 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-shot Neural Machine Translation on Language-specific Encoders-Decoders
Feb 12, 2021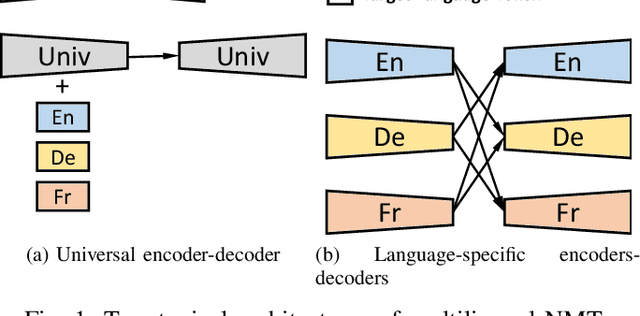
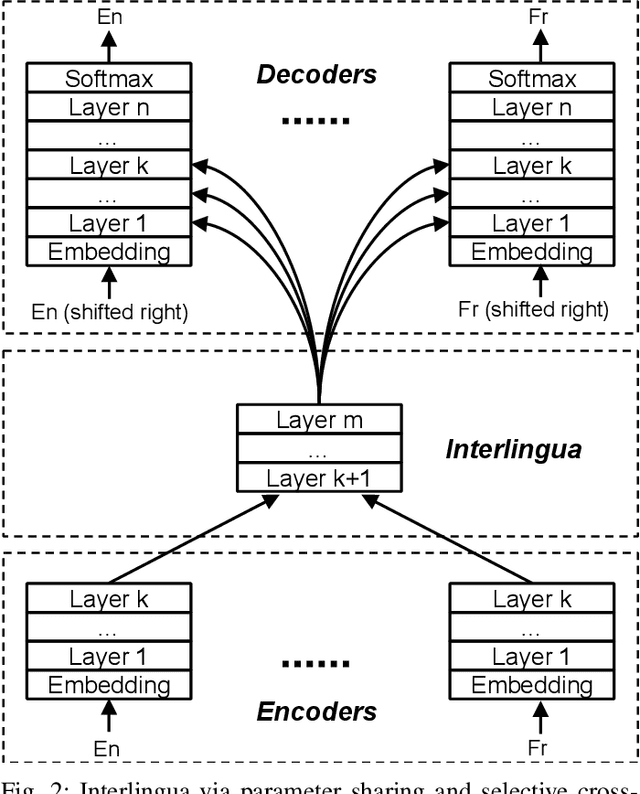

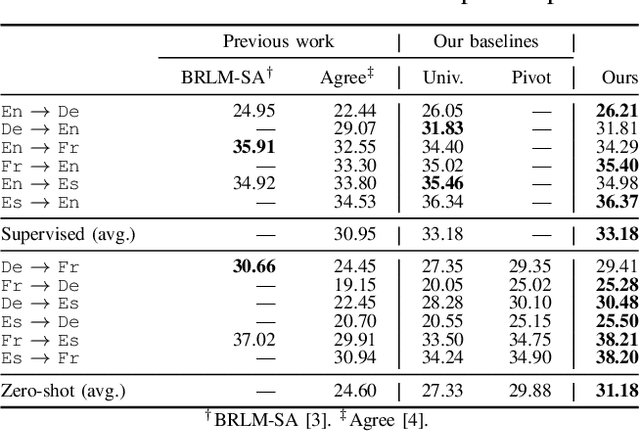
Recently, universal neural machine translation (NMT) with shared encoder-decoder gained good performance on zero-shot translation. Unlike universal NMT, jointly trained language-specific encoders-decoders aim to achieve universal representation across non-shared modules, each of which is for a language or language family. The non-shared architecture has the advantage of mitigating internal language competition, especially when the shared vocabulary and model parameters are restricted in their size. However, the performance of using multiple encoders and decoders on zero-shot translation still lags behind universal NMT. In this work, we study zero-shot translation using language-specific encoders-decoders. We propose to generalize the non-shared architecture and universal NMT by differentiating the Transformer layers between language-specific and interlingua. By selectively sharing parameters and applying cross-attentions, we explore maximizing the representation universality and realizing the best alignment of language-agnostic information. We also introduce a denoising auto-encoding (DAE) objective to jointly train the model with the translation task in a multi-task manner. Experiments on two public multilingual parallel datasets show that our proposed model achieves a competitive or better results than universal NMT and strong pivot baseline. Moreover, we experiment incrementally adding new language to the trained model by only updating the new model parameters. With this little effort, the zero-shot translation between this newly added language and existing languages achieves a comparable result with the model trained jointly from scratch on all languages.
