 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
May 19, 2026Long-form image captioning exposes a reward granularity problem in RL: captions are judged as whole sequences, while the important errors occur at the level of individual visual claims. A good dense caption should be both faithful and informative, avoiding hallucination without omitting salient details. Yet pairwise preferences, reference-based metrics, and holistic scalar rewards compress these local errors into a single sequence-level signal, obscuring the tradeoff between factuality and coverage. We introduce ClaimDiff-RL, a framework that uses reference-conditioned atomic claim differences as the reward unit for caption RL. Given an image, an actor caption, and a reference caption, a multimodal judge enumerates visually grounded differences, verifies each difference against the image, assigns open-vocabulary error types and severity levels, and produces per-difference statistics for reward composition. This makes hallucinated claims and omitted salient facts separately measurable and tunable. Experiments show that holistic scalar rewards can reduce hallucination by increasing missing facts, while ClaimDiff-RL exposes this faithfulness and coverage tradeoff and enables more balanced operating points. On a 160-image human-labeled diagnostic benchmark, public captioning benchmarks, and VQA benchmarks, ClaimDiff-RL improves the hallucination--missing-fact balance, preserves general capability, and even surpasses Gemini-3-Pro-Preview on several fine-grained Capability dimensions such as object counting, spatial relations, and scene recognition. These results suggest that typed, verifiable claim differences are an effective reward unit for fine-grained and diagnosable caption RL.
AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
Nov 07, 2022



Accurate whole-body multi-person pose estimation and tracking is an important yet challenging topic in computer vision. To capture the subtle actions of humans for complex behavior analysis, whole-body pose estimation including the face, body, hand and foot is essential over conventional body-only pose estimation. In this paper, we present AlphaPose, a system that can perform accurate whole-body pose estimation and tracking jointly while running in realtime. To this end, we propose several new techniques: Symmetric Integral Keypoint Regression (SIKR) for fast and fine localization, Parametric Pose Non-Maximum-Suppression (P-NMS) for eliminating redundant human detections and Pose Aware Identity Embedding for jointly pose estimation and tracking. During training, we resort to Part-Guided Proposal Generator (PGPG) and multi-domain knowledge distillation to further improve the accuracy. Our method is able to localize whole-body keypoints accurately and tracks humans simultaneously given inaccurate bounding boxes and redundant detections. We show a significant improvement over current state-of-the-art methods in both speed and accuracy on COCO-wholebody, COCO, PoseTrack, and our proposed Halpe-FullBody pose estimation dataset. Our model, source codes and dataset are made publicly available at https://github.com/MVIG-SJTU/AlphaPose.
Cross-Domain Adaptation for Animal Pose Estimation
Aug 19, 2019
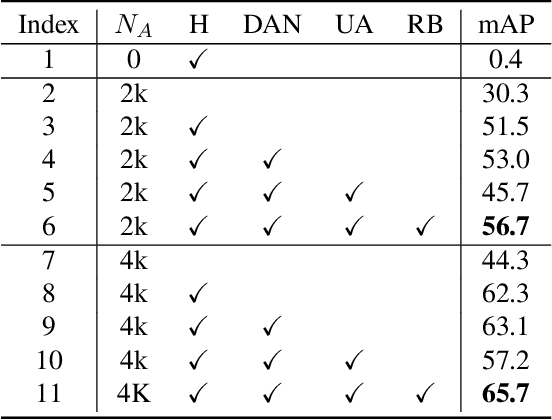
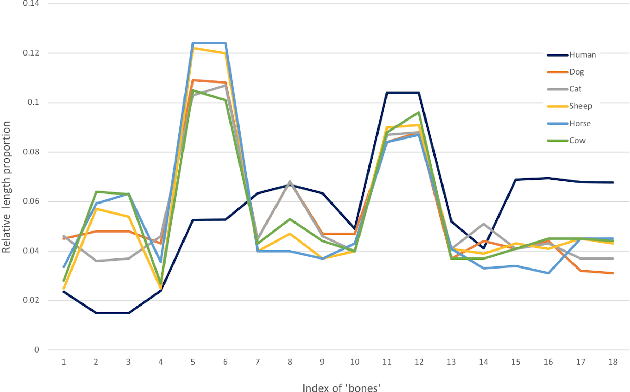
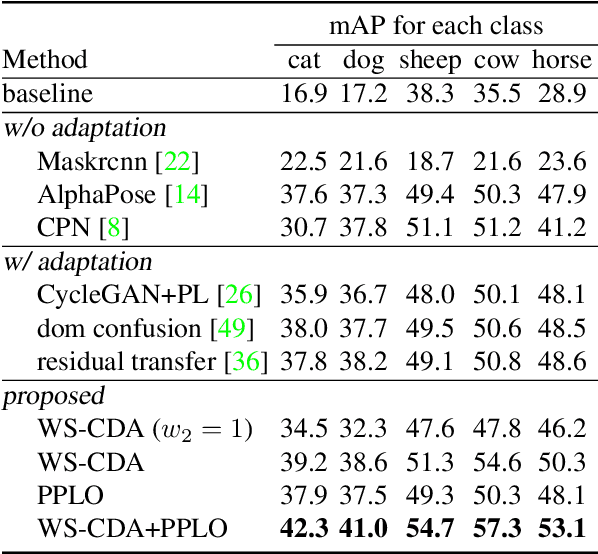
In this paper, we are interested in pose estimation of animals. Animals usually exhibit a wide range of variations on poses and there is no available animal pose dataset for training and testing. To address this problem, we build an animal pose dataset to facilitate training and evaluation. Considering the heavy labor needed to label dataset and it is impossible to label data for all concerned animal species, we, therefore, proposed a novel cross-domain adaptation method to transform the animal pose knowledge from labeled animal classes to unlabeled animal classes. We use the modest animal pose dataset to adapt learned knowledge to multiple animals species. Moreover, humans also share skeleton similarities with some animals (especially four-footed mammals). Therefore, the easily available human pose dataset, which is of a much larger scale than our labeled animal dataset, provides important prior knowledge to boost up the performance on animal pose estimation. Experiments show that our proposed method leverages these pieces of prior knowledge well and achieves convincing results on animal pose estimation.