 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sober Look at Agentic Misalignment in Automated Workflows
May 22, 2026We study a class of emergent misalignment in multi-agent systems (MAS), with a focus on automated workflows, which we refer to agentic misalignment. Although these systems can solve complex tasks, they often fail because agents act according to implicit proxy utilities that do not align with the intended human goals. We formally define these behaviors and analyze them within a Bayesian framework, showing that generic utilities naturally lead to posterior collapse of agents in automated workflows. To address this issue, we propose Agentic Evidence Attribution (AEA), a novel alignment paradigm that improves agent posteriors using context-specific evidence. AEA reasons over agent actions and provides structured evidence to correct misaligned behavior during collaboration. To better understand the role of evidence, we study two instantiations of AEA: self-reflection (internal evidence from the model) and weak-to-strong generalization (external evidence on the agentic trajectory). We show that a small evidence model effectively aligns the MAS by providing orthogonal failure attribution. Our results clarify the sources of agentic misalignment in automated workflows and show that evidence-based alignment can effectively improve agent collaboration and leads to reliable multi-agent systems built on automated workflows.
Hiding in Plain Sight: Finding MAHA on Reddit
May 19, 2026Make America Healthy Again (MAHA) is a national health movement that encompasses a striking mix of beliefs, from broadly accepted concerns about good diet and exercise to controversial takes on organic and genetically modified food, childhood vaccination, science, and institutions. Various influencers and promoters of the MAHA movement on social media are scattered throughout the online space. Investigating the structure, discourse, and contagion of MAHA beliefs requires large-scale fine-grained digital footprints. Constructing structured data covering different MAHA themes from vast unstructured social media data is challenging. We introduce a Reddit dataset that spans six years (2020-2025), comprising 19.4M posts from 4M users. Containing the natural and thematic context of 12 MAHA-aligned beliefs, this dataset offers researchers from various domains the opportunity to study the dynamics of the MAHA movement, its structural and functional components, and the linguistic and behavioral patterns of its proponents.
Detecting Individuals with Depressive Disorder fromPersonal Google Search and YouTube History Logs
Oct 28, 2020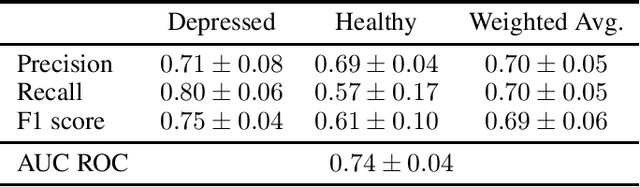
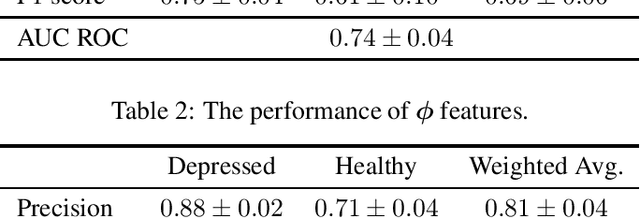
Depressive disorder is one of the most prevalent mental illnesses among the global population. However, traditional screening methods require exacting in-person interviews and may fail to provide immediate interventions. In this work, we leverage ubiquitous personal longitudinal Google Search and YouTube engagement logs to detect individuals with depressive disorder. We collected Google Search and YouTube history data and clinical depression evaluation results from $212$ participants ($99$ of them suffered from moderate to severe depressions). We then propose a personalized framework for classifying individuals with and without depression symptoms based on mutual-exciting point process that captures both the temporal and semantic aspects of online activities. Our best model achieved an average F1 score of $0.77 \pm 0.04$ and an AUC ROC of $0.81 \pm 0.02$.