Macroscopic Control of Text Generation for Image Captioning
Jan 20, 2021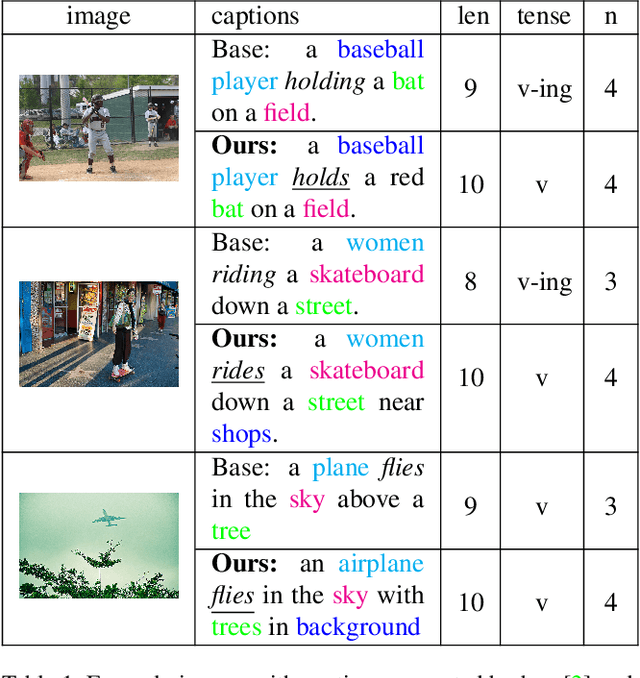
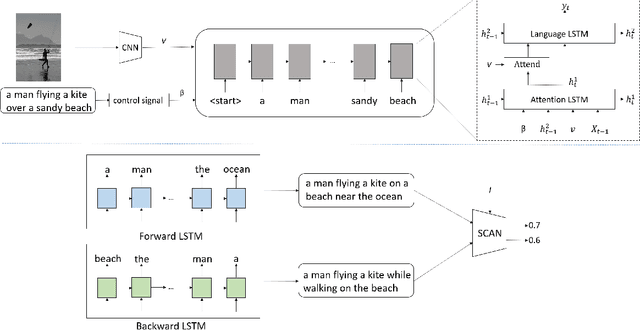

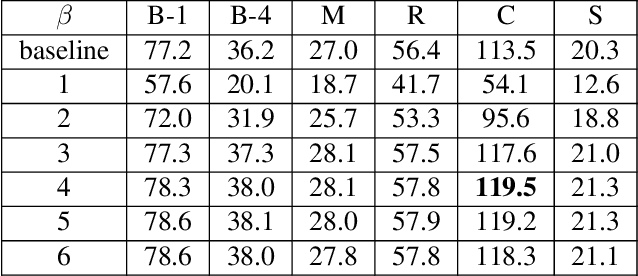
Despite the fact that image captioning models have been able to generate impressive descriptions for a given image, challenges remain: (1) the controllability and diversity of existing models are still far from satisfactory; (2) models sometimes may produce extremely poor-quality captions. In this paper, two novel methods are introduced to solve the problems respectively. Specifically, for the former problem, we introduce a control signal which can control the macroscopic sentence attributes, such as sentence quality, sentence length, sentence tense and number of nouns etc. With such a control signal, the controllability and diversity of existing captioning models are enhanced. For the latter problem, we innovatively propose a strategy that an image-text matching model is trained to measure the quality of sentences generated in both forward and backward directions and finally choose the better one. As a result, this strategy can effectively reduce the proportion of poorquality sentences. Our proposed methods can be easily applie on most image captioning models to improve their overall performance. Based on the Up-Down model, the experimental results show that our methods achieve BLEU- 4/CIDEr/SPICE scores of 37.5/120.3/21.5 on MSCOCO Karpathy test split with cross-entropy training, which surpass the results of other state-of-the-art methods trained by cross-entropy loss.
