 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF10.7 Index Prediction: A Multiscale Decomposition Strategy with Wavelet Transform for Performance Optimization
Feb 24, 2026In this study, we construct Dataset A for training, validation, and testing, and Dataset B to evaluate generalization. We propose a novel F10.7 index forecasting method using wavelet decomposition, which feeds F10.7 together with its decomposed approximate and detail signals into the iTransformer model. We also incorporate the International Sunspot Number (ISN) and its wavelet-decomposed signals to assess their influence on prediction performance. Our optimal method is then compared with the latest method from S. Yan et al. (2025) and three operational models (SWPC, BGS, CLS). Additionally, we transfer our method to the PatchTST model used in H. Ye et al. (2024) and compare our method with theirs on Dataset B. Key findings include: (1) The wavelet-based combination methods overall outperform the baseline using only F10.7 index. The prediction performance improves as higher-level approximate and detail signals are incrementally added. The Combination 6 method integrating F10.7 with its first to fifth level approximate and detail signals outperforms methods using only approximate or detail signals. (2) Incorporating ISN and its wavelet-decomposed signals does not enhance prediction performance. (3) The Combination 6 method significantly surpasses S. Yan et al. (2025) and three operational models, with RMSE, MAE, and MAPE reduced by 18.22%, 15.09%, and 8.57%, respectively, against the former method. It also excels across four different conditions of solar activity. (4) Our method demonstrates superior generalization and prediction capability over the method of H. Ye et al. (2024) across all forecast horizons. To our knowledge, this is the first application of wavelet decomposition in F10.7 prediction, substantially improving forecast performance.
Prediction of Major Solar Flares Using Interpretable Class-dependent Reward Framework with Active Region Magnetograms and Domain Knowledge
Feb 18, 2026In this work, we develop, for the first time, a supervised classification framework with class-dependent rewards (CDR) to predict $\geq$MM flares within 24 hr. We construct multiple datasets, covering knowledge-informed features and line-of sight (LOS) magnetograms. We also apply three deep learning models (CNN, CNN-BiLSTM, and Transformer) and three CDR counterparts (CDR-CNN, CDR-CNN-BiLSTM, and CDR-Transformer). First, we analyze the importance of LOS magnetic field parameters with the Transformer, then compare its performance using LOS-only, vector-only, and combined magnetic field parameters. Second, we compare flare prediction performance based on CDR models versus deep learning counterparts. Third, we perform sensitivity analysis on reward engineering for CDR models. Fourth, we use the SHAP method for model interpretability. Finally, we conduct performance comparison between our models and NASA/CCMC. The main findings are: (1)Among LOS feature combinations, R_VALUE and AREA_ACR consistently yield the best results. (2)Transformer achieves better performance with combined LOS and vector magnetic field data than with either alone. (3)Models using knowledge-informed features outperform those using magnetograms. (4)While CNN and CNN-BiLSTM outperform their CDR counterparts on magnetograms, CDR-Transformer is slightly superior to its deep learning counterpart when using knowledge-informed features. Among all models, CDR-Transformer achieves the best performance. (5)The predictive performance of the CDR models is not overly sensitive to the reward choices.(6)Through SHAP analysis, the CDR model tends to regard TOTUSJH as more important, while the Transformer tends to prioritize R_VALUE more.(7)Under identical prediction time and active region (AR) number, the CDR-Transformer shows superior predictive capabilities compared to NASA/CCMC.