SemEval-2020 Task 7: Assessing Humor in Edited News Headlines
Aug 01, 2020


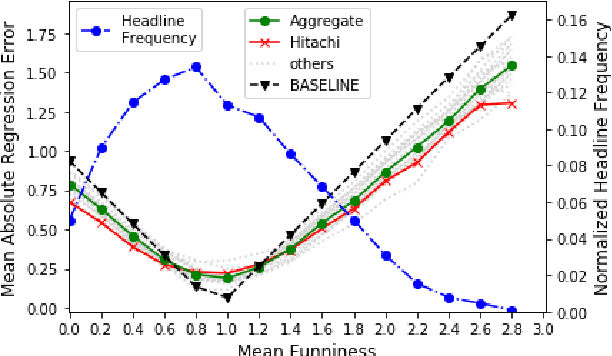
This paper describes the SemEval-2020 shared task "Assessing Humor in Edited News Headlines." The task's dataset contains news headlines in which short edits were applied to make them funny, and the funniness of these edited headlines was rated using crowdsourcing. This task includes two subtasks, the first of which is to estimate the funniness of headlines on a humor scale in the interval 0-3. The second subtask is to predict, for a pair of edited versions of the same original headline, which is the funnier version. To date, this task is the most popular shared computational humor task, attracting 48 teams for the first subtask and 31 teams for the second.
Explaining Local, Global, And Higher-Order Interactions In Deep Learning
Jun 12, 2020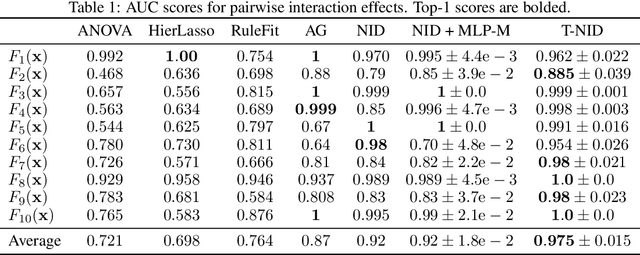
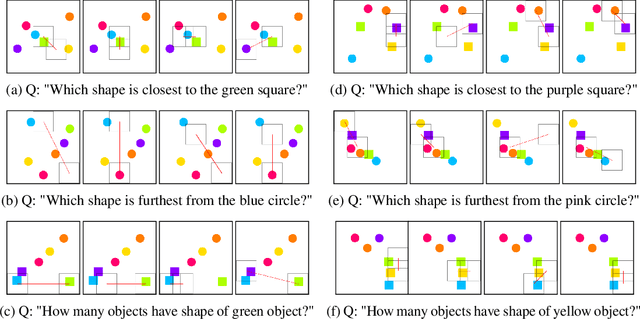
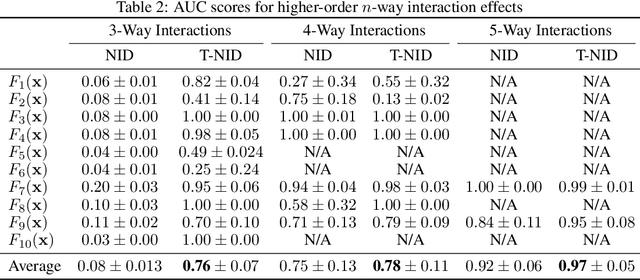
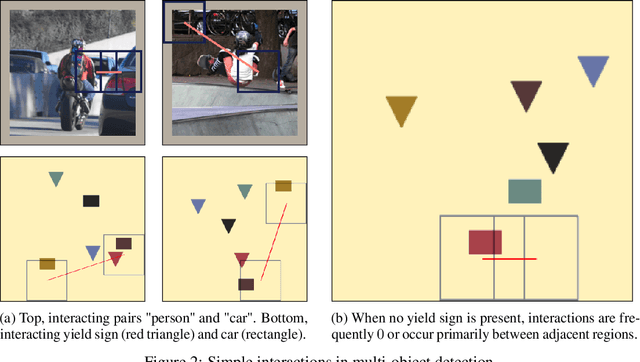
We present a simple yet highly generalizable method for explaining interacting parts within a neural network's reasoning process. In this work, we consider local, global, and higher-order statistical interactions. Generally speaking, local interactions occur between features within individual datapoints, while global interactions come in the form of universal features across the whole dataset. With deep learning, combined with some heuristics for tractability, we achieve state of the art measurement of global statistical interaction effects, including at higher orders (3-way interactions or more). We generalize this to the multidimensional setting to explain local interactions in multi-object detection and relational reasoning using the COCO annotated-image and Sort-Of-CLEVR toy datasets respectively. Here, we submit a new task for testing feature vector interactions, conduct a human study, propose a novel metric for relational reasoning, and use our interaction interpretations to innovate a more effective Relation Network. Finally, we apply these techniques on a real-world biomedical dataset to discover the higher-order interactions underlying Parkinson's disease clinical progression. Code for all experiments, fully reproducible, is available at: https://github.com/slerman12/ExplainingInteractions.
