiver sensitivity by 2.5 dB in the IM/DD FSO system and 0.8 dB in the coherent FSO system, and it achieved superior image fidelity under the same ROP. The automatic adaptation feature and improved performance of the DTAT-FSO suggest its potential for terrestrial, airborne, and satellite optical networks, addressing challenges posed by atmospheric turbulence.
Evaluating the point cloud of individual trees generated from images based on Neural Radiance fields (NeRF) method
Dec 06, 2023Three-dimensional (3D) reconstruction of trees has always been a key task in precision forestry management and research. Due to the complex branch morphological structure of trees themselves and the occlusions from tree stems, branches and foliage, it is difficult to recreate a complete three-dimensional tree model from a two-dimensional image by conventional photogrammetric methods. In this study, based on tree images collected by various cameras in different ways, the Neural Radiance Fields (NeRF) method was used for individual tree reconstruction and the exported point cloud models are compared with point cloud derived from photogrammetric reconstruction and laser scanning methods. The results show that the NeRF method performs well in individual tree 3D reconstruction, as it has higher successful reconstruction rate, better reconstruction in the canopy area, it requires less amount of images as input. Compared with photogrammetric reconstruction method, NeRF has significant advantages in reconstruction efficiency and is adaptable to complex scenes, but the generated point cloud tends to be noisy and low resolution. The accuracy of tree structural parameters (tree height and diameter at breast height) extracted from the photogrammetric point cloud is still higher than those of derived from the NeRF point cloud. The results of this study illustrate the great potential of NeRF method for individual tree reconstruction, and it provides new ideas and research directions for 3D reconstruction and visualization of complex forest scenes.
Semantic optical fiber communication system
Dec 27, 2022



The current optical communication systems minimize bit or symbol errors without considering the semantic meaning behind digital bits, thus transmitting a lot of unnecessary information. We propose and experimentally demonstrate a semantic optical fiber communication (SOFC) system. Instead of encoding information into bits for transmission, semantic information is extracted from the source using deep learning. The generated semantic symbols are then directly transmitted through an optical fiber. Compared with the bit-based structure, the SOFC system achieved higher information compression and a more stable performance, especially in the low received optical power regime, and enhanced the robustness against optical link impairments. This work introduces an intelligent optical communication system at the human analytical thinking level, which is a significant step toward a breakthrough in the current optical communication architecture.
Federated Learning with Domain Generalization
Nov 20, 2021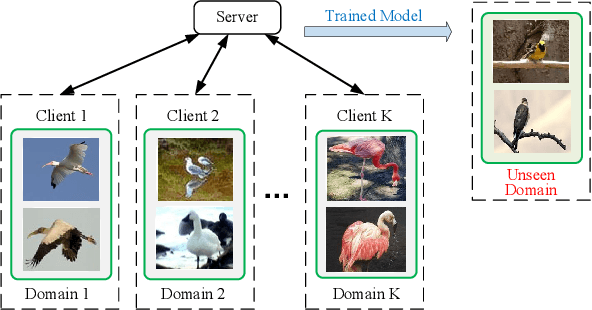

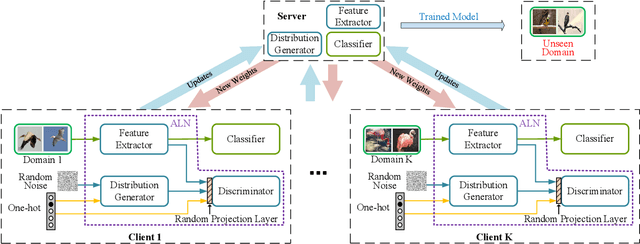

Federated Learning (FL) enables a group of clients to jointly train a machine learning model with the help of a centralized server. Clients do not need to submit their local data to the server during training, and hence the local training data of clients is protected. In FL, distributed clients collect their local data independently, so the dataset of each client may naturally form a distinct source domain. In practice, the model trained over multiple source domains may have poor generalization performance on unseen target domains. To address this issue, we propose FedADG to equip federated learning with domain generalization capability. FedADG employs the federated adversarial learning approach to measure and align the distributions among different source domains via matching each distribution to a reference distribution. The reference distribution is adaptively generated (by accommodating all source domains) to minimize the domain shift distance during alignment. In FedADG, the alignment is fine-grained since each class is aligned independently. In this way, the learned feature representation is supposed to be universal, so it can generalize well on the unseen domains. Extensive experiments on various datasets demonstrate that FedADG has better performance than most of the previous solutions even if they have an additional advantage that allows centralized data access. To support study reproducibility, the project codes are available in https://github.com/wzml/FedADG
Multi-sequence Cardiac MR Segmentation with Adversarial Domain Adaptation Network
Oct 28, 2019
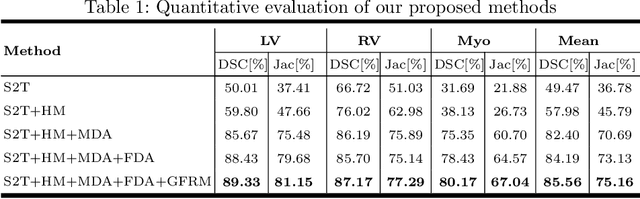
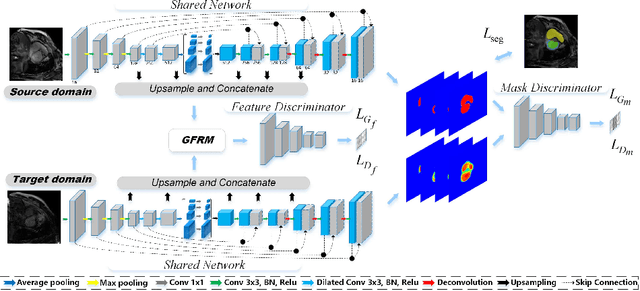
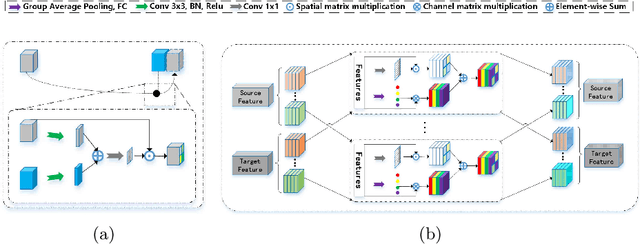
Automatic and accurate segmentation of the ventricles and myocardium from multi-sequence cardiac MRI (CMR) is crucial for the diagnosis and treatment management for patients suffering from myocardial infarction (MI). However, due to the existence of domain shift among different modalities of datasets, the performance of deep neural networks drops significantly when the training and testing datasets are distinct. In this paper, we propose an unsupervised domain alignment method to explicitly alleviate the domain shifts among different modalities of CMR sequences, \emph{e.g.,} bSSFP, LGE, and T2-weighted. Our segmentation network is attention U-Net with pyramid pooling module, where multi-level feature space and output space adversarial learning are proposed to transfer discriminative domain knowledge across different datasets. Moreover, we further introduce a group-wise feature recalibration module to enforce the fine-grained semantic-level feature alignment that matching features from different networks but with the same class label. We evaluate our method on the multi-sequence cardiac MR Segmentation Challenge 2019 datasets, which contain three different modalities of MRI sequences. Extensive experimental results show that the proposed methods can obtain significant segmentation improvements compared with the baseline models.