 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-GradSpeech: Towards Diffusion-based Multi-Speaker Text-to-speech Using Consistent Diffusion Models
Aug 31, 2023

Despite imperfect score-matching causing drift in training and sampling distributions of diffusion models, recent advances in diffusion-based acoustic models have revolutionized data-sufficient single-speaker Text-to-Speech (TTS) approaches, with Grad-TTS being a prime example. However, the sampling drift problem leads to these approaches struggling in multi-speaker scenarios in practice due to more complex target data distribution compared to single-speaker scenarios. In this paper, we present Multi-GradSpeech, a multi-speaker diffusion-based acoustic models which introduces the Consistent Diffusion Model (CDM) as a generative modeling approach. We enforce the consistency property of CDM during the training process to alleviate the sampling drift problem in the inference stage, resulting in significant improvements in multi-speaker TTS performance. Our experimental results corroborate that our proposed approach can improve the performance of different speakers involved in multi-speaker TTS compared to Grad-TTS, even outperforming the fine-tuning approach. Audio samples are available at https://welkinyang.github.io/multi-gradspeech/
VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
Nov 05, 2022



End-to-end singing voice synthesis (SVS) model VISinger can achieve better performance than the typical two-stage model with fewer parameters. However, VISinger has several problems: text-to-phase problem, the end-to-end model learns the meaningless mapping of text-to-phase; glitches problem, the harmonic components corresponding to the periodic signal of the voiced segment occurs a sudden change with audible artefacts; low sampling rate, the sampling rate of 24KHz does not meet the application needs of high-fidelity generation with the full-band rate (44.1KHz or higher). In this paper, we propose VISinger 2 to address these issues by integrating the digital signal processing (DSP) methods with VISinger. Specifically, inspired by recent advances in differentiable digital signal processing (DDSP), we incorporate a DSP synthesizer into the decoder to solve the above issues. The DSP synthesizer consists of a harmonic synthesizer and a noise synthesizer to generate periodic and aperiodic signals, respectively, from the latent representation z in VISinger. It supervises the posterior encoder to extract the latent representation without phase information and avoid the prior encoder modelling text-to-phase mapping. To avoid glitch artefacts, the HiFi-GAN is modified to accept the waveforms generated by the DSP synthesizer as a condition to produce the singing voice. Moreover, with the improved waveform decoder, VISinger 2 manages to generate 44.1kHz singing audio with richer expression and better quality. Experiments on OpenCpop corpus show that VISinger 2 outperforms VISinger, CpopSing and RefineSinger in both subjective and objective metrics.
AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation
Jun 01, 2022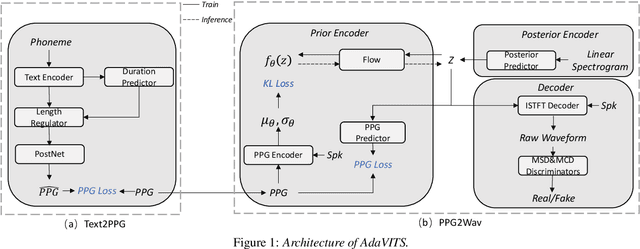

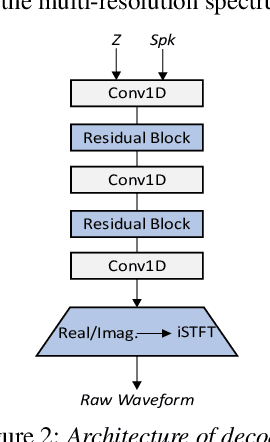
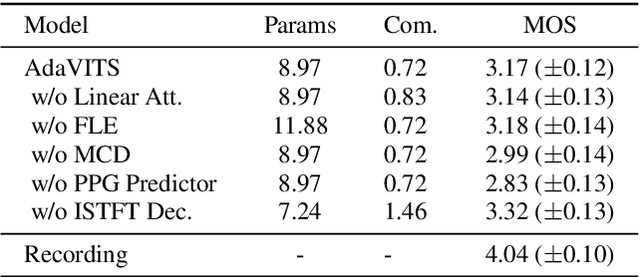
Speaker adaptation in text-to-speech synthesis (TTS) is to finetune a pre-trained TTS model to adapt to new target speakers with limited data. While much effort has been conducted towards this task, seldom work has been performed for low computational resource scenarios due to the challenges raised by the requirement of the lightweight model and less computational complexity. In this paper, a tiny VITS-based TTS model, named AdaVITS, for low computing resource speaker adaptation is proposed. To effectively reduce parameters and computational complexity of VITS, an iSTFT-based wave construction decoder is proposed to replace the upsampling-based decoder which is resource-consuming in the original VITS. Besides, NanoFlow is introduced to share the density estimate across flow blocks to reduce the parameters of the prior encoder. Furthermore, to reduce the computational complexity of the textual encoder, scaled-dot attention is replaced with linear attention. To deal with the instability caused by the simplified model, instead of using the original text encoder, phonetic posteriorgram (PPG) is utilized as linguistic feature via a text-to-PPG module, which is then used as input for the encoder. Experiment shows that AdaVITS can generate stable and natural speech in speaker adaptation with 8.97M model parameters and 0.72GFlops computational complexity.