Stimulating Creativity with FunLines: A Case Study of Humor Generation in Headlines
Feb 05, 2020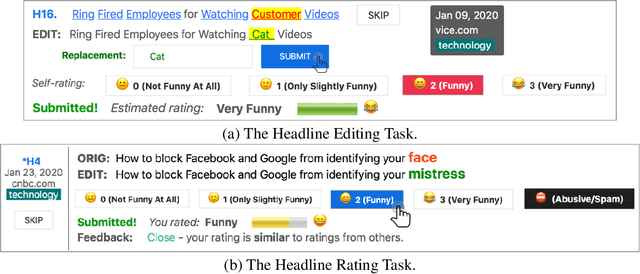

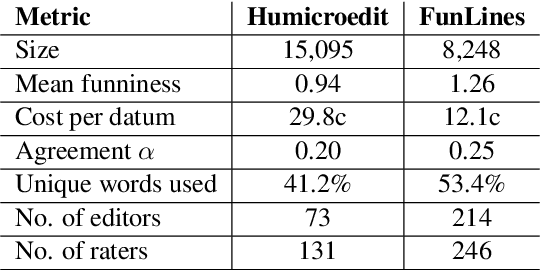

Building datasets of creative text, such as humor, is quite challenging. We introduce FunLines, a competitive game where players edit news headlines to make them funny, and where they rate the funniness of headlines edited by others. FunLines makes the humor generation process fun, interactive, collaborative, rewarding and educational, keeping players engaged and providing humor data at a very low cost compared to traditional crowdsourcing approaches. FunLines offers useful performance feedback, assisting players in getting better over time at generating and assessing humor, as our analysis shows. This helps to further increase the quality of the generated dataset. We show the effectiveness of this data by training humor classification models that outperform a previous benchmark, and we release this dataset to the public.
Predicting Acute Kidney Injury at Hospital Re-entry Using High-dimensional Electronic Health Record Data
Aug 13, 2018
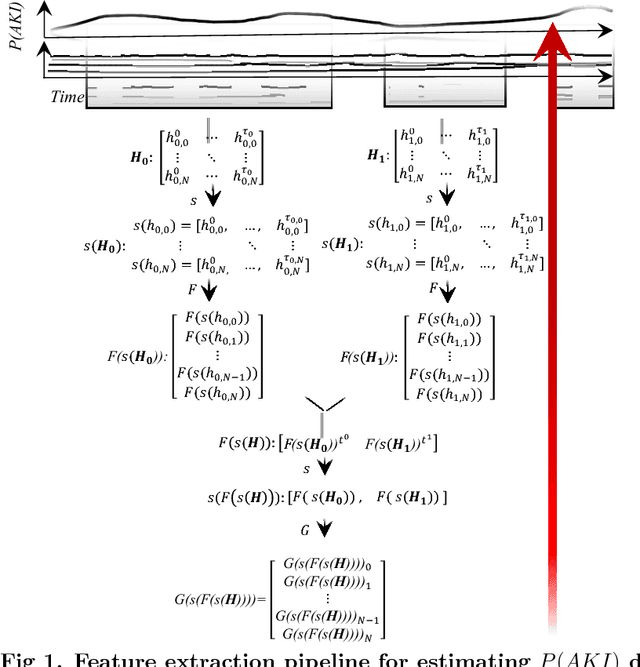
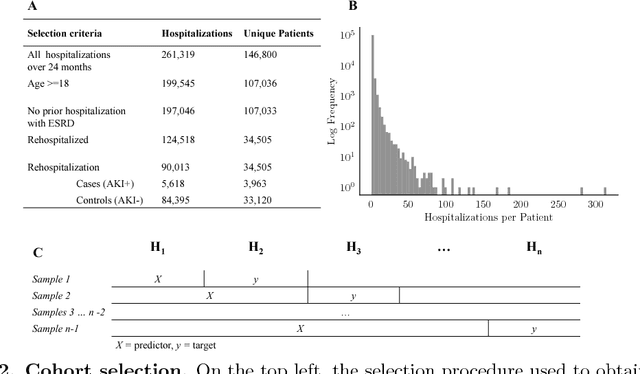
Acute Kidney Injury (AKI), a sudden decline in kidney function, is associated with increased mortality, morbidity, length of stay, and hospital cost. Since AKI is sometimes preventable, there is great interest in prediction. Most existing studies consider all patients and therefore restrict to features available in the first hours of hospitalization. Here, the focus is instead on rehospitalized patients, a cohort in which rich longitudinal features from prior hospitalizations can be analyzed. Our objective is to provide a risk score directly at hospital re-entry. Gradient boosting, penalized logistic regression (with and without stability selection), and a recurrent neural network are trained on two years of adult inpatient EHR data (3,387 attributes for 34,505 patients who generated 90,013 