 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractMIA: Black-Box Membership Inference on Vision-Language Models via Semantic Distraction
May 12, 2026Vision-language models (VLMs) are trained on large-scale image-text corpora that may contain private, copyrighted, or otherwise sensitive data, motivating membership inference as a tool for training-data auditing. This is especially challenging for deployed VLMs, where auditors typically observe only generated textual responses. Existing VLM membership inference attacks either rely on probability-level signals unavailable in such settings, or use mask-based semantic prediction tasks whose effectiveness depends on object-centric visual assumptions. To address these limitations, we propose DistractMIA, an output-only black-box framework based on semantic distraction. Rather than removing visual evidence, DistractMIA preserves the original image, inserts a known semantic distractor, and measures how generated responses change. This design is motivated by the intuition that member samples remain more anchored to the original image semantics, while non-member samples are more easily redirected toward the distractor. To make this signal reliable, DistractMIA calibrates distractor configurations on a reference set and derives membership scores from repeated textual generations, capturing response stability and distractor uptake without accessing logits, probabilities, or hidden states. Experiments across multiple VLMs and benchmarks show that DistractMIA consistently outperforms both output-only and stronger-access baselines. Its performance on a medical benchmark further demonstrates applicability beyond object-centric natural images.
Identifying Pre-training Data in LLMs: A Neuron Activation-Based Detection Framework
Jul 22, 2025The performance of large language models (LLMs) is closely tied to their training data, which can include copyrighted material or private information, raising legal and ethical concerns. Additionally, LLMs face criticism for dataset contamination and internalizing biases. To address these issues, the Pre-Training Data Detection (PDD) task was proposed to identify if specific data was included in an LLM's pre-training corpus. However, existing PDD methods often rely on superficial features like prediction confidence and loss, resulting in mediocre performance. To improve this, we introduce NA-PDD, a novel algorithm analyzing differential neuron activation patterns between training and non-training data in LLMs. This is based on the observation that these data types activate different neurons during LLM inference. We also introduce CCNewsPDD, a temporally unbiased benchmark employing rigorous data transformations to ensure consistent time distributions between training and non-training data. Our experiments demonstrate that NA-PDD significantly outperforms existing methods across three benchmarks and multiple LLMs.
Sogou Machine Reading Comprehension Toolkit
Apr 01, 2019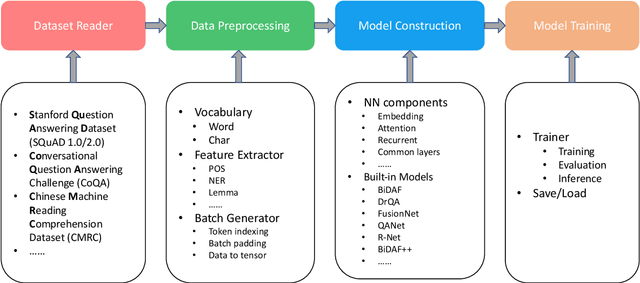
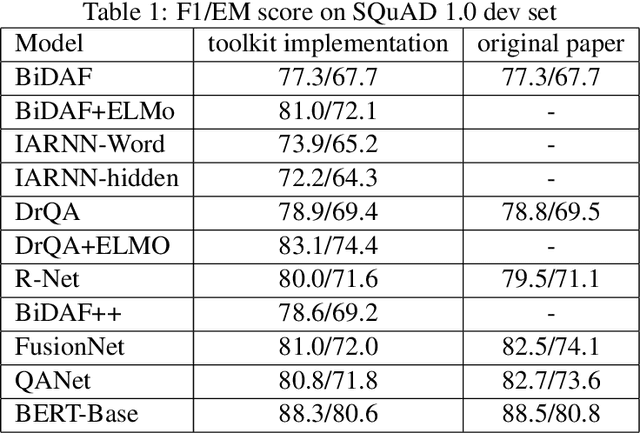
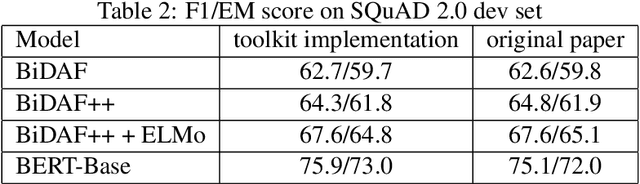
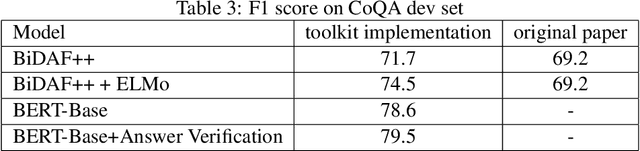
Machine reading comprehension have been intensively studied in recent years, and neural network-based models have shown dominant performances. In this paper, we present a Sogou Machine Reading Comprehension (SMRC) toolkit that can be used to provide the fast and efficient development of modern machine comprehension models, including both published models and original prototypes. To achieve this goal, the toolkit provides dataset readers, a flexible preprocessing pipeline, necessary neural network components, and built-in models, which make the whole process of data preparation, model construction, and training easier.