KINNEWS and KIRNEWS: Benchmarking Cross-Lingual Text Classification for Kinyarwanda and Kirundi
Oct 23, 2020
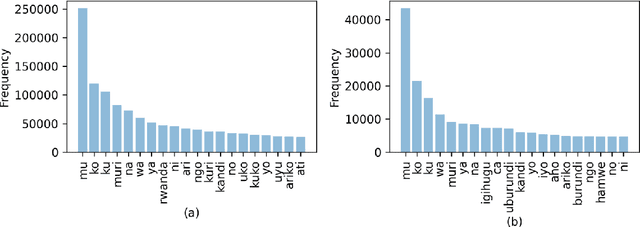

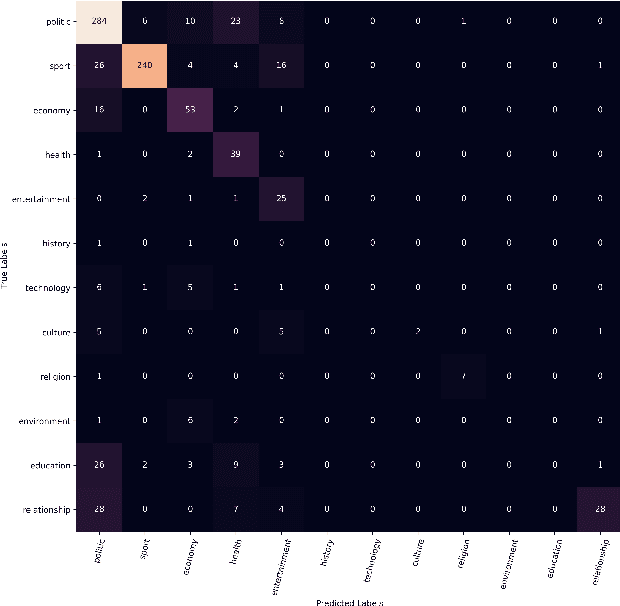
Recent progress in text classification has been focused on high-resource languages such as English and Chinese. For low-resource languages, amongst them most African languages, the lack of well-annotated data and effective preprocessing, is hindering the progress and the transfer of successful methods. In this paper, we introduce two news datasets (KINNEWS and KIRNEWS) for multi-class classification of news articles in Kinyarwanda and Kirundi, two low-resource African languages. The two languages are mutually intelligible, but while Kinyarwanda has been studied in Natural Language Processing (NLP) to some extent, this work constitutes the first study on Kirundi. Along with the datasets, we provide statistics, guidelines for preprocessing, and monolingual and cross-lingual baseline models. Our experiments show that training embeddings on the relatively higher-resourced Kinyarwanda yields successful cross-lingual transfer to Kirundi. In addition, the design of the created datasets allows for a wider use in NLP beyond text classification in future studies, such as representation learning, cross-lingual learning with more distant languages, or as base for new annotations for tasks such as parsing, POS tagging, and NER. The datasets, stopwords, and pre-trained embeddings are publicly available at https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus .
Improving Readability for Automatic Speech Recognition Transcription
Apr 09, 2020
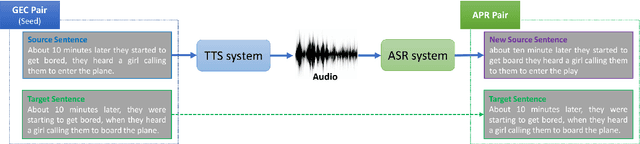
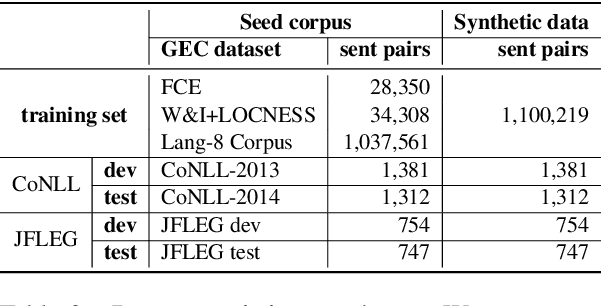
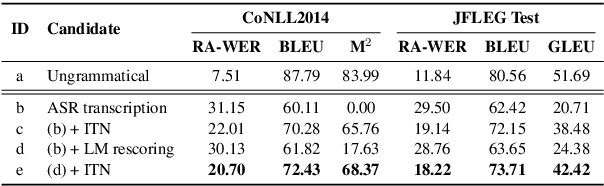
Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to grammatical errors, disfluency, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose a novel NLP task called ASR post-processing for readability (APR) that aims to transform the noisy ASR output into a readable text for humans and downstream tasks while maintaining the semantic meaning of the speaker. In addition, we describe a method to address the lack of task-specific data by synthesizing examples for the APR task using the datasets collected for Grammatical Error Correction (GEC) followed by text-to-speech (TTS) and ASR. Furthermore, we propose metrics borrowed from similar tasks to evaluate performance on the APR task. We compare fine-tuned models based on several open-sourced and adapted pre-trained models with the traditional pipeline method. Our results suggest that finetuned models improve the performance on the APR task significantly, hinting at the potential benefits of using APR systems. We hope that the read, understand, and rewrite approach of our work can serve as a basis that many NLP tasks and human readers can benefit from.
Spike-Timing-Dependent Back Propagation in Deep Spiking Neural Networks
Mar 26, 2020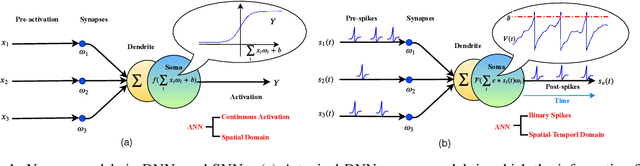



The success of Deep Neural Networks (DNNs) can be attributed to its deep structure, that learns invariant feature representation at multiple levels of abstraction. Brain-inspired Spiking Neural Networks (SNNs) use spatiotemporal spike patterns to encode and transmit information, which is biologically realistic, and suitable for ultra-low-power event-driven neuromorphic implementation. Therefore, Deep Spiking Neural Networks (DSNNs) represent a promising direction in artificial intelligence, with the potential to benefit from the best of both worlds. However, the training of DSNNs is challenging because standard error back-propagation (BP) algorithms are not directly applicable. In this paper, we first establish an understanding of why error back-propagation does not work well in DSNNs. To address this problem, we propose a simple yet efficient Rectified Linear Postsynaptic Potential function (ReL-PSP) for spiking neurons and propose a Spike-Timing-Dependent Back-Propagation (STDBP) learning algorithm for DSNNs. In the proposed learning algorithm, the timing of individual spikes is used to carry information (temporal coding), and learning (back-propagation) is performed based on spike timing in an event-driven manner. Experimental results demonstrate that the proposed learning algorithm achieves state-of-the-art performance in spike time based learning algorithms of SNNs. This work investigates the contribution of dynamics in spike timing to information encoding, synaptic plasticity and decision making, providing a new perspective to design of future DSNNs.