training samples with 5,618 cases and 84,395 controls). Predictions are internally evaluated with 50 iterations of 5-fold grouped cross-validation with special emphasis on calibration, an analysis of which is performed at the patient as well as hospitalization level. Error is assessed with respect to diagnosis, race, age, gender, AKI identification method, and hospital utilization. In an additional experiment, the regularization penalty is severely increased to induce parsimony and interpretability. Predictors identified for rehospitalized patients are also reported with a special analysis of medications that might be modifiable risk factors. Insights from this study might be used to construct a predictive tool for AKI in rehospitalized patients. An accurate estimate of AKI risk at hospital entry might serve as a prior for an admitting provider or another predictive algorithm.
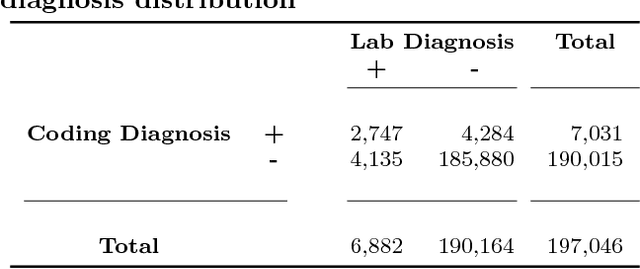
Inferring Fine-grained Details on User Activities and Home Location from Social Media: Detecting Drinking-While-Tweeting Patterns in Communities
Mar 10, 2016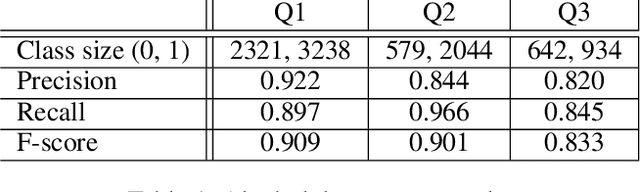
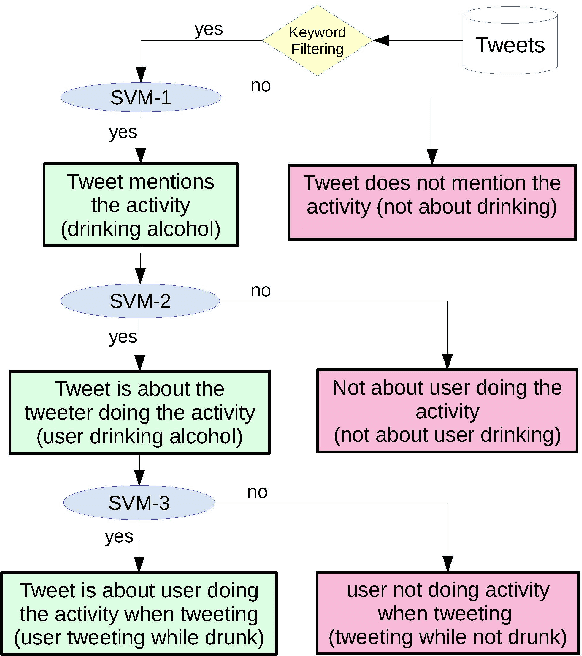
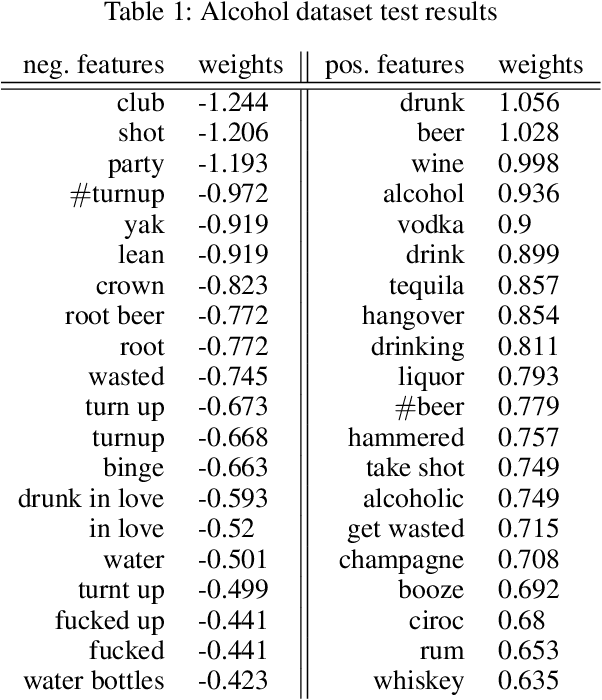
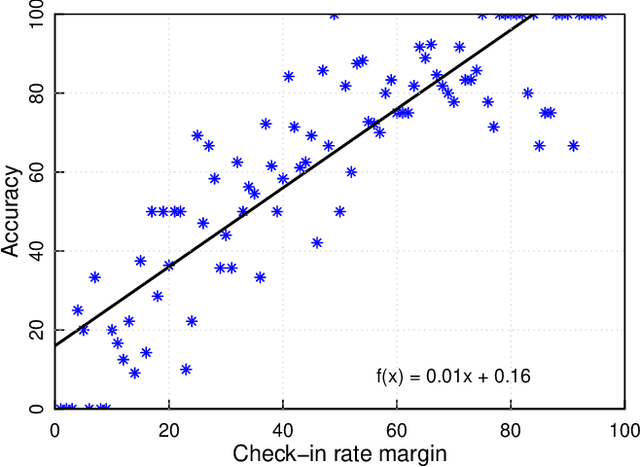
Nearly all previous work on geo-locating latent states and activities from social media confounds general discussions about activities, self-reports of users participating in those activities at times in the past or future, and self-reports made at the immediate time and place the activity occurs. Activities, such as alcohol consumption, may occur at different places and types of places, and it is important not only to detect the local regions where these activities occur, but also to analyze the degree of participation in them by local residents. In this paper, we develop new machine learning based methods for fine-grained localization of activities and home locations from Twitter data. We apply these methods to discover and compare alcohol consumption