 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DAWN of World-Action Interactive Models
May 12, 2026A plausible scene evolution depends on the maneuver being considered, while a good maneuver depends on how the scene may evolve. Existing World Action Models (WAMs) largely miss this reciprocity, treating world prediction and action generation as either isolated parallel branches or rigid predict-then-plan pipelines. We formalize this perspective as World-Action Interactive Models (WAIMs), and instantiate it in autonomous driving with \textbf{DAWN} (\textbf{D}enoising \textbf{A}ctions and \textbf{W}orld i\textbf{N}teractive model), a simple yet strong latent generative baseline. DAWN operates in a compact semantic latent space and couples a \emph{World Predictor} with a \emph{World-Conditioned Action Denoiser}: the predicted world hypothesis conditions action denoising, while the denoised action hypothesis is fed back to update the world prediction, so that both are recursively refined during inference. Rather than eliminating test-time world evolution altogether or rolling out the full future in pixel space, DAWN performs a short explicit latent rollout that is sufficient to support long-horizon trajectory generation in complex interactive scenes. Experiments show that DAWN achieves strong planning performance and favorable safety-related results across multiple autonomous driving benchmarks. More broadly, our results suggest that interactive world-action generation is a principled path toward truly actionable world models.
Clinical Cognition Alignment for Gastrointestinal Diagnosis with Multimodal LLMs
Mar 21, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable potential in medical image analysis. However, their application in gastrointestinal endoscopy is currently hindered by two critical limitations: the misalignment between general model reasoning and standardized clinical cognitive pathways, and the lack of causal association between visual features and diagnostic outcomes. In this paper, we propose a novel Clinical-Cognitive-Aligned (CogAlign) framework to address these challenges. First, we endow the model with rigorous clinical analytical capabilities by constructing the hierarchical clinical cognition dataset and employing Supervised Fine-Tuning (SFT). Unlike conventional approaches, this strategy internalizes the hierarchical diagnostic logic of experts, ranging from anatomical localization and morphological evaluation to microvascular analysis, directly into the model. Second, to eliminate visual bias, we provide a theoretical analysis demonstrating that standard supervised tuning inevitably converges to spurious background correlations. Guided by this insight, we propose a counterfactual-driven reinforcement learning strategy to enforce causal rectification. By generating counterfactual normal samples via lesion masking and optimizing through clinical-cognition-centric rewards, we constrain the model to strictly ground its diagnosis in causal lesion features. Extensive experiments demonstrate that our approach achieves State-of-the-Art (SoTA) performance across multiple benchmarks, significantly enhancing diagnostic accuracy in complex clinical scenarios. All source code and datasets will be made publicly available.
VisionNVS: Self-Supervised Inpainting for Novel View Synthesis under the Virtual-Shift Paradigm
Mar 18, 2026A fundamental bottleneck in Novel View Synthesis (NVS) for autonomous driving is the inherent supervision gap on novel trajectories: models are tasked with synthesizing unseen views during inference, yet lack ground truth images for these shifted poses during training. In this paper, we propose VisionNVS, a camera-only framework that fundamentally reformulates view synthesis from an ill-posed extrapolation problem into a self-supervised inpainting task. By introducing a ``Virtual-Shift'' strategy, we use monocular depth proxies to simulate occlusion patterns and map them onto the original view. This paradigm shift allows the use of raw, recorded images as pixel-perfect supervision, effectively eliminating the domain gap inherent in previous approaches. Furthermore, we address spatial consistency through a Pseudo-3D Seam Synthesis strategy, which integrates visual data from adjacent cameras during training to explicitly model real-world photometric discrepancies and calibration errors. Experiments demonstrate that VisionNVS achieves superior geometric fidelity and visual quality compared to LiDAR-dependent baselines, offering a robust solution for scalable driving simulation.