Low-dose CT reconstruction by self-supervised learning in the projection domain
Mar 14, 2022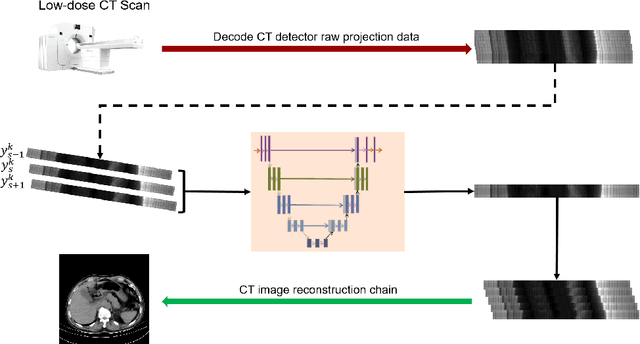
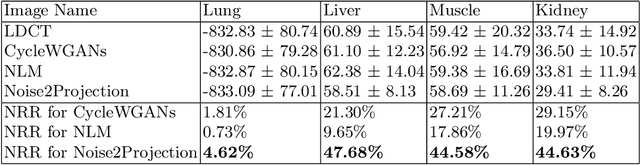

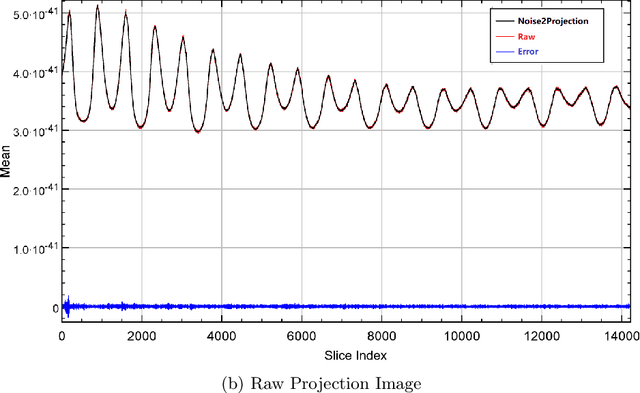
In the intention of minimizing excessive X-ray radiation administration to patients, low-dose computed tomography (LDCT) has become a distinct trend in radiology. However, while lowering the radiation dose reduces the risk to the patient, it also increases noise and artifacts, compromising image quality and clinical diagnosis. In most supervised learning methods, paired CT images are required, but such images are unlikely to be available in the clinic. We present a self-supervised learning model (Noise2Projection) that fully exploits the raw projection images to reduce noise and improve the quality of reconstructed LDCT images. Unlike existing self-supervised algorithms, the proposed method only requires noisy CT projection images and reduces noise by exploiting the correlation between nearby projection images. We trained and tested the model using clinical data and the quantitative and qualitative results suggest that our model can effectively reduce LDCT image noise while also drastically removing artifacts in LDCT images.
Unsupervised PET Reconstruction from a Bayesian Perspective
Oct 29, 2021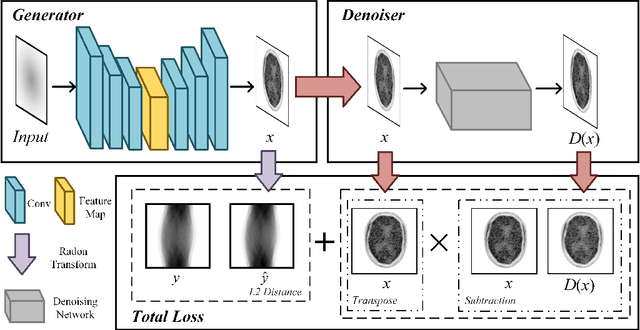

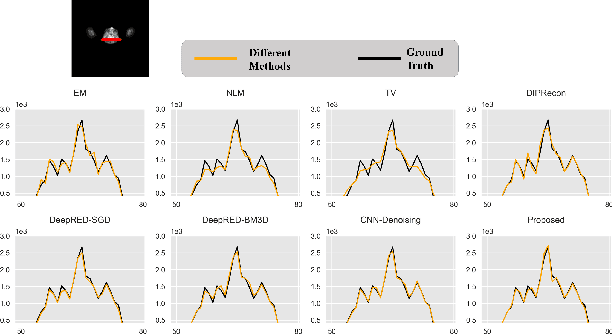
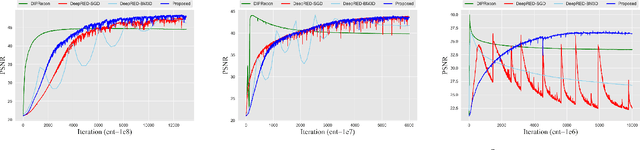
Positron emission tomography (PET) reconstruction has become an ill-posed inverse problem due to low-count projection data, and a robust algorithm is urgently required to improve imaging quality. Recently, the deep image prior (DIP) has drawn much attention and has been successfully applied in several image restoration tasks, such as denoising and inpainting, since it does not need any labels (reference image). However, overfitting is a vital defect of this framework. Hence, many methods have been proposed to mitigate this problem, and DeepRED is a typical representation that combines DIP and regularization by denoising (RED). In this article, we leverage DeepRED from a Bayesian perspective to reconstruct PET images from a single corrupted sinogram without any supervised or auxiliary information. In contrast to the conventional denoisers customarily used in RED, a DnCNN-like denoiser, which can add an adaptive constraint to DIP and facilitate the computation of derivation, is employed. Moreover, to further enhance the regularization, Gaussian noise is injected into the gradient updates, deriving a Markov chain Monte Carlo (MCMC) sampler. Experimental studies on brain and whole-body datasets demonstrate that our proposed method can achieve better performance in terms of qualitative and quantitative results compared to several classic and state-of-the-art methods.