 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Self-Supervised Representation Learning for Speaker Diarization and Separation
Dec 17, 2025



Self-supervised speech models such as wav2vec2.0 and WavLM have been shown to significantly improve the performance of many downstream speech tasks, especially in low-resource settings, over the past few years. Despite this, evaluations on tasks such as Speaker Diarization and Speech Separation remain limited. This paper investigates the quality of recent self-supervised speech representations on these two speaker identity-related tasks, highlighting gaps in the current literature that stem from limitations in the existing benchmarks, particularly the lack of diversity in evaluation datasets and variety in downstream systems associated to both diarization and separation.
Physeter catodon localization by sparse coding
Jun 13, 2013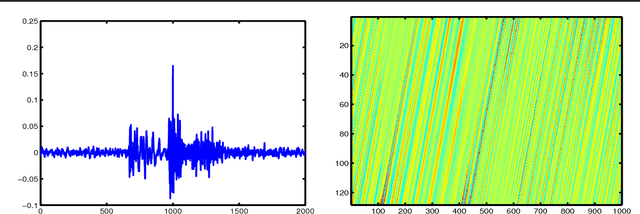
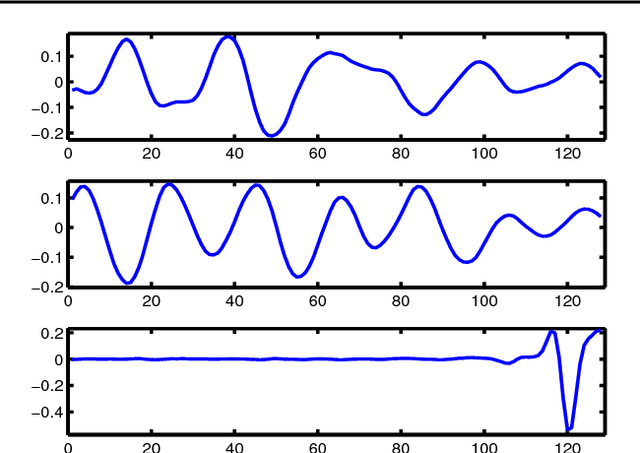
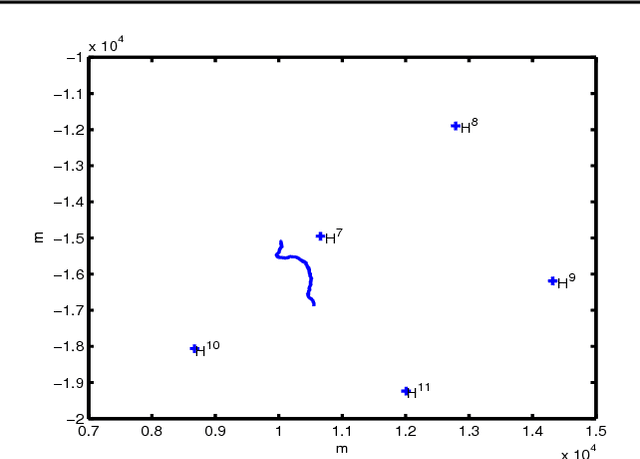
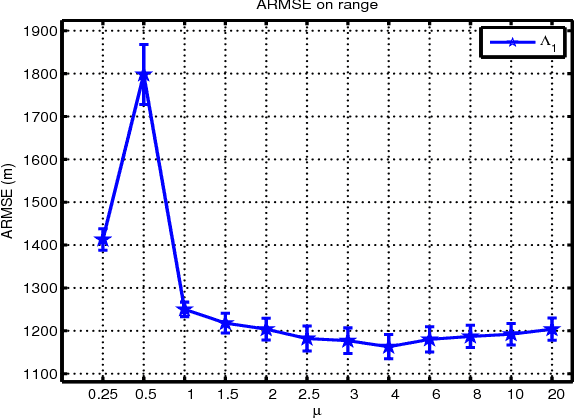
This paper presents a spermwhale' localization architecture using jointly a bag-of-features (BoF) approach and machine learning framework. BoF methods are known, especially in computer vision, to produce from a collection of local features a global representation invariant to principal signal transformations. Our idea is to regress supervisely from these local features two rough estimates of the distance and azimuth thanks to some datasets where both acoustic events and ground-truth position are now available. Furthermore, these estimates can feed a particle filter system in order to obtain a precise spermwhale' position even in mono-hydrophone configuration. Anti-collision system and whale watching are considered applications of this work.