Learn2Sing 2.0: Diffusion and Mutual Information-Based Target Speaker SVS by Learning from Singing Teacher
Mar 30, 2022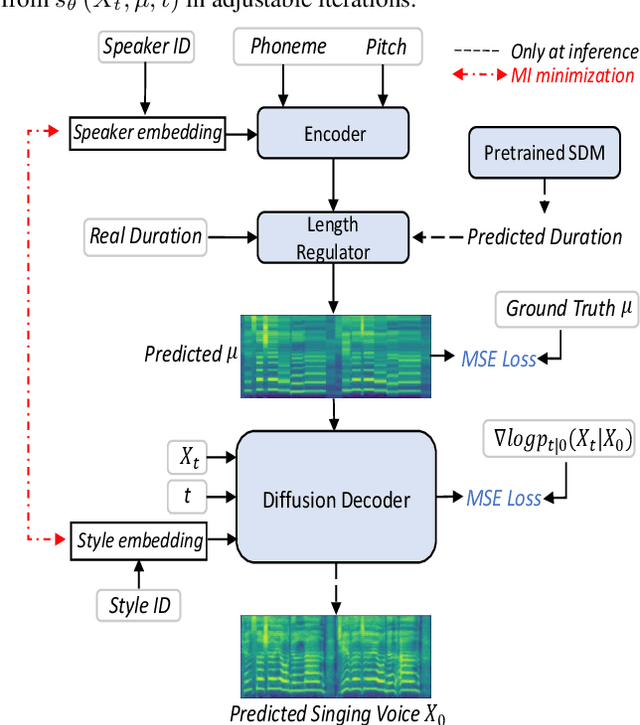
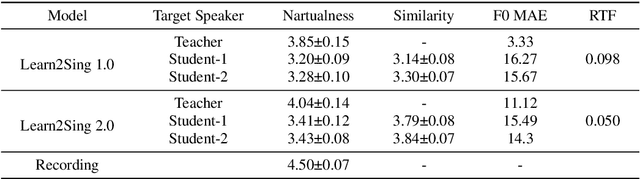
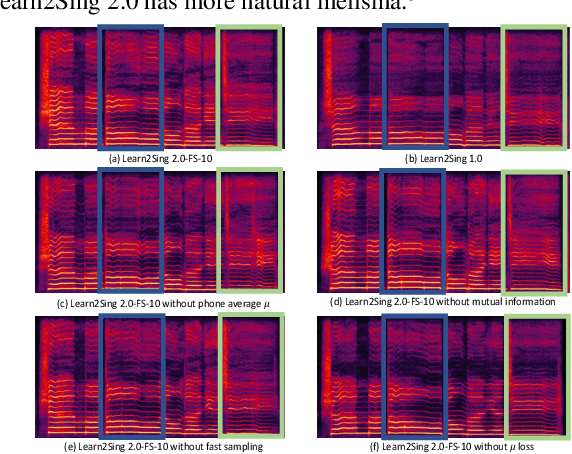
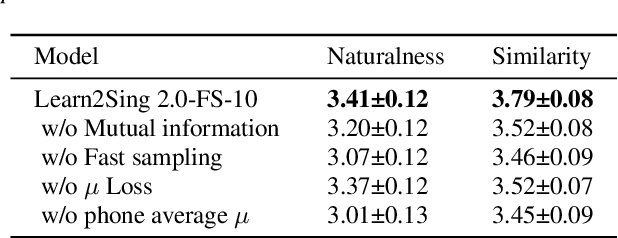
Building a high-quality singing corpus for a person who is not good at singing is non-trivial, thus making it challenging to create a singing voice synthesizer for this person. Learn2Sing is dedicated to synthesizing the singing voice of a speaker without his or her singing data by learning from data recorded by others, i.e., the singing teacher. Inspired by the fact that pitch is the key style factor to distinguish singing from speaking voice, the proposed Learn2Sing 2.0 first generates the preliminary acoustic feature with averaged pitch value in the phone level, which allows the training of this process for different styles, i.e., speaking or singing, share same conditions except for the speaker information. Then, conditioned on the specific style, a diffusion decoder, which is accelerated by a fast sampling algorithm during the inference stage, is adopted to gradually restore the final acoustic feature. During the training, to avoid the information confusion of the speaker embedding and the style embedding, mutual information is employed to restrain the learning of speaker embedding and style embedding. Experiments show that the proposed approach is capable of synthesizing high-quality singing voice for the target speaker without singing data with 10 decoding steps.
Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis
Jan 20, 2022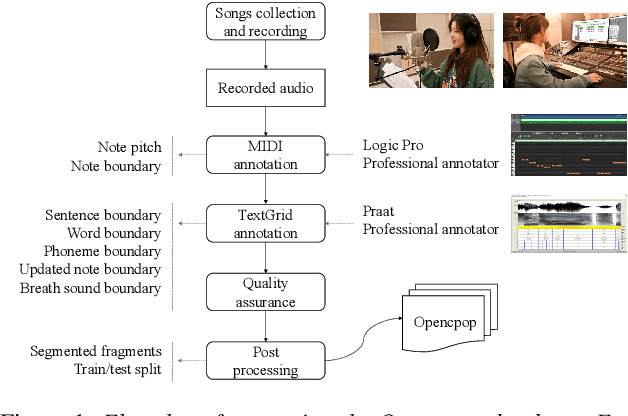
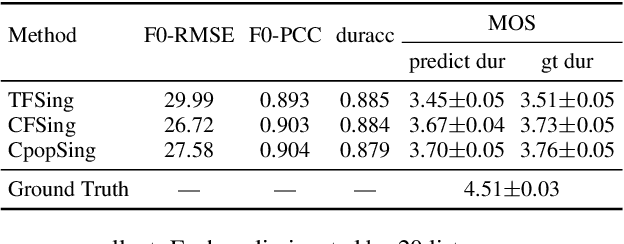


This paper introduces Opencpop, a publicly available high-quality Mandarin singing corpus designed for singing voice synthesis (SVS). The corpus consists of 100 popular Mandarin songs performed by a female professional singer. Audio files are recorded with studio quality at a sampling rate of 44,100 Hz and the corresponding lyrics and musical scores are provided. All singing recordings have been phonetically annotated with phoneme boundaries and syllable (note) boundaries. To demonstrate the reliability of the released data and to provide a baseline for future research, we built baseline deep neural network-based SVS models and evaluated them with both objective metrics and subjective mean opinion score (MOS) measure. Experimental results show that the best SVS model trained on our database achieves 3.70 MOS, indicating the reliability of the provided corpus. Opencpop is released to the open-source community WeNet, and the corpus, as well as synthesized demos, can be found on the project homepage.
VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis
Oct 17, 2021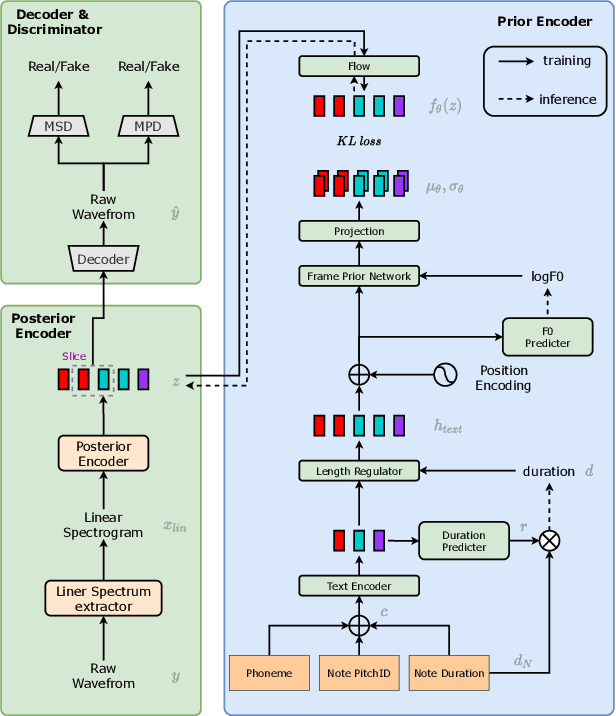
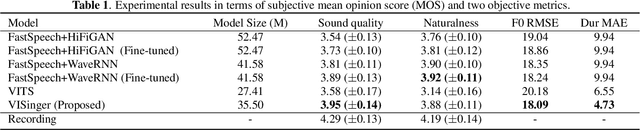
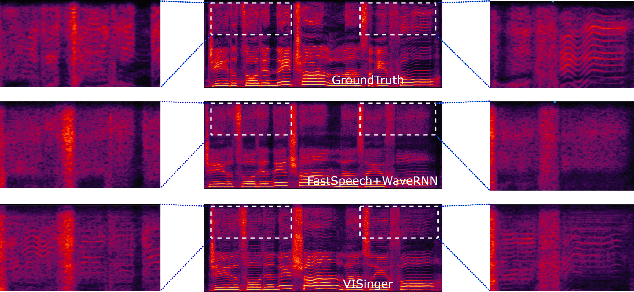
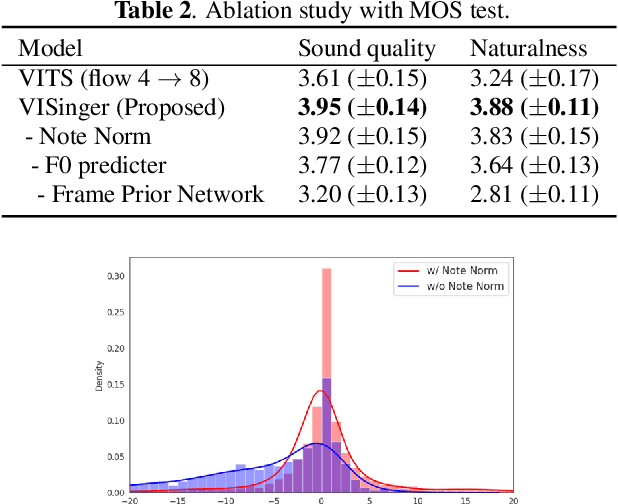
In this paper, we propose VISinger, a complete end-to-end high-quality singing voice synthesis (SVS) system that directly generates audio waveform from lyrics and musical score. Our approach is inspired by VITS, which adopts VAE-based posterior encoder augmented with normalizing flow-based prior encoder and adversarial decoder to realize complete end-to-end speech generation. VISinger follows the main architecture of VITS, but makes substantial improvements to the prior encoder based on the characteristics of singing. First, instead of using phoneme-level mean and variance of acoustic features, we introduce a length regulator and a frame prior network to get the frame-level mean and variance on acoustic features, modeling the rich acoustic variation in singing. Second, we further introduce an F0 predictor to guide the frame prior network, leading to stabler singing performance. Finally, to improve the singing rhythm, we modify the duration predictor to specifically predict the phoneme to note duration ratio, helped with singing note normalization. Experiments on a professional Mandarin singing corpus show that VISinger significantly outperforms FastSpeech+Neural-Vocoder two-stage approach and the oracle VITS; ablation study demonstrates the effectiveness of different contributions.