patterns in a large urban area, New York City, and a more suburban and rural area, Monroe County. We find positive correlations between the rate of alcohol consumption reported among a community's Twitter users and the density of alcohol outlets, demonstrating that the degree of correlation varies significantly between urban and suburban areas. While our experiments are focused on alcohol use, our methods for locating homes and distinguishing temporally-specific self-reports are applicable to a broad range of behaviors and latent states.
Location-Based Reasoning about Complex Multi-Agent Behavior
Jan 18, 2014
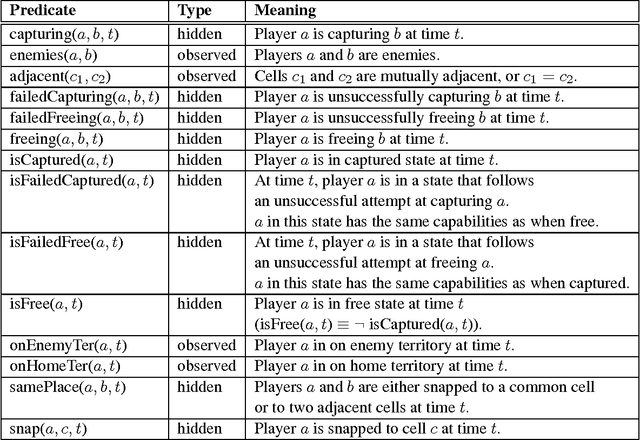
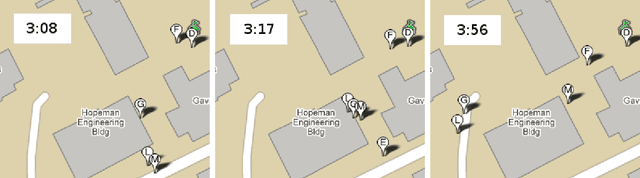

Recent research has shown that surprisingly rich models of human activity can be learned from GPS (positional) data. However, most effort to date has concentrated on modeling single individuals or statistical properties of groups of people. Moreover, prior work focused solely on modeling actual successful executions (and not failed or attempted executions) of the activities of interest. We, in contrast, take on the task of understanding human interactions, attempted interactions, and intentions from noisy sensor data in a fully relational multi-agent setting. We use a real-world game of capture the flag to illustrate our approach in a well-defined domain that involves many distinct cooperative and competitive joint activities. We model the domain using Markov logic, a statistical-relational language, and learn a theory that jointly denoises the data and infers occurrences of high-level activities, such as a player capturing an enemy. Our unified model combines constraints imposed by the geometry of the game area, the motion model of the players, and by the rules and dynamics of the game in a probabilistically and logically sound fashion. We show that while it may be impossible to directly detect a multi-agent activity due to sensor noise or malfunction, the occurrence of the activity can still be inferred