DeepRMSA: A Deep Reinforcement Learning Framework for Routing, Modulation and Spectrum Assignment in Elastic Optical Networks
May 15, 2019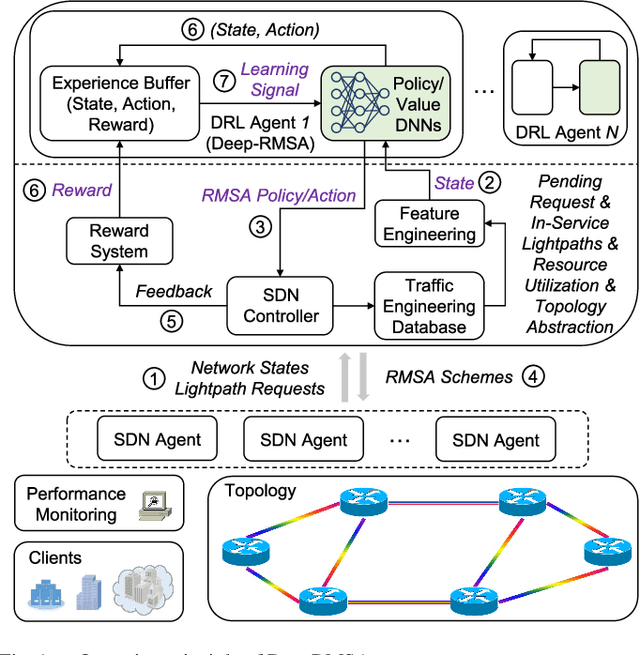
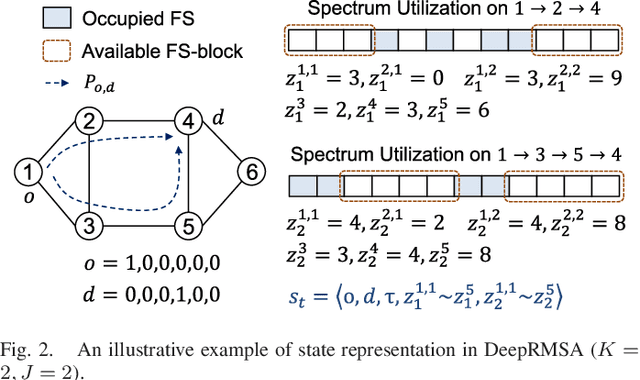
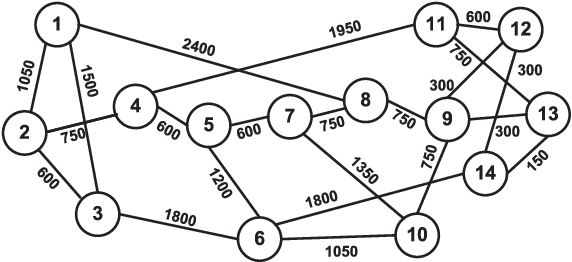
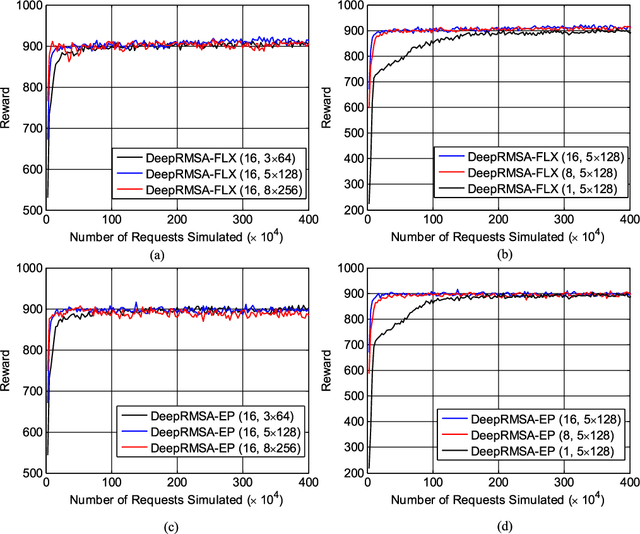
This paper proposes DeepRMSA, a deep reinforcement learning framework for routing, modulation and spectrum assignment (RMSA) in elastic optical networks (EONs). DeepRMSA learns the correct online RMSA policies by parameterizing the policies with deep neural networks (DNNs) that can sense complex EON states. The DNNs are trained with experiences of dynamic lightpath provisioning. We first modify the asynchronous advantage actor-critic algorithm and present an episode-based training mechanism for DeepRMSA, namely, DeepRMSA-EP. DeepRMSA-EP divides the dynamic provisioning process into multiple episodes (each containing the servicing of a fixed number of lightpath requests) and performs training by the end of each episode. The optimization target of DeepRMSA-EP at each step of servicing a request is to maximize the cumulative reward within the rest of the episode. Thus, we obviate the need for estimating the rewards related to unknown future states. To overcome the instability issue in the training of DeepRMSA-EP due to the oscillations of cumulative rewards, we further propose a window-based flexible training mechanism, i.e., DeepRMSA-FLX. DeepRMSA-FLX attempts to smooth out the oscillations by defining the optimization scope at each step as a sliding window, and ensuring that the cumulative rewards always include rewards from a fixed number of requests. Evaluations with the two sample topologies show that DeepRMSA-FLX can effectively stabilize the training while achieving blocking probability reductions of more than 20.3% and 14.3%, when compared with the baselines.