by considering both its impact on the future behaviors of the people involved as well as the events that could have preceded it. Further, we show that given a model of successfully performed multi-agent activities, along with a set of examples of failed attempts at the same activities, our system automatically learns an augmented model that is capable of recognizing success and failure, as well as goals of peoples actions with high accuracy. We compare our approach with other alternatives and show that our unified model, which takes into account not only relationships among individual players, but also relationships among activities over the entire length of a game, although more computationally costly, is significantly more accurate. Finally, we demonstrate that explicitly modeling unsuccessful attempts boosts performance on other important recognition tasks.
A Bayesian Approach to Tackling Hard Computational Problems
Jan 10, 2013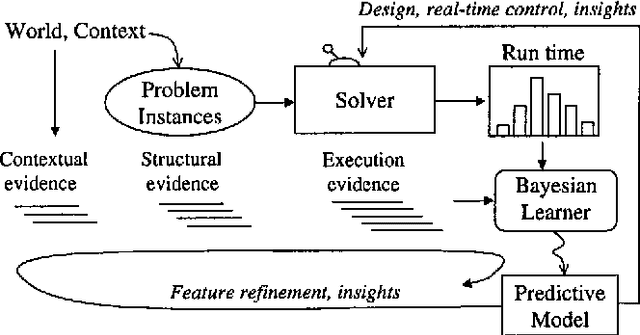

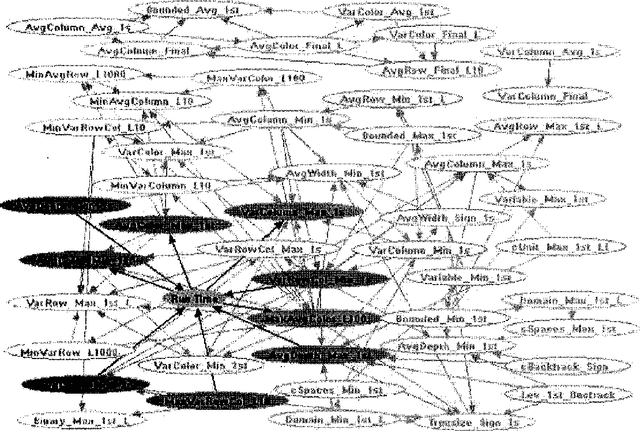
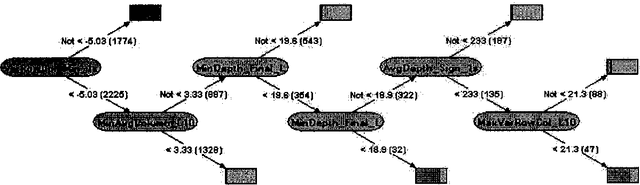
We are developing a general framework for using learned Bayesian models for decision-theoretic control of search and reasoningalgorithms. We illustrate the approach on the specific task of controlling both general and domain-specific solvers on a hard class of structured constraint satisfaction problems. A successful strategyfor reducing the high (and even infinite) variance in running time typically exhibited by backtracking search algorithms is to cut off and restart the search if a solution is not found within a certainamount of time. Previous work on restart strategies have employed fixed cut off values. We show how to create a dynamic cut off strategy by learning a Bayesian model that predicts the ultimate length of a trial based on observing the early behavior of the search algorithm. Furthermore, we describe the general conditions under which a dynamic restart strategy can outperform the theoretically optimal fixed strategy.